







目录
1:什么是ElasticSearch
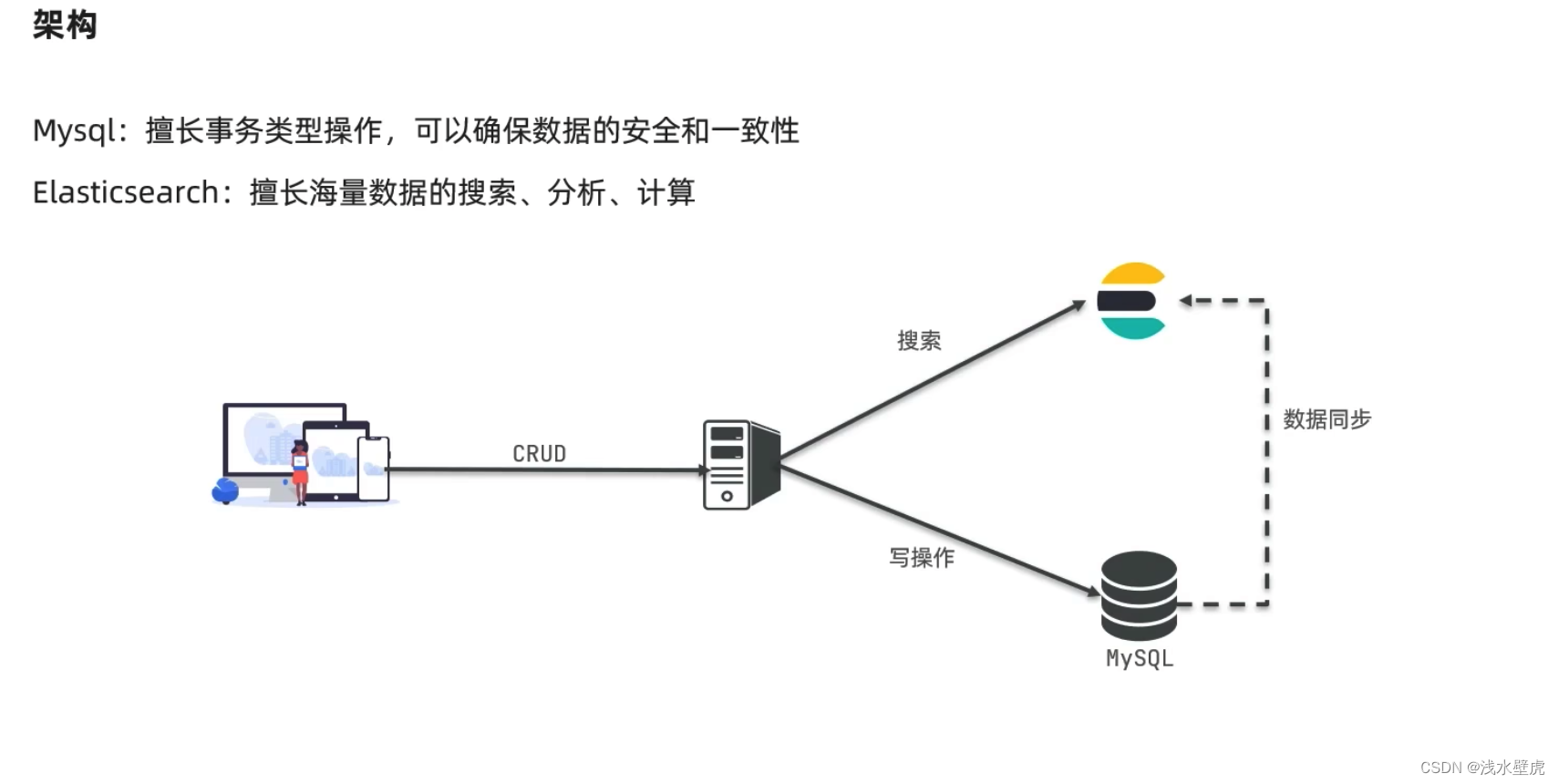
ElasticSearch(弹性搜索),简称ES。
ES是一个分布式,RESTFul风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack(Elastic技术栈简称ELK) 的核心,Elasticsearch 会集中存储您的数据,让您飞快完成搜索,微调相关性,进行强大的分析,并轻松缩放规模。
我们可以知道ES有三个特点:
1:分布式(非常方便实现集群部署)
2:RESTFul风格(使用RESTFul进行搜索)
3:搜索引擎(用于数据分析,首先数据得在ES中才行)
2:为什么要使用ElasticSearch
ES主要用来数据搜索和数据分析,这里有读者问不是有数据库吗?比如mysql的,ES和关系型数据库的分工是什么?我们下边举例说明
2.1:为什么不使用mysql
举例1:首先我们那熟悉的关系型数据mysql来举例。我们查找关系型数据库的商品表、数据量很大的时候,这里只是几条简单的数据和表用来举例,实际情况远远比这里复杂。
当我们要查找title="手机"、 "小米充电器"、 "华为" 等等字段的时候,势必要用到模糊查询
