







1、归类
聚类(clustering):属于非监督学习(unsupervised learning),是无类别标记(class label)
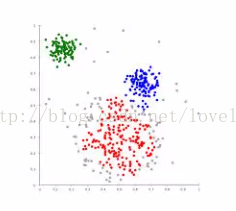
2、举例
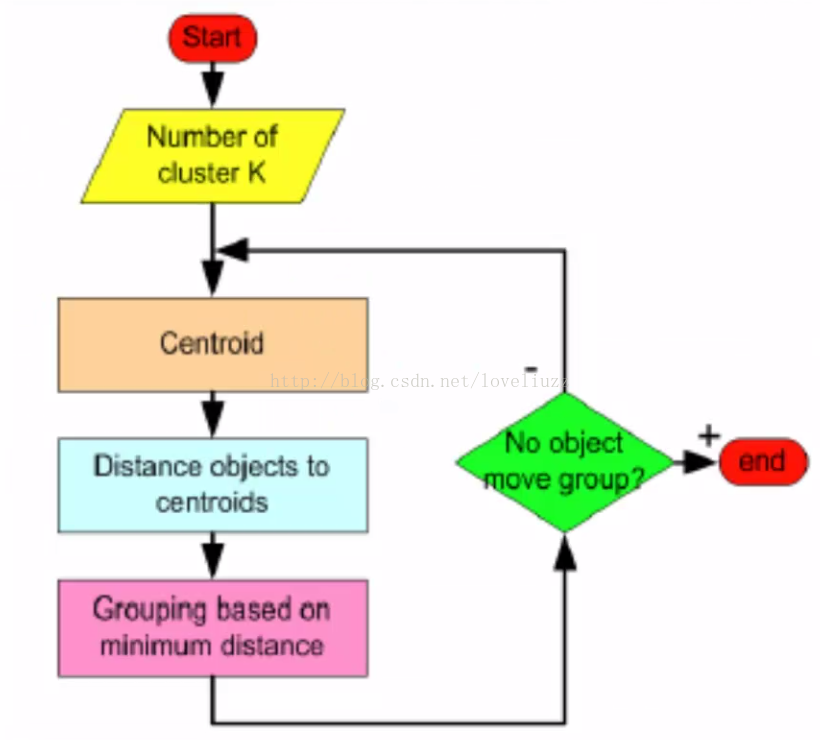
3、K-means算法
(1)K-means算法是聚类(clustering)中的经典算法,数据挖掘的十大经典算法之一
(2)算法接收参数K,然后将事先输入的n个数据划分为K个聚类以便使得所获得的聚类满足:
同一聚类中的对象相似度较高,而不同聚类中的对象相似度较低。
(3)算法思想:以空间中K个点作为中心进行聚类,对最靠近它们的对象进行归类;
通过迭代的方法,逐渐更新各聚类中心的值,直至得到最好的聚类结果。
(4)算法的描述:
a、适当选择c个类的初始中心
b、在第K次迭代中,对任意一个样本,求其到c各中心的距离,将该样本归类到距离最短的中心所在的类。
c、利用均值等方法更新该类的中心值
d、对所有的c个聚类中心,如果利用b、c的迭代更新后,值保持不变,则迭代结束;否则继续迭代。
(5)算法的流程:
输入K,data[n]
a、选择K个初始中心,例如:c[0] = data[0],...,c[k-1] = data[k-1];
b、对于data[0]......data[n]分别c[0].....c[k-1]进行比较,假定与c[i]距离最小,就标记为i;
c、对于所有标记为i点,重新计算中心点c[i] = {所有标记为i的data[i]之和}/标记为i的个数;
d、重复b、c,直到所有的c[i]的值的变化小于给定的阈值。
4、举例
举例:将下面的4颗药分成两类,K值即为:2。

