







1. 引言
ClusterONE是由TamásNepusz,Haiyuan Yu和Alberto Paccanaro开发的一个由内聚力(cohesiveness)引导搜索的聚类算法。ClusterONE算法可以主要解决的是蛋白质复合物的类别识别问题,也就是PPI网络中密集子结构的识别问题。ClusterONE算法中,内聚力得分越高则代表了该组蛋白质越有可能是一种蛋白质复合物,但是ClusterONE算法仅仅依赖于内聚力公式,算法过程中可能会出现偏差。可能会出现使内聚力下降的节点,但是实际上该节点的确属于候选蛋白质复合物。所以在内聚力失去效用时,我们可以使用另一套评判机制来判断节点到底属于哪个聚类,我们将这套评判机制称为近邻选择策略。
参考文献:T.Nepusz, H. Yu, and A. Paccanaro, “Detecting overlapping protein complexes inprotein-protein interaction networks,” Nat. Methods, vol. 9, no. 5, pp.471–472, Mar. 2012.
2. ClusterONE算法详解
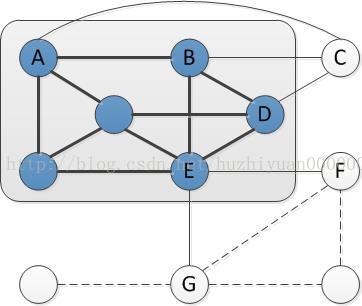
灰色阴影区域表示已知聚类,与已知聚类内部有联系的节点被称为邻居节点,在聚类内部被联系的节点被称为聚类内部的顶点节点。图中的C,F,G为聚类的邻居节点,A,B,D,E为聚类的顶点节点。深黑色边是internal edges,灰色边是boundary edges,虚线边是external edges。
内聚力被定义为如下:
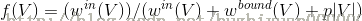
其中,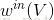
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 945
945

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