select * from order where title like "%目标字段%" ,这就很难使用到索引,即使我们在title字段上创建了索引,性能也会很差。当数据量大、并且title的内容很多的时候是个灾难
举例2:我们想象一下百度的搜索引擎,当我们程序员写了错误代码,到百度上搜索一个关键字查找答案的时候,百度是怎么处理的。比如程序出现的IO异常,我们去百度搜索,根据词条来检索出来我们需要的内容,然后把网上的资源都汇总起来。这个时候百度不会把网络资源放到mysql中,那样在查找关键字,得多慢。当然搜索引擎的技术很复杂。这里就例子就是说明了搜索引擎有多快,为什么有的情况不适用关系型数据库。
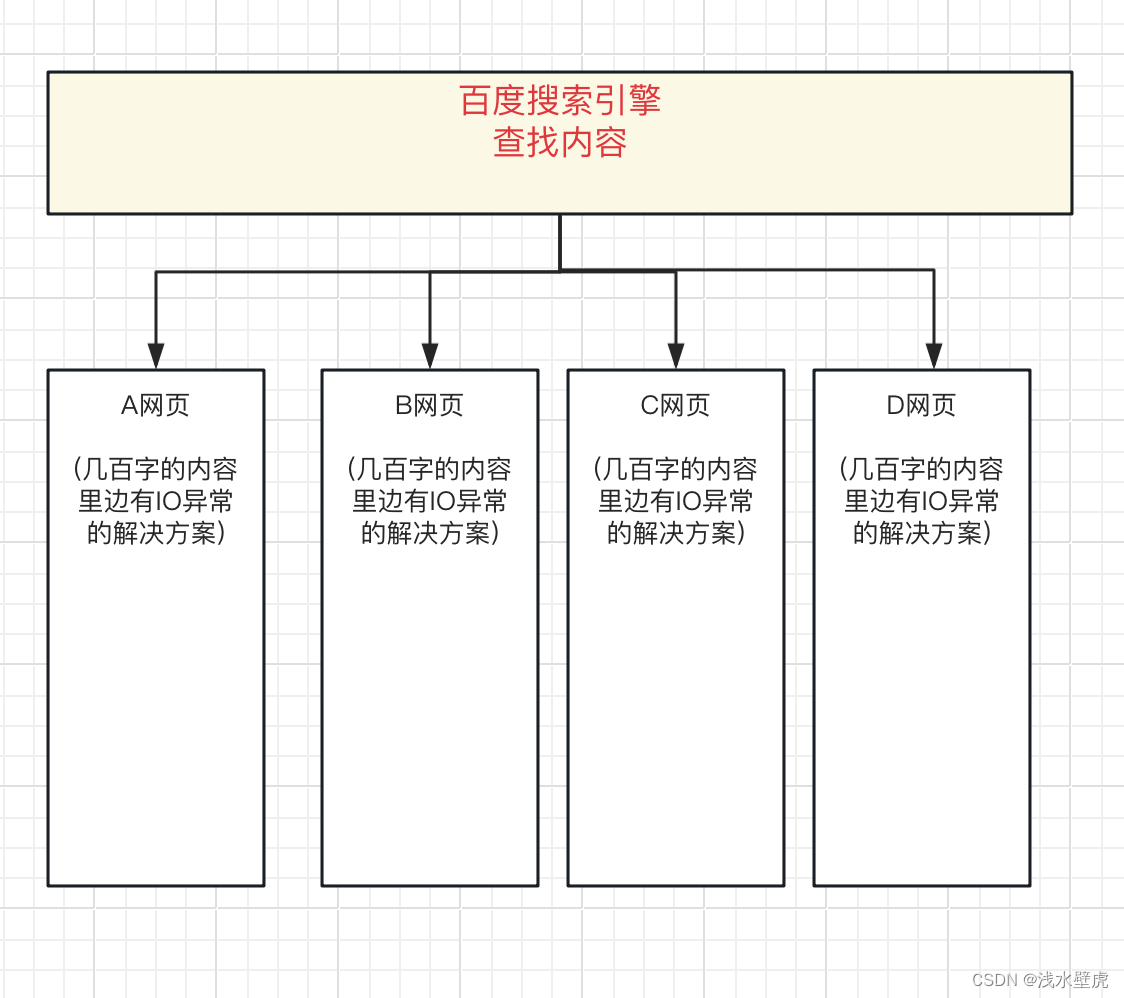
结果就是关系型数据库不适合做海量数据的搜索、分析、计算
2.2:为什么要使用ES
前边我们知道关系型数据库的检索困难,比如大数据量的文本检索、计算等等。
那么ES是怎样实现的呢?如下图所示,当我们查询字段的时候
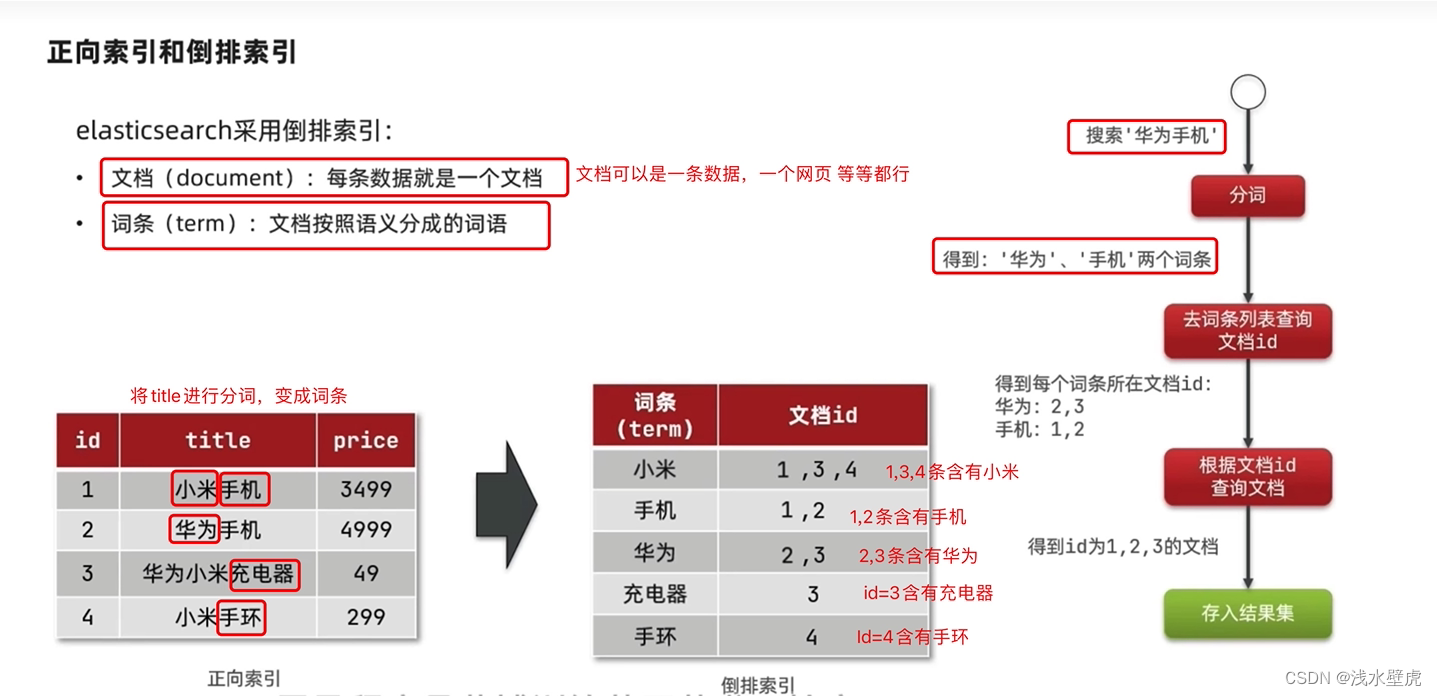
1:首先对title进行分词,分成小米、手机、华为、充电器、手环5个词
2:根据分词创建倒排索引,也就是词条和文档id的对照关系
