







1.调试
1.1调试中数组传参时如何观察数组
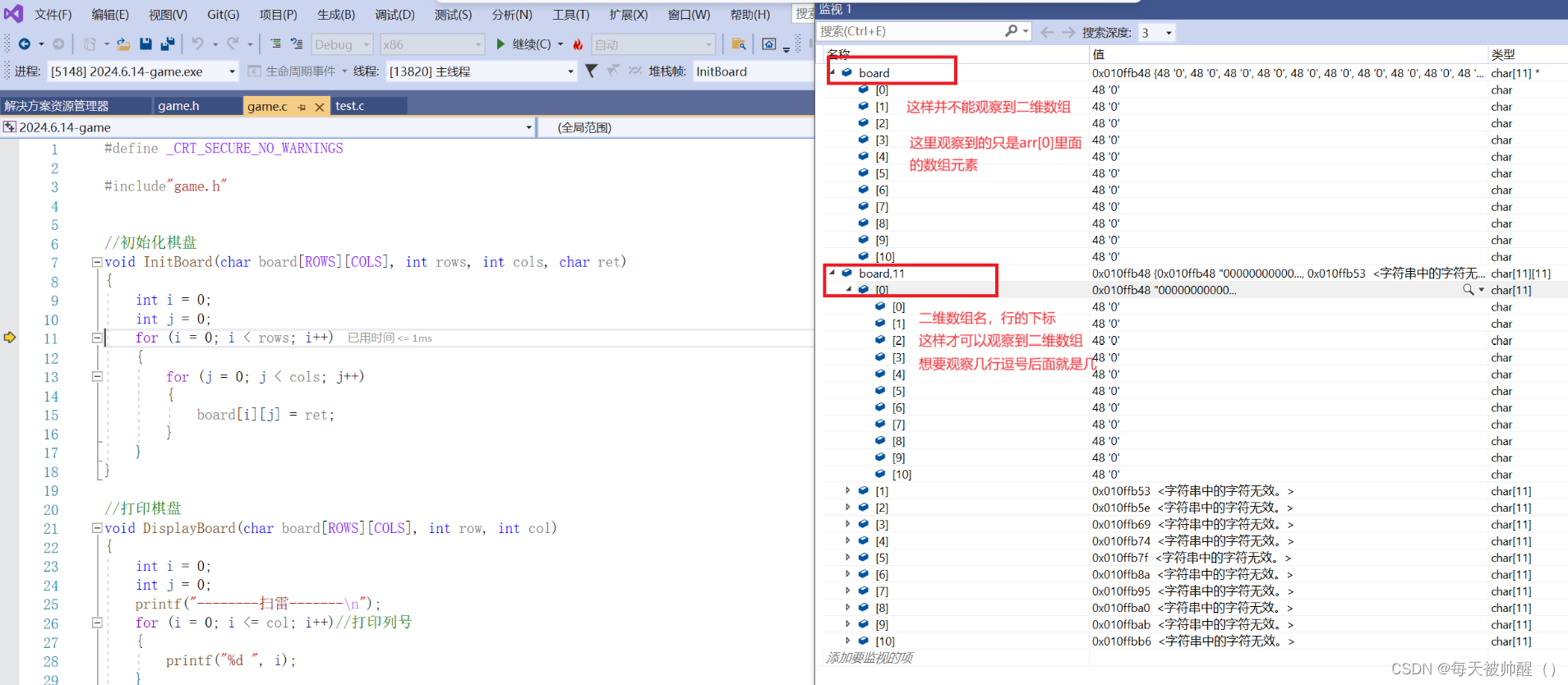
1.2用调试的方法,来具体看看strcpy函数的使用
strcpy函数在使用之前两个数组中的元素
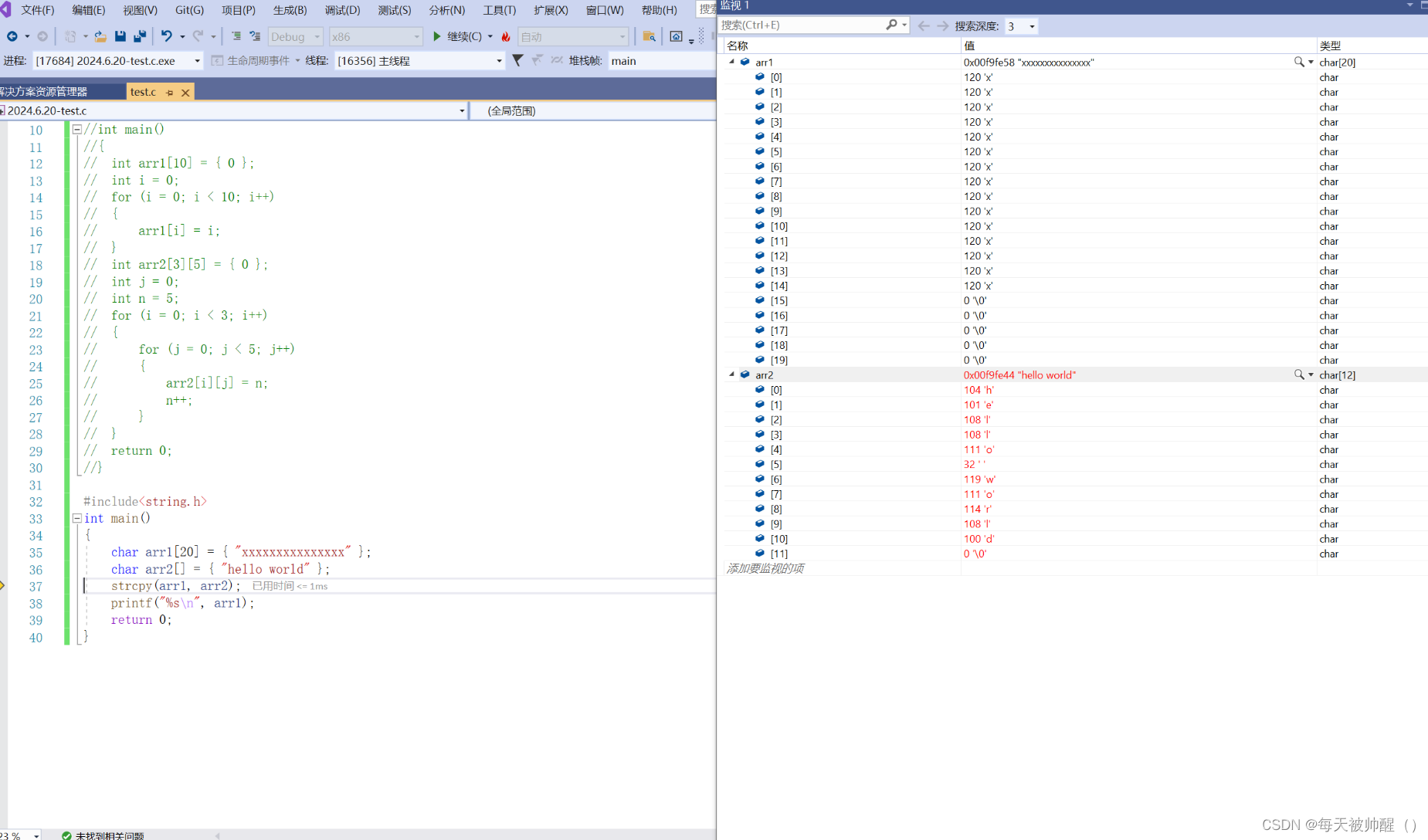
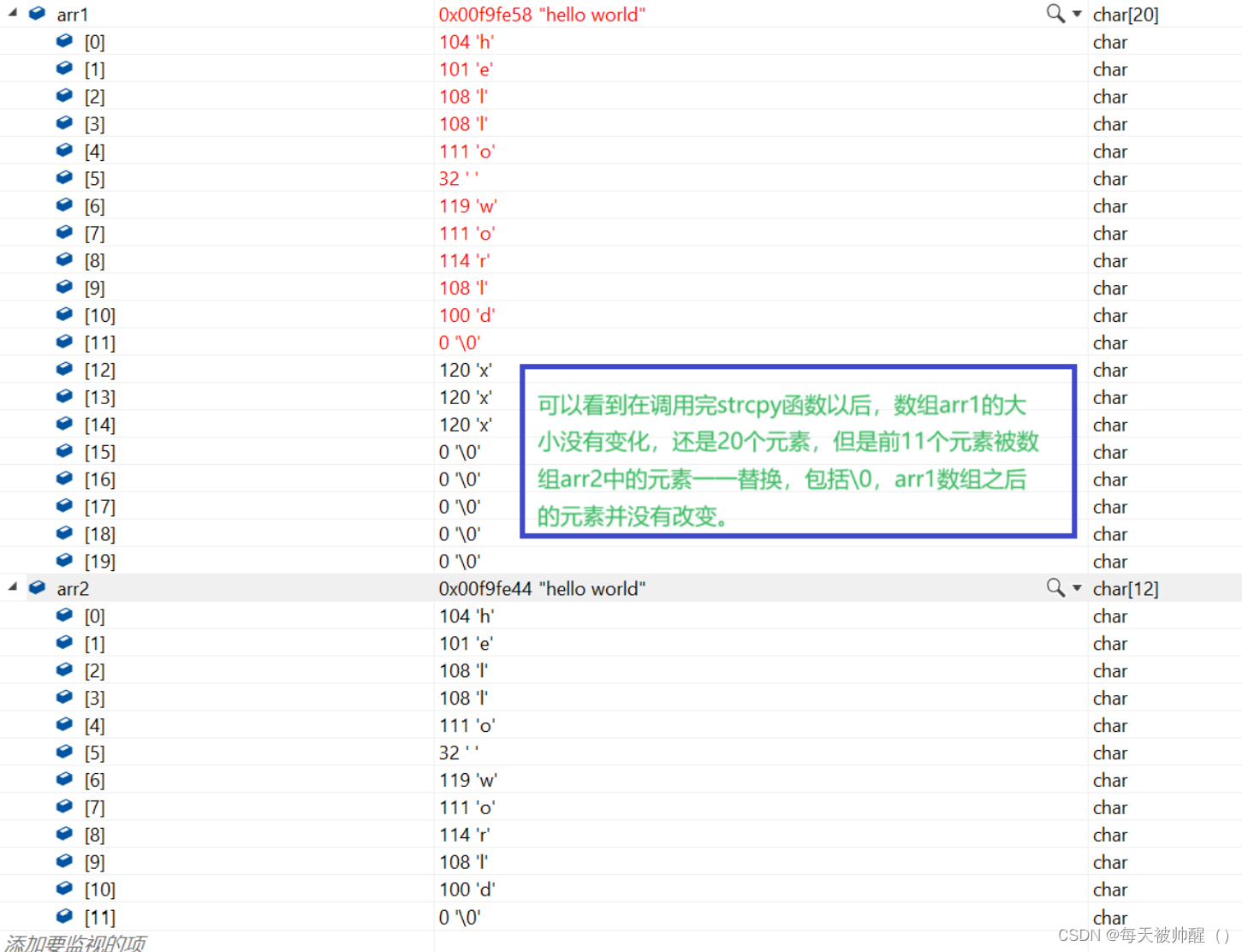
strcpy函数调用之后数组中的元素变化
2.如何写出更好的的代码