这里给出的特征值是2维的,可以表示在一个平面上;不论是几维的向量,都可以在一个超平面上表示出来。

(1)初始两类中心点分别为A(1,1)、B(2,1),对4个点分别计算到2个中心点的欧式距离,距离哪个类的距离小,就归为那一类。
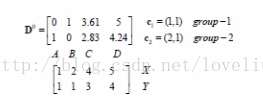
矩阵D的第一行表示:4个点到第一个类中心(1,1)的距离,第二行表示:4个点到第二个类中心(2,1)的距离。
比较每个点到两类的距离,归为距离小的类,得到归类的矩阵如下:1表示:归为此类;0表示:不归为此类。
第一次归类结果为:A归为:第一类;B、C、D归为第二类。

(2)利用均值,重新计算每个聚类中心点坐标
c1=(1,1);c2 = ((2+4+5)/3,(1+3+4)/3)=(11/3,8/3)
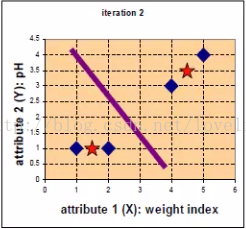
更新每个聚类中心点坐标之后如下图:

(3)再次计算4个点到新的聚类中心点的距离,第二次归类结果为:A、B归为:第一类;C、D归为第二类。
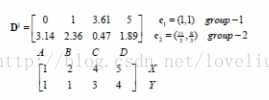