3:进行查询的时候根据倒排索引,去词条列表中查询到文档id
4:根据文档id查询文档,存储结果集,然后返回。
这样就不会想mysql一样,模糊查询,几千万的数据也得一条一条比对,从而提升了效率。ES适合做海量数据的分析、计算,没有关系型数据库的事务概念
思考点:这样查询是很快、没问题?但是对大量的数据,比如上千万的数据进行分词,然后创建倒排索引这个过程怎么样。我也不知到、我们接着学习吧,也会能找到答案。
2.3:ES和mysql对比
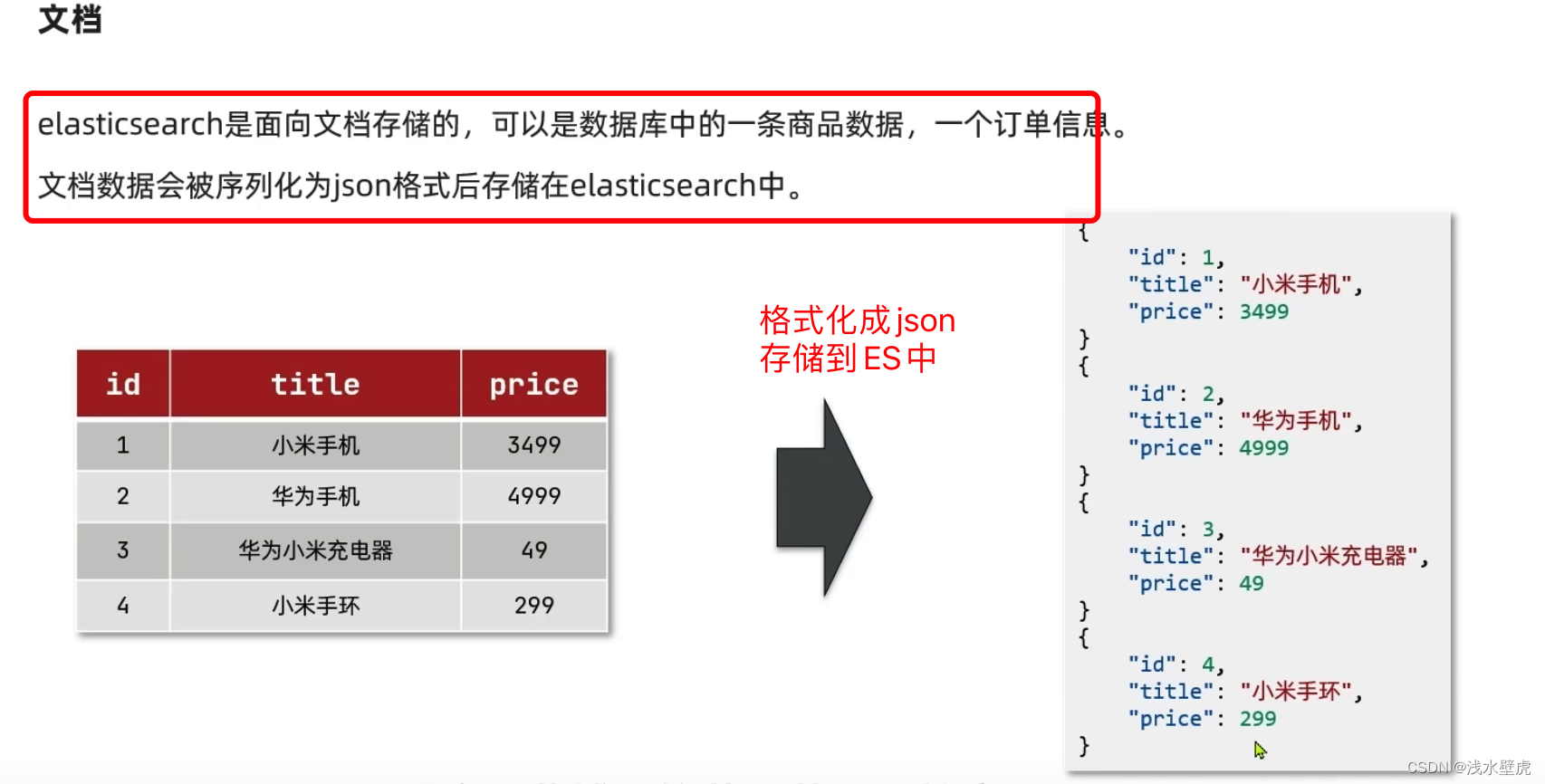
1:mysql存储是表的形式存储数据,ES是文档存储,文档就是数据,将文档格式化成json存储。
2:关系数据库 ⇒ 数据库 ⇒ 表 ⇒ 行 ⇒ 列(Columns)
Elasticsearch ⇒ 索引 ⇒ 类型 ⇒ 文档 ⇒ 字段(Fields)
总结:ES和关系型数据库各有所长、各有所短,不是替换关系,是互补关系。
3:ES的安装
3.1:ES的安装
首先官网下载自己适合的版本,由于ES是java语言开的,所以需要实现配置JDK环境。
官网地址如下:https://www.elastic.co/cn/downloads/past-releases#elasticsearch
