






这里假设我们的某个场景为:
用户进行答卷,我们需要根据用户的答卷内容给他标记为正向、负向、中性的词汇
每次人工标注就很麻烦,所以这里我们训练模型后,只需要将用户答卷内容丢给我们训练的模型,那么就能直接获取到用户的答卷内容属于哪种标签,之后可以做一些类似语义分析的大屏统计(后面会讲到如何进行语义分析)
我这里最开始用python试了下预训练Transformer模型,发现占用内存是真的高,感觉效率有点不尽人意
你们有兴趣的可以了解下python如何处理,其中model_name = "bert-base-chinese"
这个可以访问官网https://huggingface.co/下载到本地,这样会快一点,不过可能需要翻墙
进入官网后,首页输入框搜bert-base-chinese即可
python我研究的不深,你们自己了解就行,我也就做了个简单模型跑跑

后面选择使用ML.Net进行处理,效率快很多
与 Python 相比,ML.NET 在处理 Transformer 模型时可能会更快的原因可能有以下几点:
1、编程语言和运行时性能:
Python 是一种解释型语言,而 .NET 是一种编译型语言。通常情况下,编译型语言的执行速度比解释型语言更快。此外, .NET 运行时也可以进行即时编译(JIT Compilation),将代码编译成本地机器码,提高了执行效率。
2、并行处理和多线程:ML.NET 在处理 Transformer 模型时可以利用 .NET 平台的多线程和并行处理功能,将计算任务分配到多个处理器核心上并发执行,从而加快处理速度。
3、GPGPU 加速:
ML.NET 支持使用图形处理单元(GPU)进行加速。通过使用 CUDA 或其他 GPU 加速库,ML.NET 可以将部分计算任务委托给 GPU 来处理,并发利用 GPU 平行计算的能力,从而加快计算速度。
4、ML.NET 还针对 Transformer 模型进行了一些优化,例如采用了自定义的底层实现,精简了模型的层数和大小,使用量化技术减少模型的内存占用等,这些优化措施也可能会对执行速度产生积极影响。 需要注意的是,具体的性能差异还会受到多个因素的影响,包括具体的模型和数据集、硬件设备等。因此,在具体应用中,最好进行实际测试和性能优化来确定最佳的框架选择。
壁画不多说,直接撸起袖子开干
先新建一个控制台应用程序