(4)继续迭代,求新的聚类中心的坐标,继续分类,直到分类结果不再发生变化。
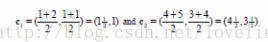

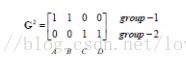
(5)最终的分类结果:A、B归为:第一类;C、D归为第二类。
5、K-means算法的优缺点:
优点:速度快、简单
缺点:最终结果跟初始点选择相关,容易陷入局部最优,需要知道K值,有可能在分类之前不知道要分成几类。
6、在Python中实现K-means算法的上述实例
(1)随机选取初始化中心点的情况
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
import numpy as np
#x:数据集是一个numpy数组(每行代表一个数据点,每列代表一个特征值),k:分类数,maxIt:迭代次数
def kmeans(X,k,maxIt):
numPoints, numDim = X.shape #返回数据集X的行数和列数
dataSet = np.zeros((numPoints,numDim+1)) #初始化新的数据集dataSet比X多一列,用来存放分标签
dataSet[:,:-1] = X #dataSet的所有行和除去最后一列的所有列的数值与X相同
#随机初始化k个中心点(利用randint函数从所有行实例中随机选出k个实例作为中心点)
centroids = dataSet[np.random.randint(numPoints,size=k),:]
#centroids = dataSet[0:2,:] #初始化前两个实例作为中心点(也可以随机选取初始化中心点)
#为中心点最后一列初始化分类标记1到k
centroids[:,-1] = range(1,k+1)
iterations = 0 #循环次数
oldCentroids = None #旧的中心点
while not shouldStop(oldCentroids,centroids,iterations,maxIt):
print("iterations:\n",iterations) #打印当前循环迭代次数
print("dataSet:\n",dataSet) #打印当前数据集
print("centroids:\n",centroids) #打印当前的中心
oldCentroids = np.copy(centroids) #将当前中心点赋值到旧中心点中
iterations += 1 #迭代次数加1
#依照中心点为每个实例归类
updateLabels(dataSet,centroids)
#根据归类后数据集和k值,计算新的中心点
centroids = getCentroids(dataSet,k)
return dataSet
#迭代停止函数
def shouldStop(oldCentroids,centroids,iterations,maxIt):
if iterations > maxIt:
return True #迭代次数比最大迭代次数大,则停止迭代
return np.array_equal(oldCentroids,centroids) #比较新旧中心点的值是否相等,相等返回True,迭代终止
#依照中心点为每个实例归类
def updateLabels(dataSet,centroids):
numPoints, numDim = dataSet.shape #获取当前数据集的行列数
for i in range(0,numPoints):
#当前行实例与中心点的距离最近的标记作为该实例的标记
dataSet[i,-1] = getLabelFromClosesCentroid(dataSet[i,:-1],centroids)
def getLabelFromClosesCentroid(dataSetRow,centroids):
label = centroids[0,-1] #初始化当前标记赋值为第一个中心点的标记(第一行最后一列)
minDist = np.linalg.norm(dataSetRow - centroids[0,:-1]) #初始化计算当前行实例与第一个中心点实例的欧氏距离
for i in range(1,centroids.shape[0]): #遍历第二个到最后一个中心点
dist = np.linalg.norm(dataSetRow - centroids[i,:-1]) #计算当前行实例与每一个中心点实例的欧氏距离
if dist < minDist:
minDist = dist
label = centroids[i,-1] #若当前的欧氏距离比初始化的小,则取当前中心点的标记作为该实例标记
print("minDist:",minDist)
return label
##根据归类后数据集和k值,计算新的中心点
def getCentroids(dataSet,k):
#最后返回的新的中心点的值有k行,列数与dataSet相同
result = np.zeros((k,dataSet.shape[1]))
for i in range(1,k+1):
#将所有标记是当前同一类的实例的数据组成一个类
oneCluster = dataSet[dataSet[:,-1] == i,:-1]
result[i-1,:-1] = np.mean(oneCluster,axis = 0) #对同一类的实例求均值找出新的中心点
result[i-1,-1] = i
return result
x1 = np.array([1,1])
x2 = np.array([2,1])
x3 = np.array([4,3])
x4 = np.array([5,4])
testX = np.vstack((x1,x2,x3,x4)) #垂直方向合并numpy数组
result = kmeans(testX,2,10)
print("final result:",result)
iterations:
0
dataSet:
[[ 1. 1. 0.]
[ 2. 1. 0.]
[ 4. 3. 0.]
[ 5. 4. 0.]]
centroids:
[[ 5. 4. 1.]
[ 2. 1. 2.]]
minDist: 1.0
minDist: 0.0
minDist: 1.41421356237
minDist: 0.0
iterations:
1
dataSet:
[[ 1. 1. 2.]
[ 2. 1. 2.]
[ 4. 3. 1.]
[ 5. 4. 1.]]
centroids:
[[ 4.5 3.5 1. ]
[ 1.5 1. 2. ]]
minDist: 0.5
minDist: 0.5
minDist: 0.707106781187
minDist: 0.707106781187
final result: [[ 1. 1. 2.]
[ 2. 1. 2.]
[ 4. 3. 1.]
[ 5. 4. 1.]]
(2)初始化前两个实例作为中心点的情况