当然最新ES的8.x版本自带了jdk,所以也就不需要了。但是7.X的版本兼容的JDK版本需要去官方查看对照表
安装步骤:主要参考了别人的博客Linux centos7.6 安装elasticsearch8.x (es8) 教程_centos7.6anzhuangelasticsearch8.9-CSDN博客
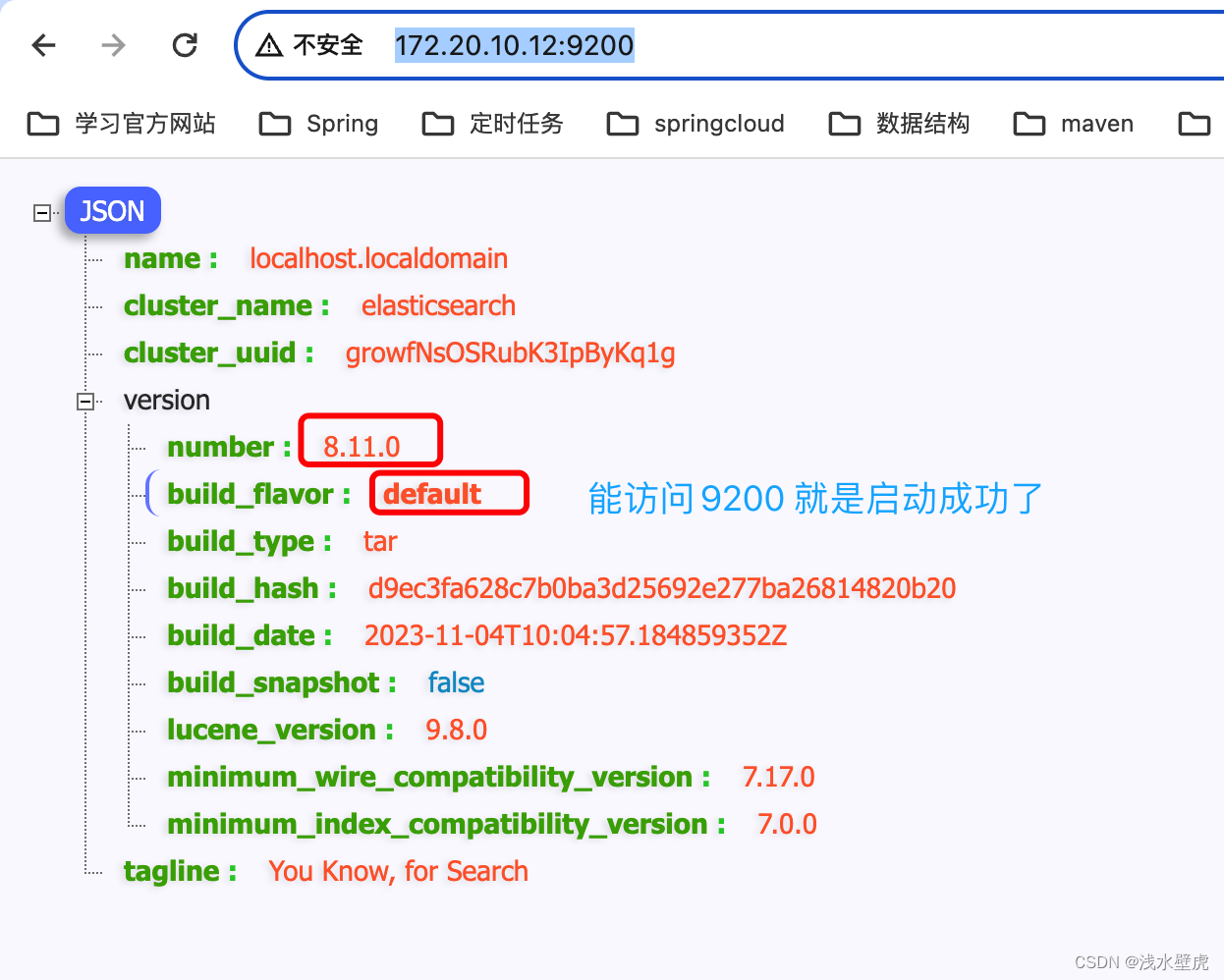
这里是使用了ES的8.10.0版本,不需要jdk了直接下载安装
1:下载ES
elasticsearch-8.11.0-linux-x86_64.tar.gz放到centos中的 /home下边,然后解压
tar -zxvf elasticsearch-8.11.0-linux-x86_64.tar.gz
2:解压安装
#创建组esgroup
groupadd esgroup
#创建用户esroot 密码是123456
useradd esroot -p 123456
#赋权限
chown -R esroot:esgroup /home/elasticsearch-8.11.0
#切换账户esroot
su esroot
#进入bin目录
cd /home/elasticsearch-8.11.0/bin/
#启动ES
./elasticsearch
