朴素贝叶斯
一、概念
- 先验概率: 通过经验来判断事物发生的概率
- 后验概率: 结果已经有了,推测原因的概率 - 条件概率: p(A|B) 事件A在事件B已经发生的情况下发生的概率
- 似然函数: 用来衡量概率模型的参数
二、朴素贝叶斯公式理解 - 公式
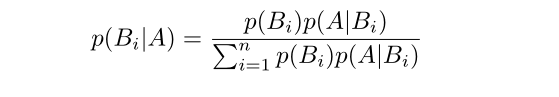
- 对于公式的理解 :
- 公式左边是我们通过特征A出现,推断它属于Bi的概率
- 公式右边分子是分类Bi在所有类别的概率*分类Bi中A出现的概率
- 公式右边分母是A在每个分类的概率之和
三、朴素贝叶斯分类器的工作流程
- 确定特征属性-----------------------获取训练样本(准备阶段)
- 计算每个类别的概率-----------------p(Ci)
- 计算每个特征在每个类别出现的概率----p(Ai|Ci)p(Ci)
四、pyhton实现对新闻的分类(sklearn 机器学习包)
4.1分类器的种类
- 高斯朴素贝叶斯:特征变量是连续变量,符合高斯分布 eg:人的身高、体重
- 多项式朴素贝叶斯:特征变量符合多项分布 eg:单词词频(TF-IDF)
- 伯努利朴素贝叶斯:特征变量符合0/1分布 eg:单词是否出现
4.2概念
- TF(Term Frequency):单词在文档中出现的次数,默认单词的重要性和它出现的次数成正比 -
- IDF(Iverse Document Frequency):单词的区分度,默认一个单词出现在的文档数越少,就越能通过这个单词把该文档和其他文档区分开
4.3如何计算TF-IDF
- 公式
-
4.4 sklearn 求 TF-IDF
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf_vec = TfidfVectorizer(stop_words=stop_words, max_df=0.5)
features = tfidf_vec.fit_transform(documents)
- 注:调用后的tfidf_vec属性值
- vocabulary_ 词汇表
- idf_ idf值
- stopwords_ 停用词表
4.5 如何对文档进行分类
4.5.1处理流程
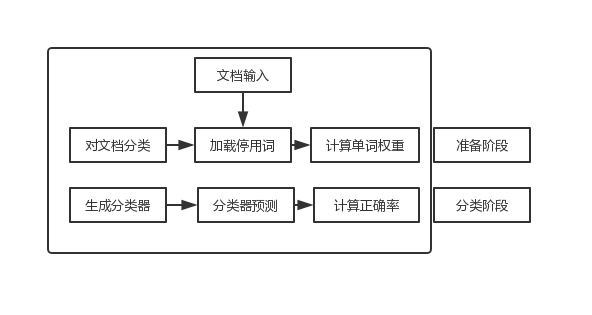
4.5.2对文档进行分词
word_list = nltk.word_tokenize(text)
nltk.post_tag(word_list)
word_list = jieba.cut(text)
4.5.3加载停用词表
stop_words = [line








 朴素贝叶斯一、概念先验概率: 通过经验来判断事物发生的概率后验概率: 结果已经有了,推测原因的概率 - 条件概率: p(A|B) 事件A在事件B已经发生的情况下发生的概率似然函数: 用来衡量概率模型的参数二、朴素贝叶斯公式理解 - 公式对于公式的理解 :公式左边是我们通过特征A出现,推断它属于Bi的概率公式右边分子是分类Bi在所有类别的概率*分类Bi中A出现的概率公式右边...
朴素贝叶斯一、概念先验概率: 通过经验来判断事物发生的概率后验概率: 结果已经有了,推测原因的概率 - 条件概率: p(A|B) 事件A在事件B已经发生的情况下发生的概率似然函数: 用来衡量概率模型的参数二、朴素贝叶斯公式理解 - 公式对于公式的理解 :公式左边是我们通过特征A出现,推断它属于Bi的概率公式右边分子是分类Bi在所有类别的概率*分类Bi中A出现的概率公式右边...
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