const可以对变量指针等进行限制,以保证其存储的值不会被改变
2.1关于assert的使用
assert是断言部分,当()内表达式值为0是就会出现弹窗报错
assert是库函数,在使用前要加上头文件<saaert.h>
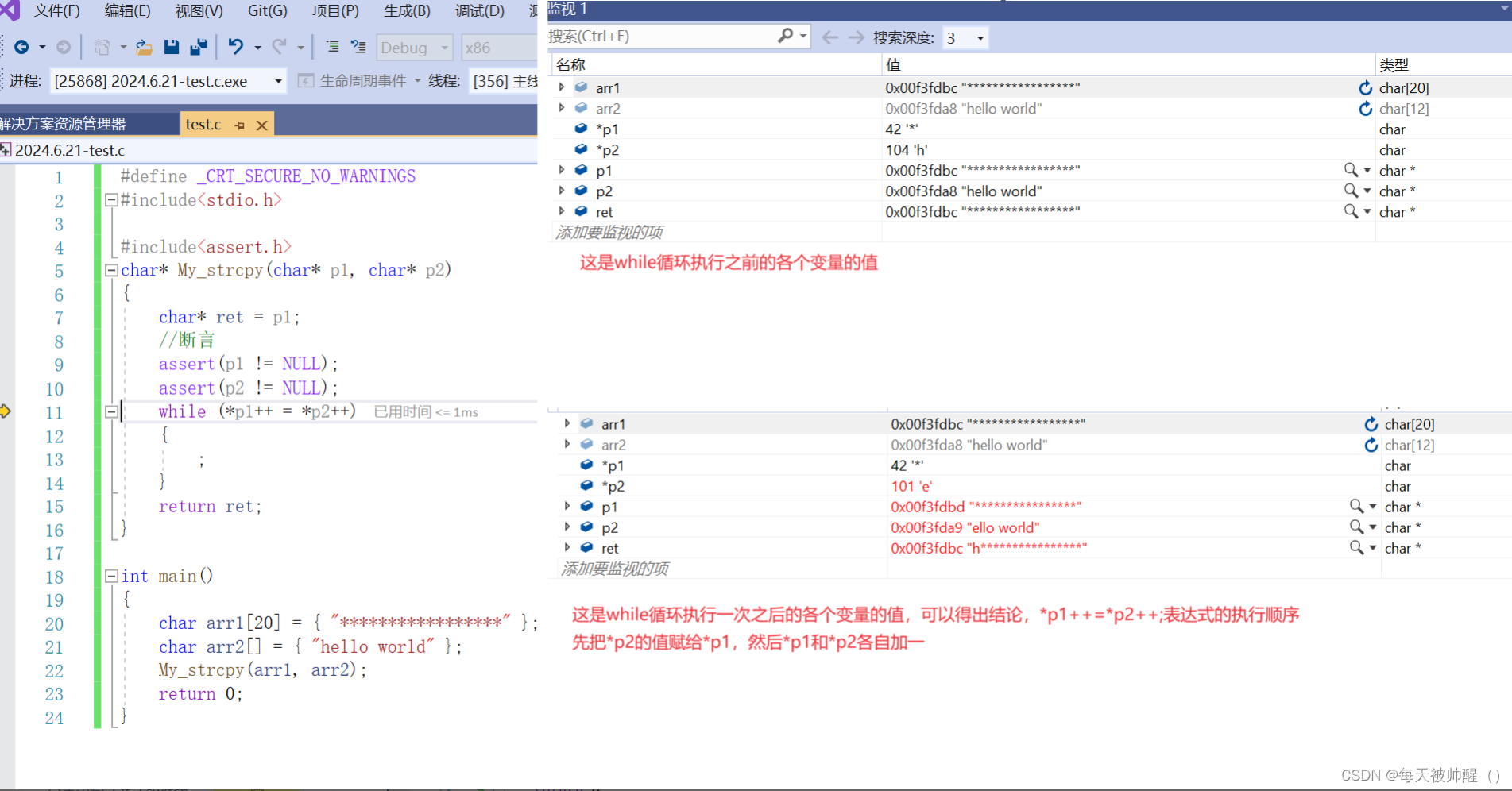
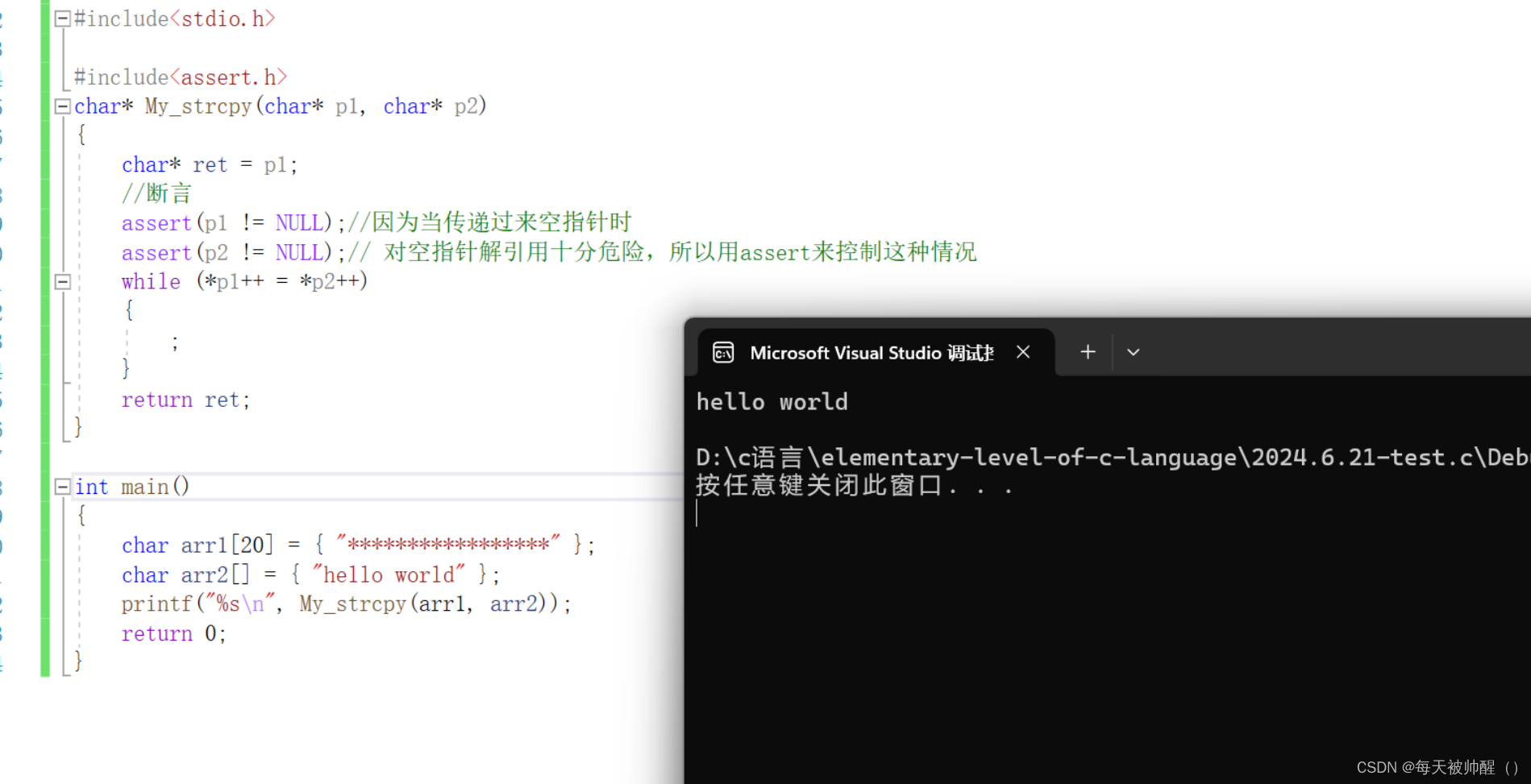
当传递空指针时,会直接报错

2.2const修饰指针和变量
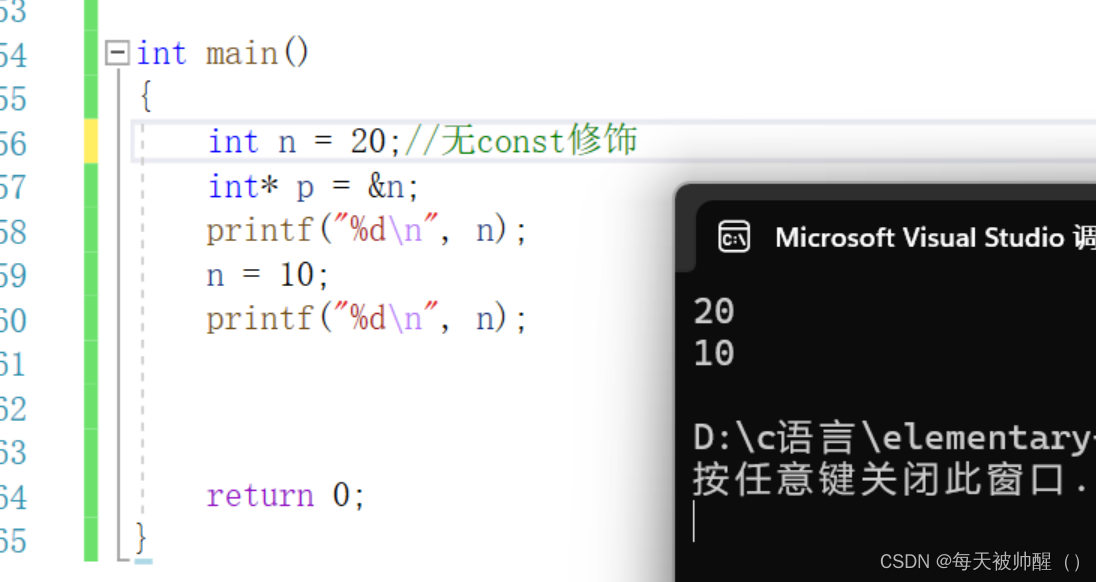