右键解决放案,选择机器学习模型

选择ML.Net
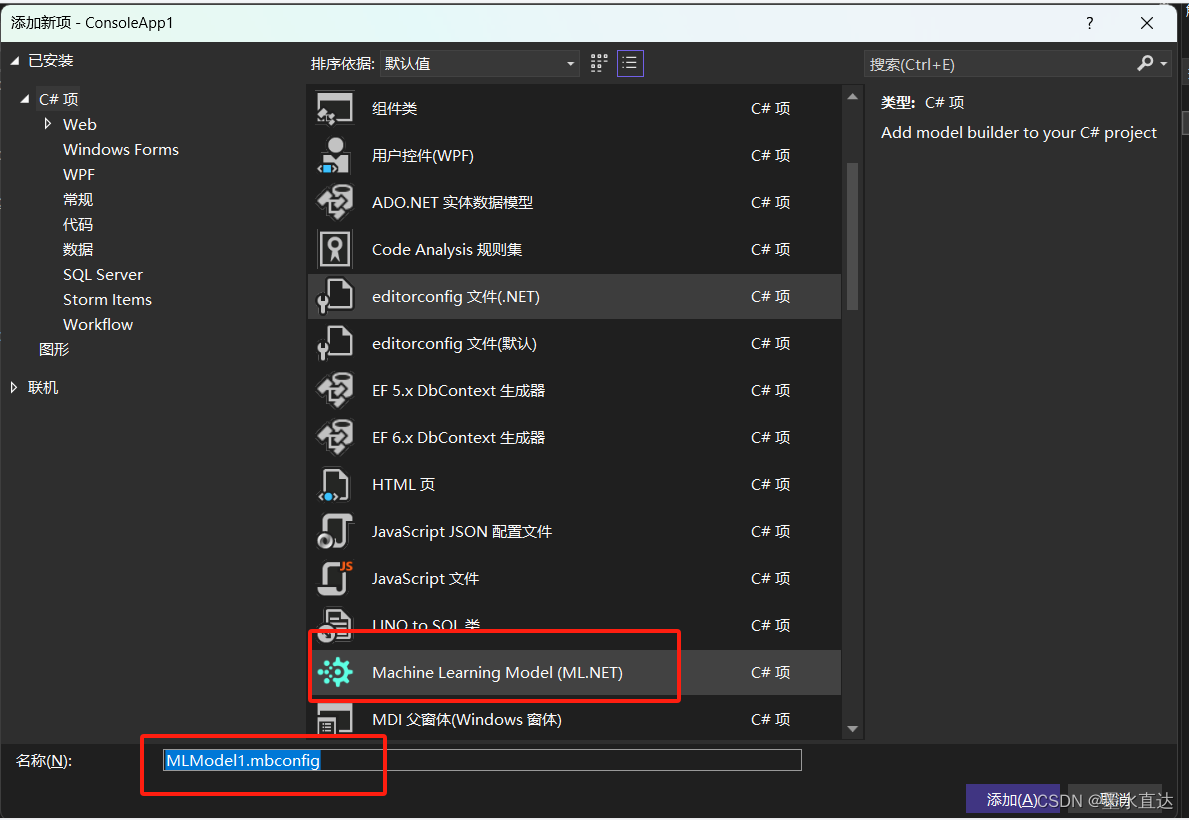
这里根据自己的目的,选择合适的训练放案,这里我选择第一个

选择本地

这里选择数据源类型,你们可以选择sqlserver,这里我用于演示,所以选择文件
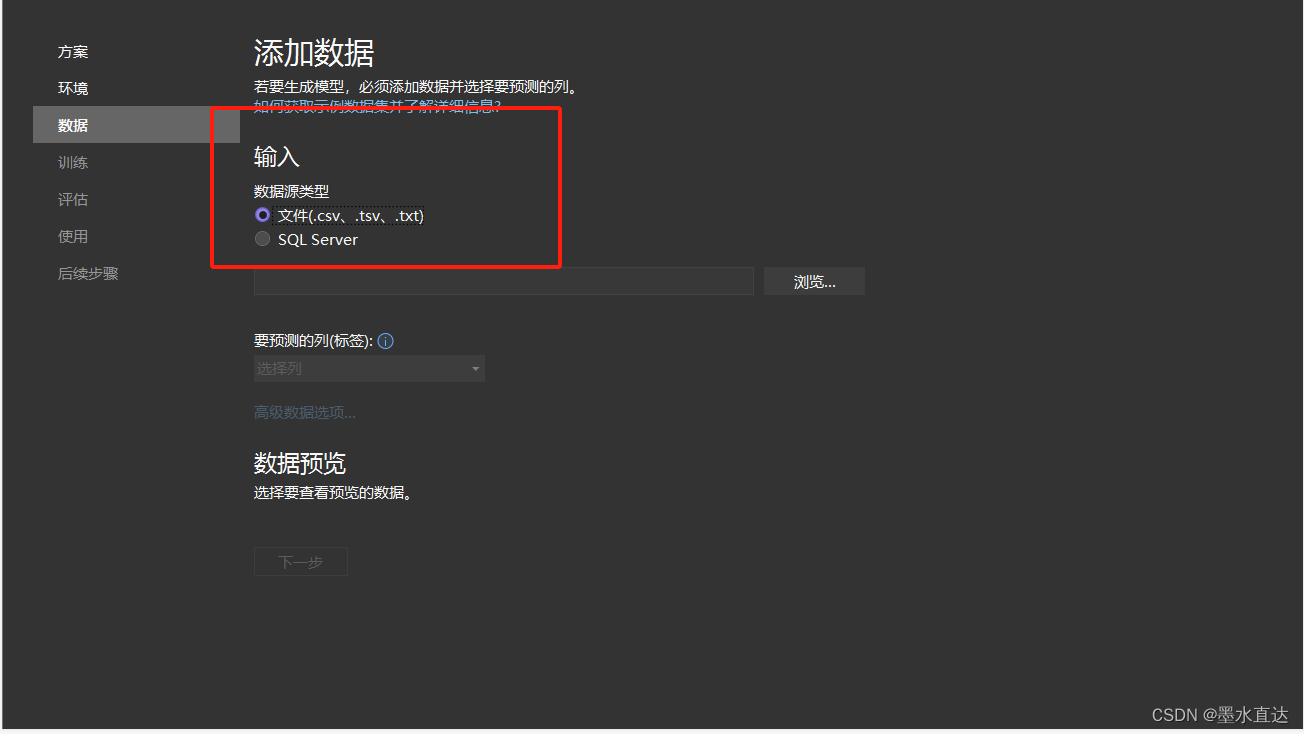
文件存放的格式如下(如果你们选择的也是csv文件,一定注意编码格式,选择utf-8,否则识别的为乱码,你们可以用记事本打开csv文件,然后另存为cav,选择格式为utf-8就可以修改了)
列1为文件内容,列2为所属标签( 比如0表示中性词,1表示正向词语,-1表示负向词语)
数据越多,预测结果越精确


设置训练时间

训练好后,会回到首页,这里我们点评估,先测试下
输入我们想测试的文字,右侧就会出现预测的结果,百分比越高,说明输入的内容越倾向于此标签

之后可以点击下一步,这里我们选择控制台应用程序,点击“添加到解决放案”,会自动生成对应的项目文件

我们可以做个测试

会输出占比最大的标签显示

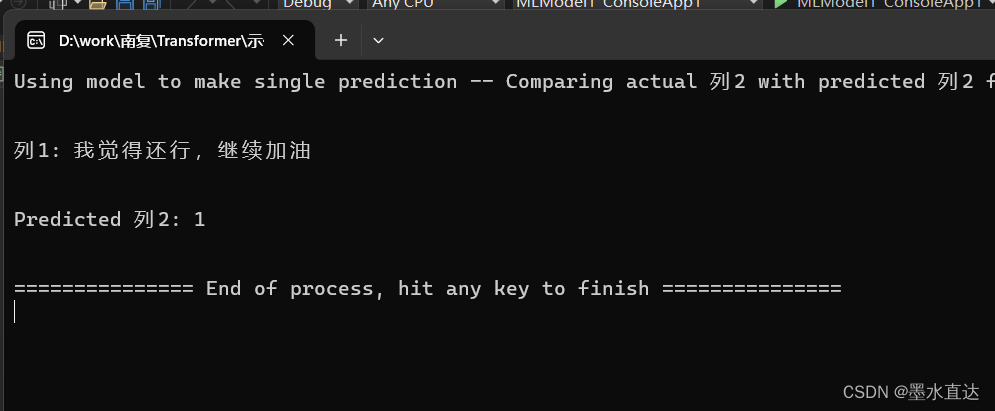 over,你们也可以创建一个webapi,这样其他项目就能直接调用此模型了
over,你们也可以创建一个webapi,这样其他项目就能直接调用此模型了















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