#后台启动
./elasticsearch -d
#查看防火墙 如果是看到绿色的字体 active(running) 就意味着防火墙是打开状态
sudo systemctl status firewalld
#关闭防火墙
sudo systemctl stop firewalld
#再次查看防火墙3:访问自己的服务器地址
或者 curl http://172.16.35.132:9200/ 验证
3.2:Kibana安装
Kibana是一个开源的分析和可视化平台,设计用于和Elasticsearch一起工作。 你用Kibana来搜索,查看,并和存储在Elasticsearch索引中的数据进行交互
1:下载和ES同版本的jar,kibana-8.11.0-linux-x86_64.tar.gz
2:将jar放到home目录下
3:解压,修改配置文件,然后启动
#解压
tar -zxvf kibana-8.11.0-linux-x86_64.tar.gz
#修改配置文件在config目录下的kibana.yml
#Kibana端口
server.port: 5601
#所有主机都能访问
server.host: "0.0.0.0"
#配置es的访问地址 "http://es服务公网IP:9200"
elasticsearch.hosts: ["http://172.16.35.132:9200"]
xpack.reporting.capture.browser.chromium.disableSandbox: false
#设置kibana中文显示
i18n.locale: "zh-CN"
#然后设置esroot用户和esgroup组的权限
chown -R esroot:esgroup /home/home/kibana-8.11.0
#切换到esroot用户
su esroot
#进入bin目录启动
./kibana
4:访问页面,验证启动成功
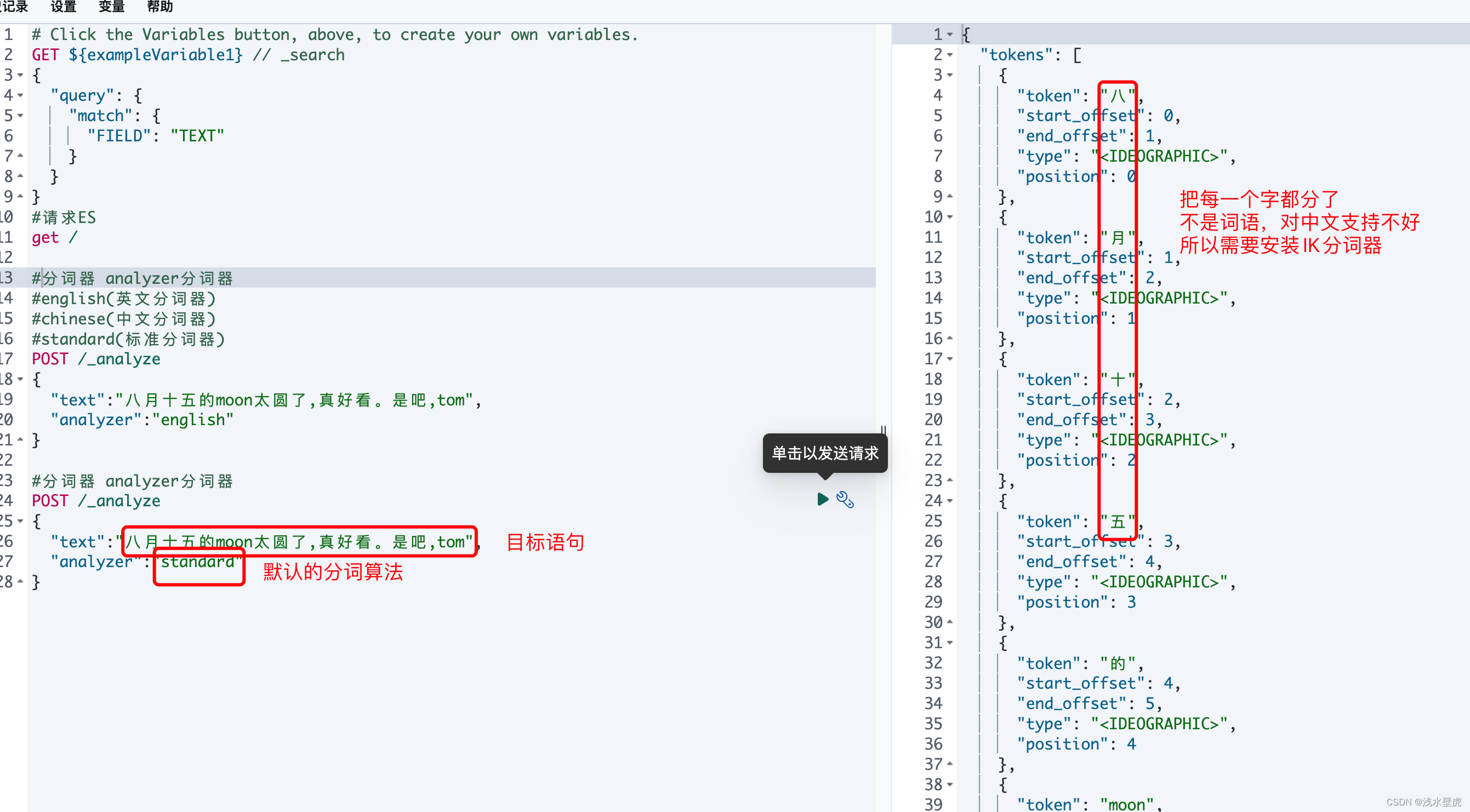
在使用kibana的过程中,发现ES的默认分词适用于英文和拉丁文,对中文支持不好。
3.3:IK分词器安装
ES默认的分词器对中文支持不好,在上面我们看到了都是一个字一个字分的,很不好用,所以我们选择IK分词器。
1:首选去github官网,下载对应的插件IK分词插件,分词器版本必须跟ES版本一致,这里本人下载版本是 elasticsearch-analysis-ik-8.11.0.zip,github官网地址如下:
https://github.com/medcl/elasticsearch-analysis-ik