2.21const修饰变量
只是这种变量不能被修改,这一点在vs编译器中可以用变长数组来验证

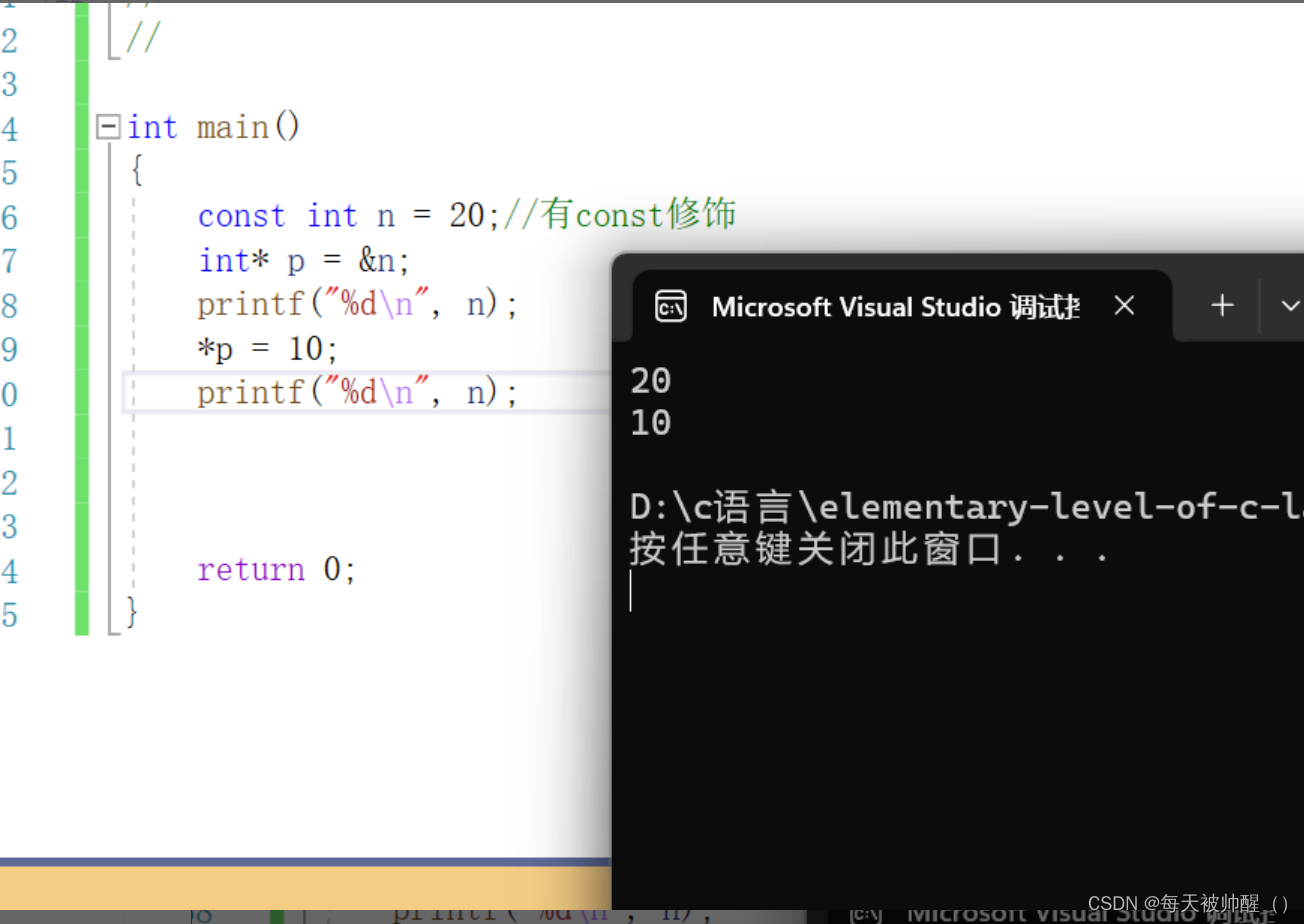
这样就会显得const在修饰的时候有些无用,接下来就会涉及到const修饰指针
2.22const修饰指针时的情况
const在*左边时
const在左边时,const修饰的是*p即const *p,
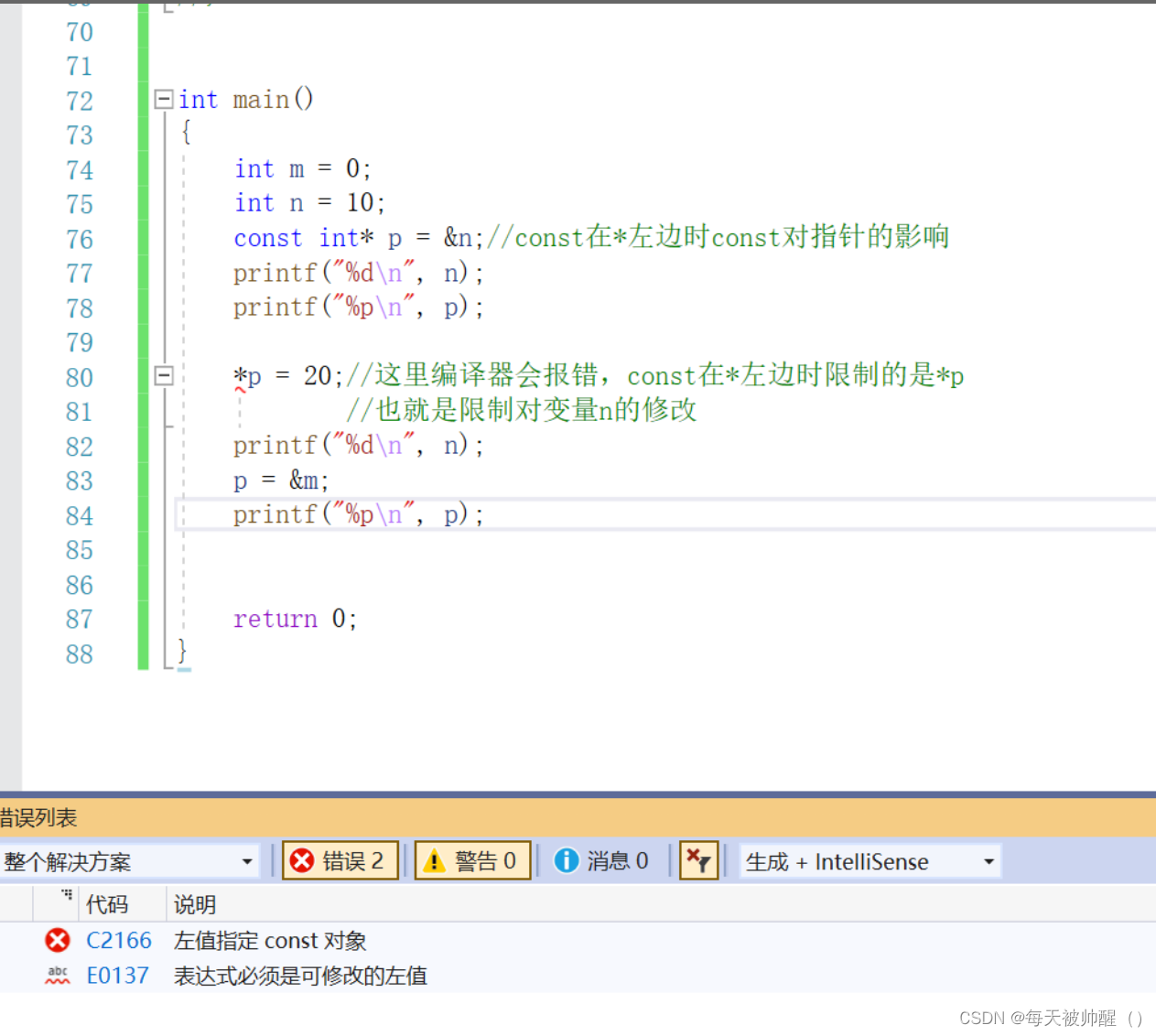

