







总体流程

关键流程
创建类库
若要开始训练过程,需要向新的或现有的 .NET 应用程序添加新的机器学习模型 (ML.NET) 项。推荐使用类库(类库的一个优点就是可移植性)。
使用类库,可以轻松地从控制台、桌面、Web 和任何其他类型的 .NET 应用程序引用其中的任何模型。 建议将机器学习模型 (ML.NET) 项添加到类库中。
添加机器学习模型
机器学习模型 (ML.NET) 项向项目添加一个文件扩展名为 .mbconfig 的文件。 使用 .mbconfig 扩展名的文件是采用 JSON 格式编写的 Model Builder 配置文件。 使用这些文件可以执行以下操作:
- 为你的模型提供一个名称。
- 通过源代码管理与团队中其他人协作。
- 保留状态。 如果在训练过程中(时间点不限)需要关闭 Model Builder,系统会保存你的状态,让你可以从离开的位置继续。
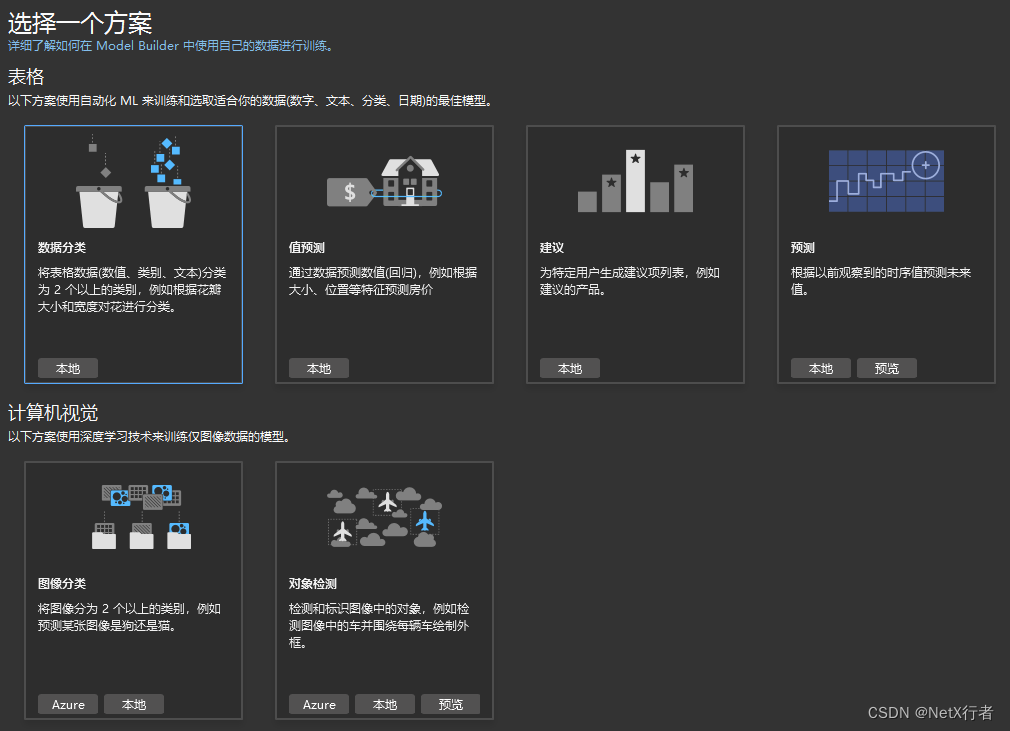
选择场景
训练机器学习模型的第一步是根据你要预测的内容确定哪种场景和机器学习任务最适合。
场景可描述你想使用数据解决的问题。 常见的场景包括上一个单元中列出的场景:
- 对数据进行分类:按主题整理新闻文章。
- 预测数值:估算房价。
- 对具有类似特征的项目分组:细分客户。
- 对图像进行分类:根据图像内容标记图像。
- 推荐项目:推荐电影。
- 检测图像中的物体:检测十字路口的行人和自行车。
这些场景对应机器学习任务。 机器学习任务是根据要询问的问题和可用数据进行的预测或推断类型。
机器学习任务通常分为两类:
- 受到监督
- 非监督式
这两类的主要区别在于尝试预测的标签或值是否已知。
对于监督式任务,标签是已知的。 监督式机器学习任务的示例包括:
- 分类
- 二元(两个类别)
- 多类(两个或更多类别)
- 映像
- 回归
对于非监督式任务,标签是未知的。 非监督式机器学习任务的示例包括:
- 群集
- 异常检测
加载训练数据
选择了场景和训练环境后,可以加载和准备数据。
数据是用于生成机器学习模型的最重要组件。 将数据加载到 Model Builder 的过程包括三个步骤:
- 选择数据源类型。
- 提供你的数据的位置。
- 选择列用途。
选择数据源类型
根据你的场景,Model Builder 支持从以下源加载数据:
- 分隔的文件(以逗号、分号和制表符分隔)
- 本地和远程 SQL Server 数据库
- 图像(.jpg 和 .png)
提供数据的位置
选择数据源类型后,必须提供存储数据集的位置。 此位置可以是目录、文件路径或数据库连接字符串。 这也取决于所选的场景和数据源类型。
在 Model Builder 中选择数据源后,它会分析数据,并尽可能地识别以下项:
- 标题和列名
- 列分隔符
- 列数据类型
- 列用途
- 小数点分隔符
加载数据后,Model Builder 将显示数据集中某些元素的预览。
选择列用途
根据所选的场景,你需要定义某些列的用途。 在数据分类和值预测等场景中,必须选择要预测的列(标签)。
默认情况下,不是标签的所有其他列都用作特征。 特征是用作输入的列,用于预测标签。
高级数据选项
若要自定义加载数据的方式,Model Builder 提供了高级数据选项。 利用这些选项,你可以自定义与列和数据集格式相关的设置。
对于列,你可以选择以下设置:
- 用途:列应该是特征、标签还是应该忽略? 只能选择一列作为标签。
- 数据类型:值是单精度浮点值、字符串或布尔值?
- 分类:列是否表示分类值(例如:低、中或高)?
若要设置数据格式,可以选择数据是否包含列标题、列分隔符(逗号、分号或制表符)以及小数点分隔符类型(句点或逗号)。
















 301
301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