2: 进入ES的插件目录
#进入ES的插件目录
/home/elasticsearch-8.11.0/plugins
#创建ik文件夹
mkdir ik
cd ik
#将分词插件IK的zip包放到ik文件夹里边,解压 然后重启ES
unzip elasticsearch-analysis-ik-8.11.0.zip查看重启日志,里边有了IK的插件

3:IK分词器介绍
在kibana中,我们使用IK分词器有两种分词粒度选择
k_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”,适合Phrase 查询。
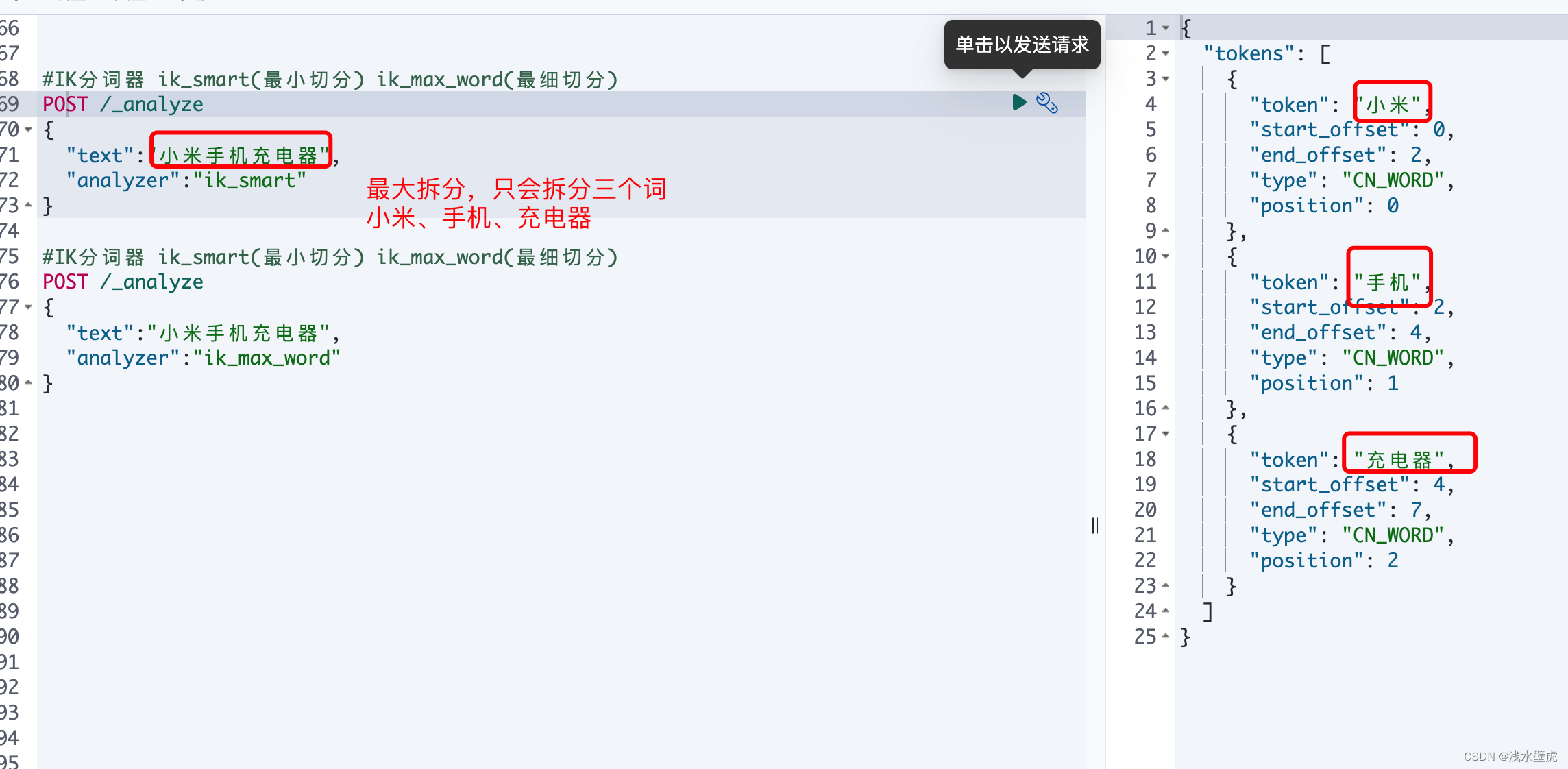
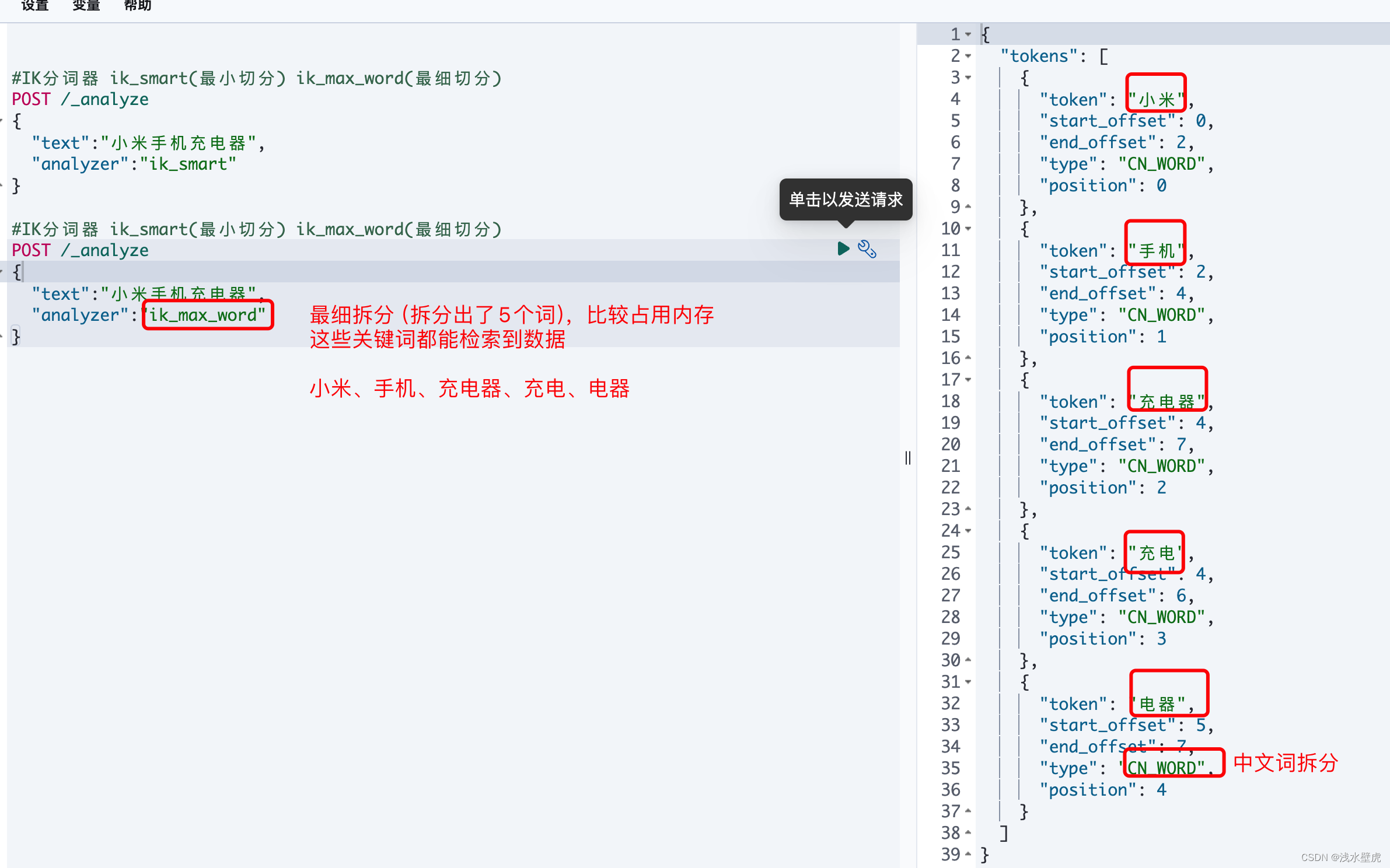
ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,国国,国歌”,会穷尽各种的组合可能,适合Term Query;
3.4:IK分词器扩展自定义字典
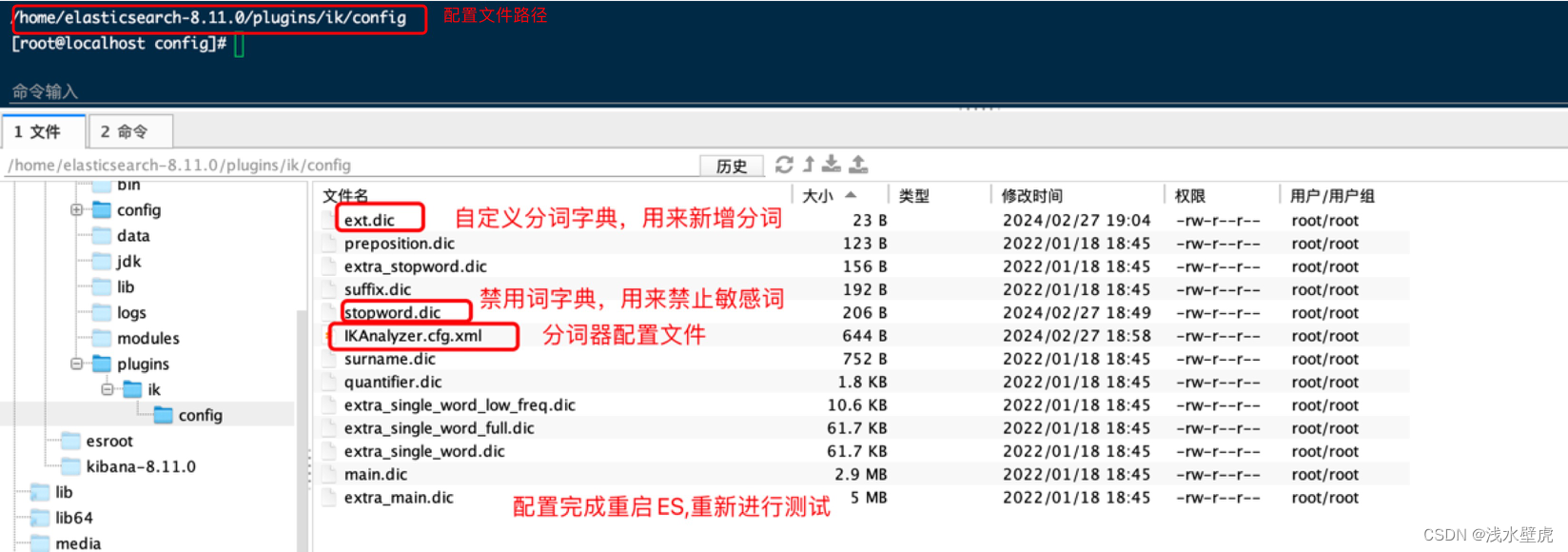