const在*右边时
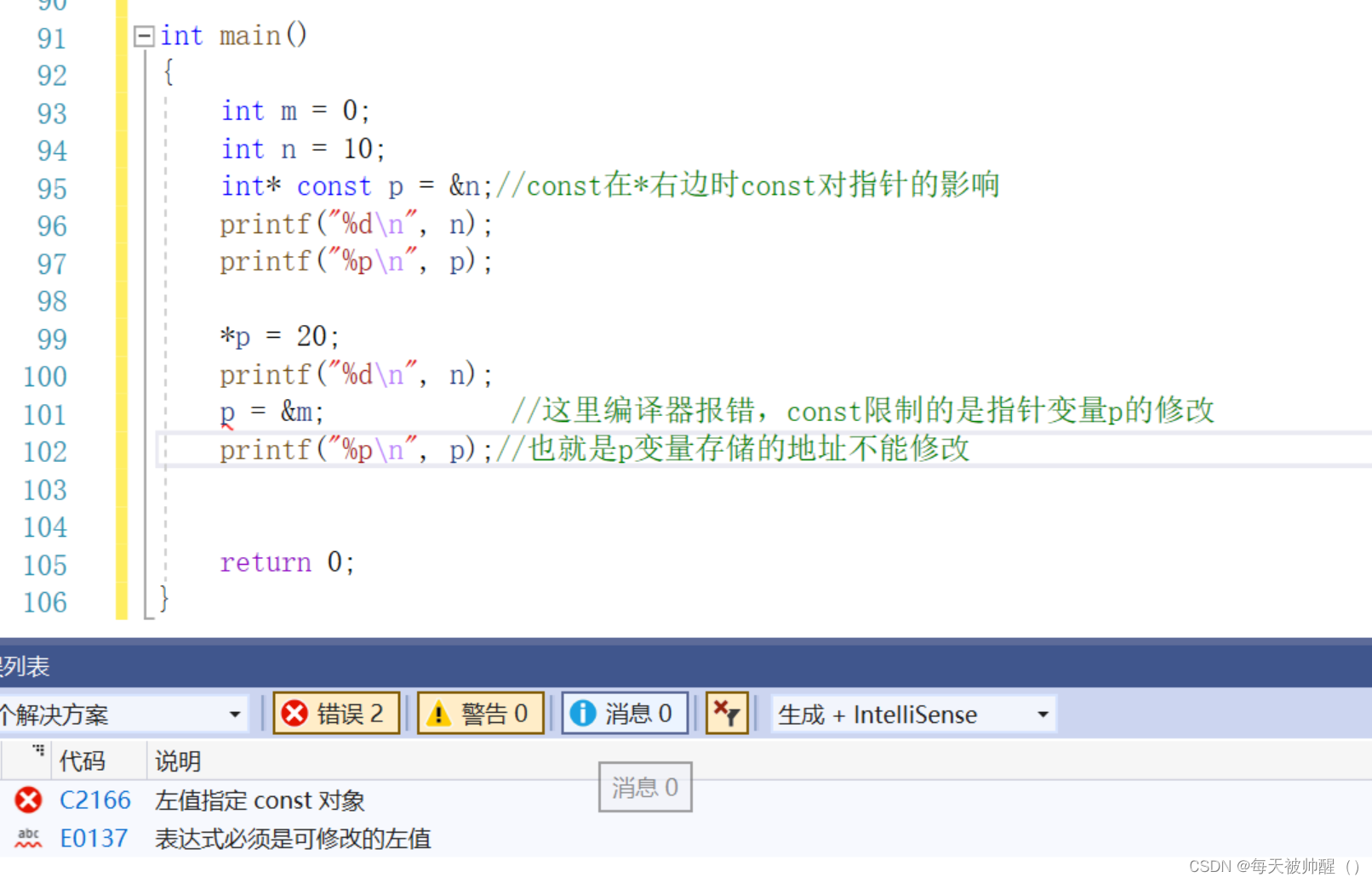
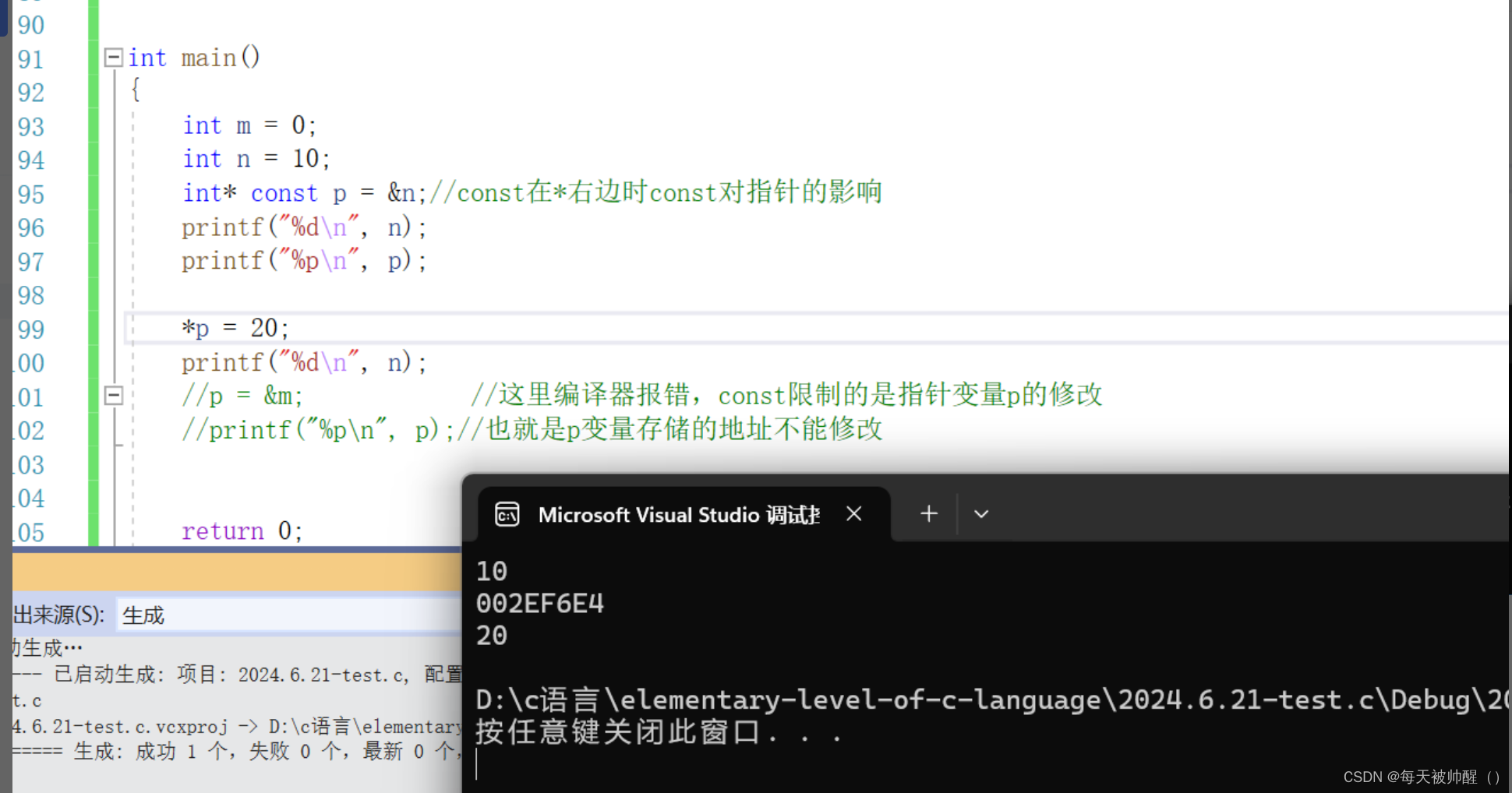
const在*右边时,const限制的是指针变量p,也就是说p变量中的地址不可变,
但是此时*p是可变的,也就可以同过解引用来该变p所存储地址所指向变量的值
练习1模拟实现strcpy函数
先来观察一下strcpy函数
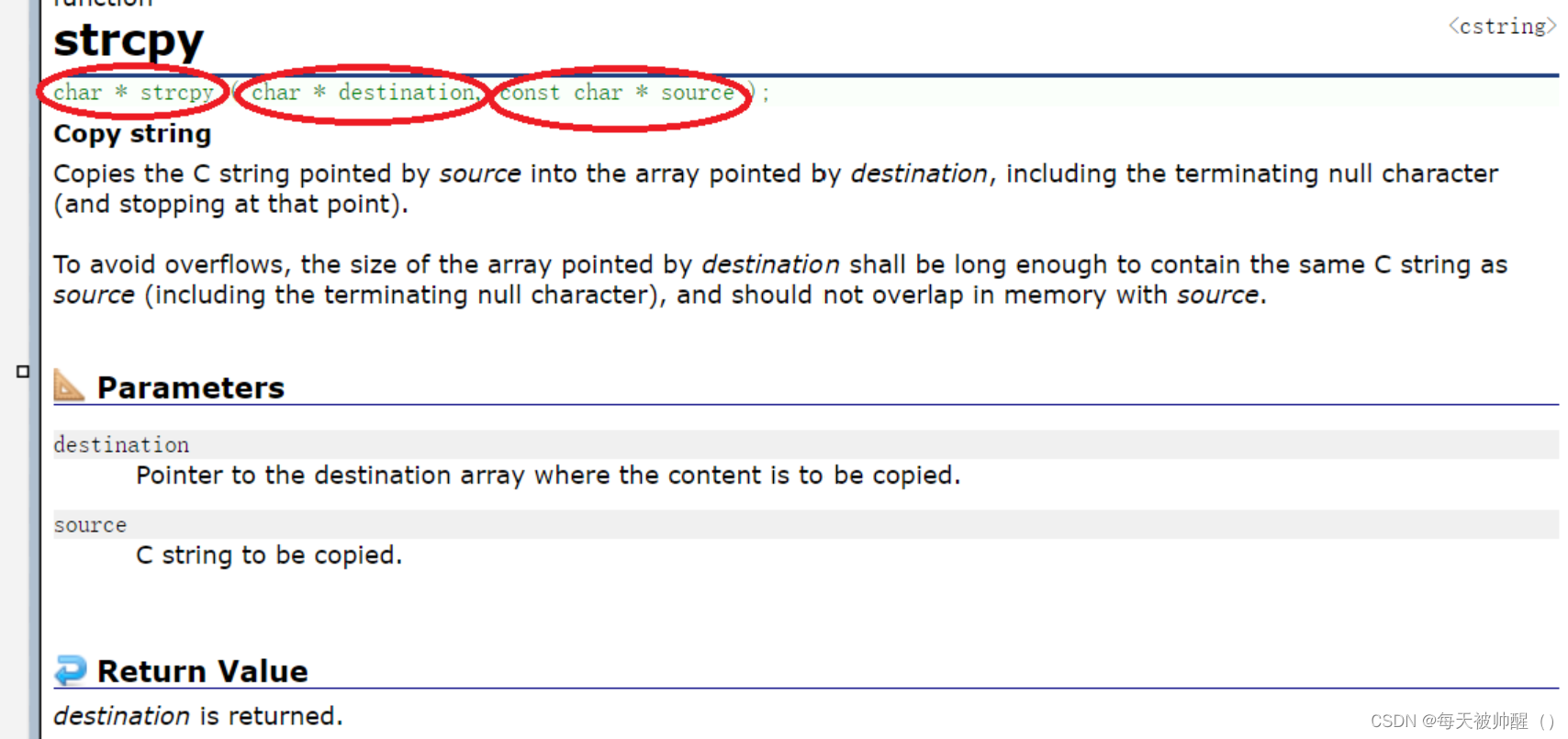