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author:ZhengzhengLiu
import numpy as np
#x:数据集是一个numpy数组(每行代表一个数据点,每列代表一个特征值),k:分类数,maxIt:迭代次数
def kmeans(X,k,maxIt):
numPoints, numDim = X.shape #返回数据集X的行数和列数
dataSet = np.zeros((numPoints,numDim+1)) #初始化新的数据集dataSet比X多一列,用来存放分标签
dataSet[:,:-1] = X #dataSet的所有行和除去最后一列的所有列的数值与X相同
#随机初始化k个中心点(利用randint函数从所有行实例中随机选出k个实例作为中心点)
centroids = dataSet[np.random.randint(numPoints,size=k),:]
centroids = dataSet[0:2,:] #初始化前两个实例作为中心点(也可以随机选取初始化中心点)
#为中心点最后一列初始化分类标记1到k
centroids[:,-1] = range(1,k+1)
iterations = 0 #循环次数
oldCentroids = None #旧的中心点
while not shouldStop(oldCentroids,centroids,iterations,maxIt):
print("iterations:\n",iterations) #打印当前循环迭代次数
print("dataSet:\n",dataSet) #打印当前数据集
print("centroids:\n",centroids) #打印当前的中心
oldCentroids = np.copy(centroids) #将当前中心点赋值到旧中心点中
iterations += 1 #迭代次数加1
#依照中心点为每个实例归类
updateLabels(dataSet,centroids)
#根据归类后数据集和k值,计算新的中心点
centroids = getCentroids(dataSet,k)
return dataSet
#迭代停止函数
def shouldStop(oldCentroids,centroids,iterations,maxIt):
if iterations > maxIt:
return True #迭代次数比最大迭代次数大,则停止迭代
return np.array_equal(oldCentroids,centroids) #比较新旧中心点的值是否相等,相等返回True,迭代终止
#依照中心点为每个实例归类
def updateLabels(dataSet,centroids):
numPoints, numDim = dataSet.shape #获取当前数据集的行列数
for i in range(0,numPoints):
#当前行实例与中心点的距离最近的标记作为该实例的标记
dataSet[i,-1] = getLabelFromClosesCentroid(dataSet[i,:-1],centroids)
def getLabelFromClosesCentroid(dataSetRow,centroids):
label = centroids[0,-1] #初始化当前标记赋值为第一个中心点的标记(第一行最后一列)
minDist = np.linalg.norm(dataSetRow - centroids[0,:-1]) #初始化计算当前行实例与第一个中心点实例的欧氏距离
for i in range(1,centroids.shape[0]): #遍历第二个到最后一个中心点
dist = np.linalg.norm(dataSetRow - centroids[i,:-1]) #计算当前行实例与每一个中心点实例的欧氏距离
if dist < minDist:
minDist = dist
label = centroids[i,-1] #若当前的欧氏距离比初始化的小,则取当前中心点的标记作为该实例标记
print("minDist:",minDist)
return label
##根据归类后数据集和k值,计算新的中心点
def getCentroids(dataSet,k):
#最后返回的新的中心点的值有k行,列数与dataSet相同
result = np.zeros((k,dataSet.shape[1]))
for i in range(1,k+1):
#将所有标记是当前同一类的实例的数据组成一个类
oneCluster = dataSet[dataSet[:,-1] == i,:-1]
result[i-1,:-1] = np.mean(oneCluster,axis = 0) #对同一类的实例求均值找出新的中心点
result[i-1,-1] = i
return result
x1 = np.array([1,1])
x2 = np.array([2,1])
x3 = np.array([4,3])
x4 = np.array([5,4])
testX = np.vstack((x1,x2,x3,x4)) #垂直方向合并numpy数组
result = kmeans(testX,2,10)
print("final result:",result)
iterations:
0
dataSet:
[[ 1. 1. 1.]
[ 2. 1. 2.]
[ 4. 3. 0.]
[ 5. 4. 0.]]
centroids:
[[ 1. 1. 1.]
[ 2. 1. 2.]]
minDist: 0.0
minDist: 0.0
minDist: 2.82842712475
minDist: 4.24264068712
iterations:
1
dataSet:
[[ 1. 1. 1.]
[ 2. 1. 2.]
[ 4. 3. 2.]
[ 5. 4. 2.]]
centroids:
[[ 1. 1. 1. ]
[ 3.66666667 2.66666667 2. ]]
minDist: 0.0
minDist: 1.0
minDist: 0.471404520791
minDist: 1.88561808316
iterations:
2
dataSet:
[[ 1. 1. 1.]
[ 2. 1. 1.]
[ 4. 3. 2.]
[ 5. 4. 2.]]
centroids:
[[ 1.5 1. 1. ]
[ 4.5 3.5 2. ]]
minDist: 0.5
minDist: 0.5
minDist: 0.707106781187
minDist: 0.707106781187
final result: [[ 1. 1. 1.]
[ 2. 1. 1.]
[ 4. 3. 2.]
[ 5. 4. 2.]]对比两种情况的聚类,结果一致。

















 1891
1891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