在ES的IK分词器中,我们有的时候需要添加一些新的词语(比如一些新的名词),有的时候需要禁用一些敏感词,这个时候就需要需要修改IK分词器插件中的配置文件,添加数据字典。如图所示
在IK分词器的插件路径下:/home/elasticsearch-8.11.0/plugins/ik/config
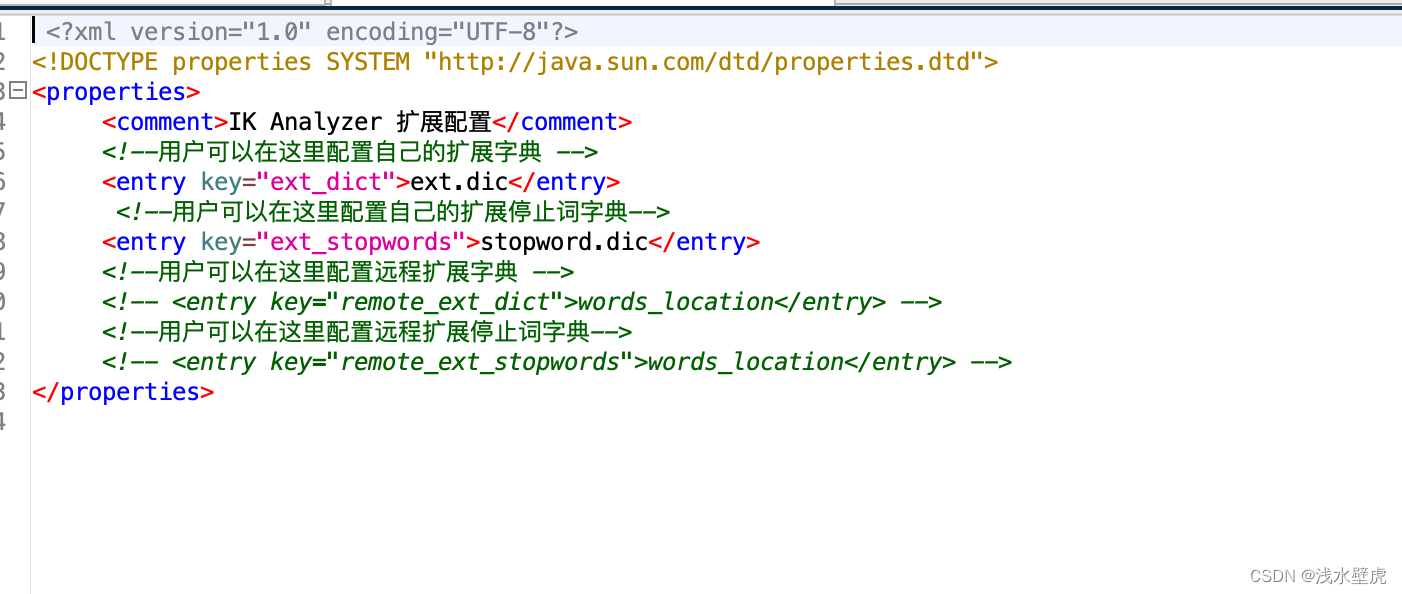
IKAnalyzer.cfg.xml配置文件修改
自定义扩展分词器之前:新的名词无法识别,出现错误。
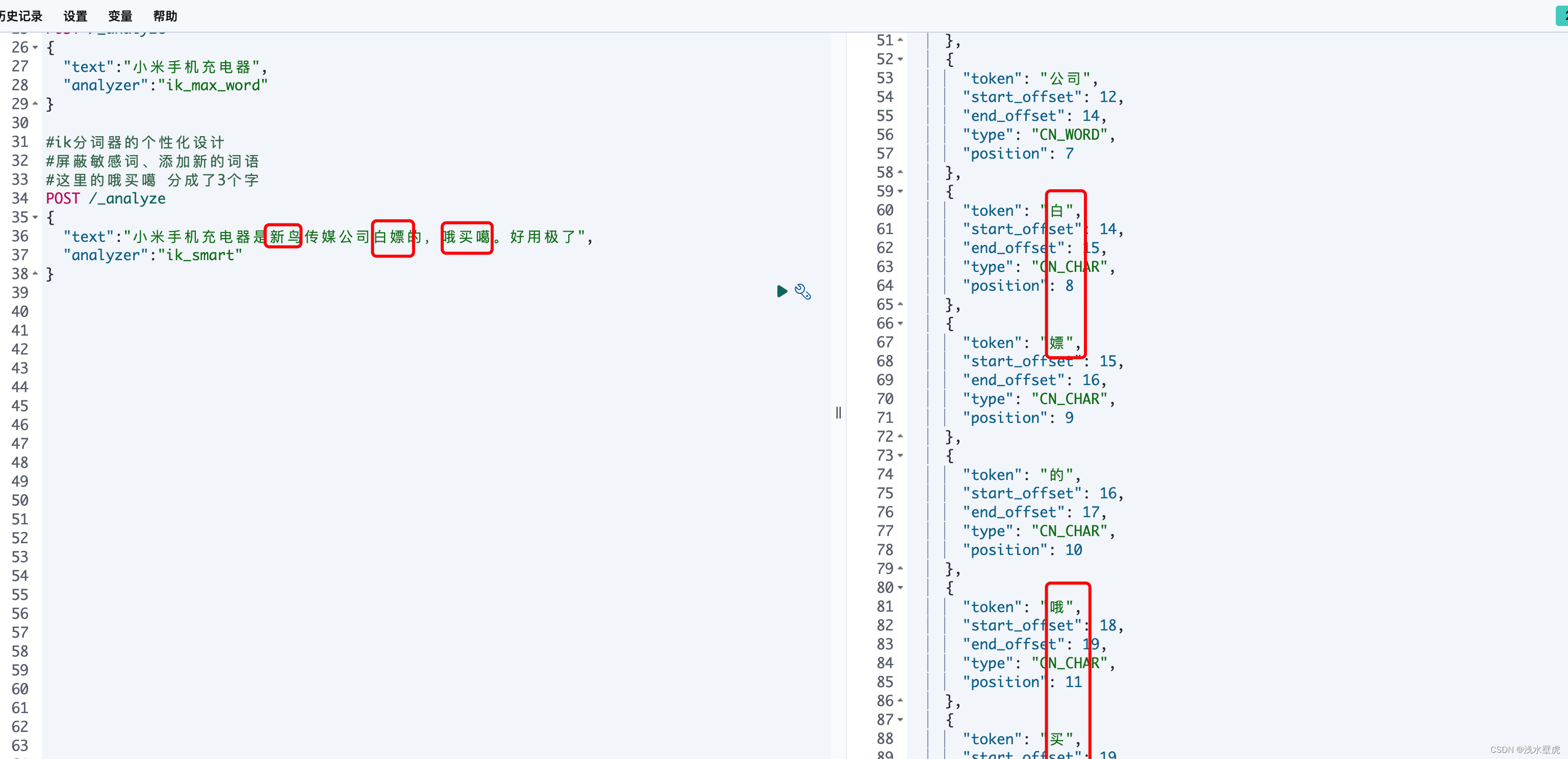
自定义分词器扩展: 创建ext.dic文件
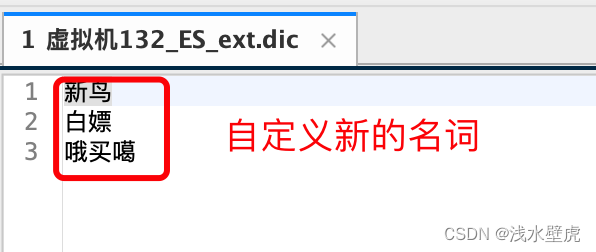
自定义扩展分词器之后:可以识别新的名词了
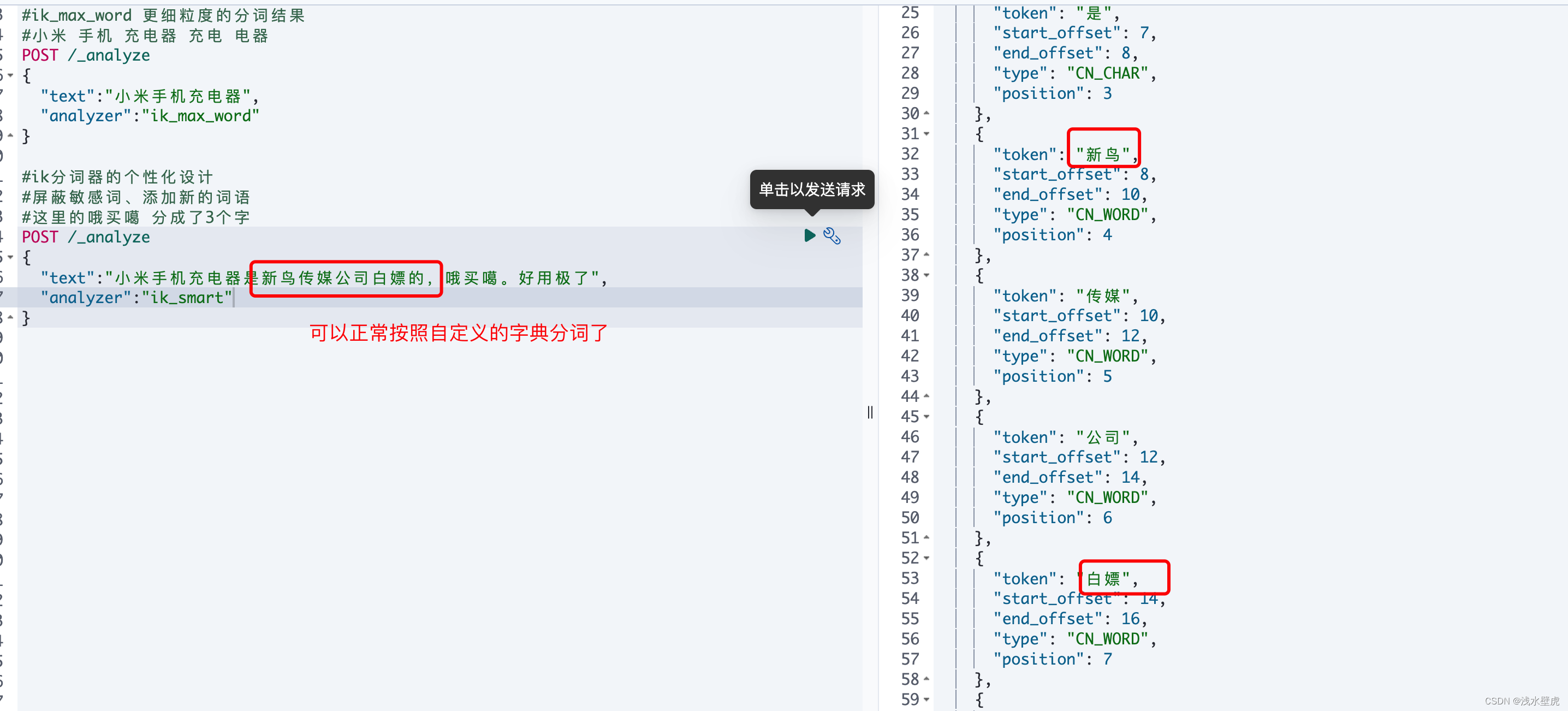
3.5:分词器的作用
分词器的作用:
1:在对文档(也就是数据)进行倒排索引创建的时候,来进行分词。
2:对搜索内容进行分词,比百度搜索,自己搜索了一大段的话,百度就会对搜索内容进行分词。

















 9942
9942

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