我们可以看到strcpy函数的返回类型是char*,两个形参的类型是char*,
其中传递字符串的数组是const char*,用来限制对字符串的改变
//练习1模拟实现strcpy函数
#include<assert.h>
char* My_strcpy(char* p1, const char* p2)
{
char* rst = p1;
assert(p1 != NULL);
assert(p2 != NULL);//保证传第过来的不是空指针
while (*p1++ = *p2++)//到最后*p2为'\0'时,'\0'allsc值为0,退出循环
{
;
}
return rst;
}
int main()
{
char arr1[20] = { "******************" };
char arr2[] = { "hello world" };
printf("%s\n", My_strcpy(arr1, arr2));
return 0;
}

练习2模拟实现strlen函数
先来观察一下strlen函数
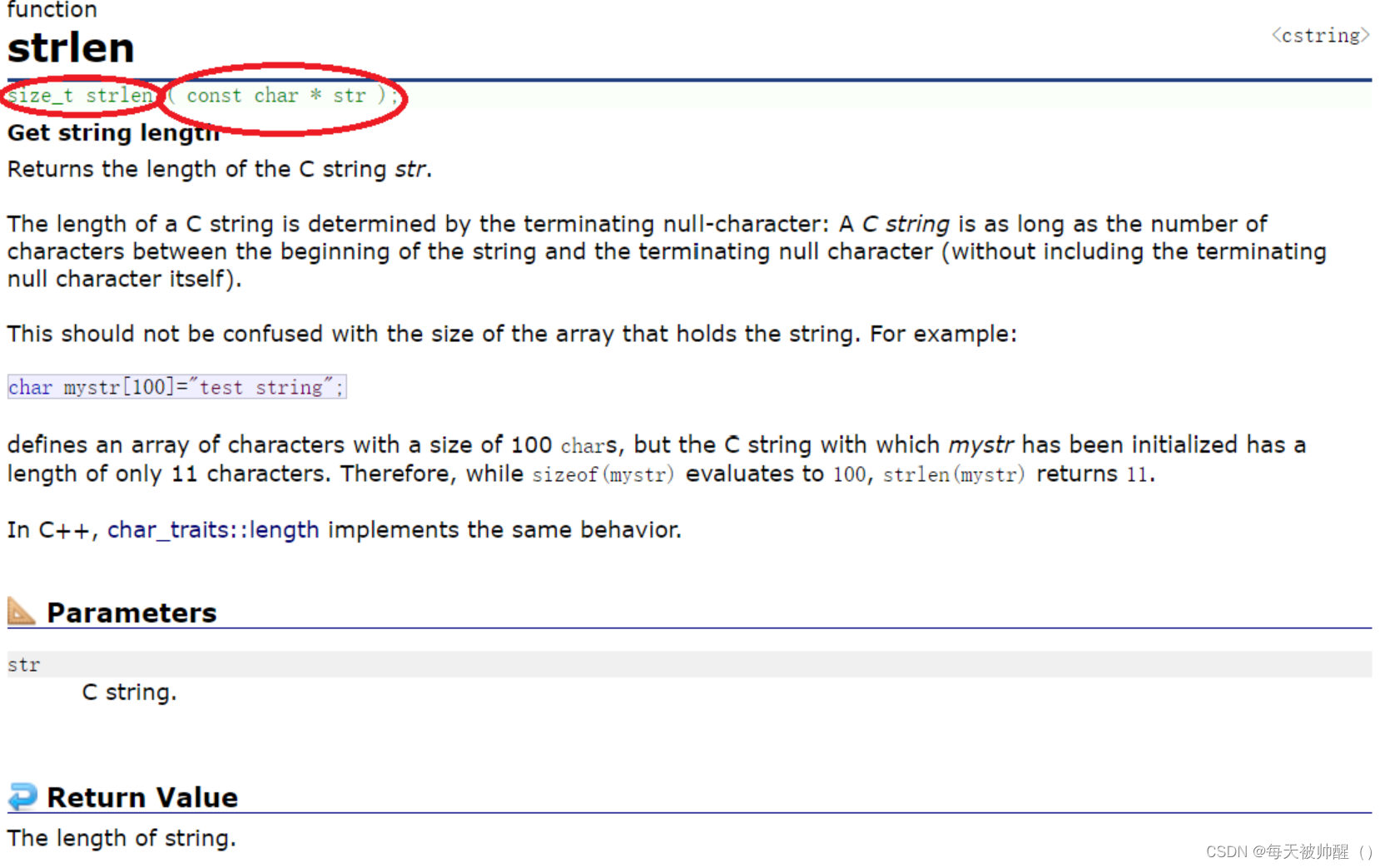
我们可以看到strlen函数的返回类型是size_t,即无符号整型,形参是用const修饰的char*
//练习二,模拟实现strlen函数
#include<assert.h>
size_t My_strlen(const char* str)//保证arr数组中的字符串不会被改变
{
assert(str != NULL);//在函数中用到函数解引用时最好断言
size_t len = 0; //保证指针的有效性
while (*str != '\0')
{
len++;
str++;
}
return len;
}
int main()
{
char arr[] = { "abcdefg" };
size_t len = My_strlen(arr);
printf("%zd\n", len);
return 0;
}















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









