







VGGnet简介
VGGnet结构
1.训练过程图形变化:

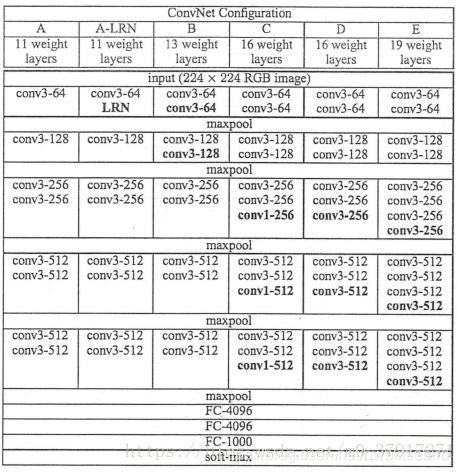
2.各级别网络结构图:vggnet探索卷积神经网络的深度与其性能之间的关系,反复堆叠3×3的小型卷积核和2×2的最大池化层。使用多个小型卷积层的好处:两个3×3的卷积层串联相当于1个5×5的卷积层,即一个像素会跟周围5×5的像素产生关联,感受野的大小为5×5。同理3个3×3的卷积层串联效果相当于1个7×7的卷积层。除此之外,参数会变少3×3×3<7×7。最重要的是,三个卷积层可以进行3次非线性转换。
VGGnet中使用的优化方法
1.在A-LRN中使用LRN层。但作用不大。
2.Multi-Scale方法做数据增强。
3.滑动窗口的卷积应用,减少不必要的重复运算。
4.1×1的卷积层,增加了线性变换。
VGGnet代码实现中的难点解析
1.tf.nn.softmax()函数:计算参数矩阵100×1000,默认传入的参数的一行为一个图片,每一列是一种可能的分类,计算在每一行上该图片是1000中分类的概率。‘
在之前的Alexnet中的softmax也定义了参数,作用是先进性一次矩阵相乘得到 照片数×可能分类数 大小的矩阵在进行分类。
综上所述,该函数只进行默认的分类操作,如想要在分类前进行softmax层上的矩阵相乘的操作,需要在传入参数之前进行计算。如下图的第二段啊代码。
# 最后一个全连接层
fc8 = fc_op(fc7_drop, name="fc8", n_out=1000, p=p)
softmax = tf.nn.softmax(fc8) # 使用softmax进行处理得到分类输出概率
```python
# softmax层
y_conv = tf.nn.softmax(tf.matmul(fc2_drop, _parameters['softmax']) + _parameters['bs'])
2.tf.nn.l2_loss():这个函数的作用是利用 L2 范数来计算张量的误差值,但是没有开方并且只取 L2 范数的值的一半,具体如下:
output = sum(t ** 2) / 2
针对最后的输出A8中的每一个数值计算平方和,这样求导时A8中的每个值都可以求得对于objective的导数,这样就可以把A8看作一个整体对objective求导。
objective = tf.nn.l2_loss(fc8)
3.tf.gradients()官方定义:
tf.gradients(
ys,
xs,
grad_ys=None,
name=‘gradients’,
stop_gradients=None,
)
1.xs和ys可以是一个张量,也可以是张量列表,tf.gradients(ys,xs) 实现的功能是求ys(如果ys是列表,那就是ys中所有元素之和)关于xs的导数(如果xs是列表,那就是xs中每一个元素分别求导),返回值是一个与xs长度相同的列表。
例如ys=[y1,y2,y3], xs=[x1,x2,x3,x4],那么tf.gradients(ys,xs)=[d(y1+y2+y3)/dx1,d(y1+y2+y3)/dx2,d(y1+y2+y3)/dx3,d(y1+y2+y3)/dx4].
2.grad_ys 是ys的加权向量列表,和ys长度相同,当grad_ys=[q1,q2,g3]时,tf.gradients(ys,xs,grad_ys)=[d(g1y1+g2y2+g3y3)/dx1,d(g1y1+g2y2+g3y3)/dx2,d(g1y1+g2y2+g3y3)/dx3,d(g1y1+g2y2+g3y3)/dx4]
所以下面这句代码,就是求p列表中的所有权值和偏执相对于objective的导数。即这里的objective就是L2正则化中的添加项,求w1-w8,b1-b8相对于它的导数。
grad = tf.gradients(objective, p)
4.评测函数中定义了一个变量num_steps_burn_in = 10,该变量的作用是给程序热身,头几轮迭代有显存的加载、cache命中等问题因此可以跳过,我们只考量10轮迭代之后的计算时间。
所以统计时间的代码块如下:在第十次之后才统计程序运行的时间,即当i为0-9时,不记录时间。
for i in range(num_batches + num_steps_burn_in):
# 记录开始时间
start_time = time.time()
# 运行目标操作,比如前向传播和后向传播
_ = session.run(target, feed_dict=feed)
# 本次运行时长
duration = time.time() - start_time
# 程序热身完成后,记录时间,0-9不计入
if i >= num_steps_burn_in:
if not i % 10: # 每10轮 显示 当前时间,迭代次数(不包括热身),用时
print('%s: step %d, duration = %.3f' % (datetime.now(), i - num_steps_burn_in, duration))
# 累加total_duration和total_duration_squared
total_duration += duration
total_duration_squared += duration * duration
完整代码
from datetime import datetime
import math
import time
import tensorflow as tf
batch_size = 16 # 一个批次的数据
num_batches = 100 # 测试一百个批次的数据
def conv_op(input_op, name, kh, kw, n_out, dh, dw, p):
"""
卷积层创建函数,并将本层参数存入参数列表
input_op:输入的tensor name:这一层的名称 kh:kernel height即卷积核的高 kw:kernel width即卷积核的宽
n_out:卷积核数量即输出通道数 dh:步长的高 dw:步长的宽 p:参数列表
"""
# 获取输入数据的通道数
n_in = input_op.get_shape()[-1]
with tf.name_scope(name) as scope:
# 卷积层参数w
kernel = tf.get_variable(scope + "w", shape=[kh, kw, n_in, n_out], dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer_conv2d())
# 卷积操作
conv = tf.nn.conv2d(input_op, kernel, (1, dh, dw, 1), padding='SAME')
# 初始化bias为0
biases = tf.Variable(tf.constant(0.0, shape=[n_out], dtype=tf.float32), name='b')
# 将卷积后结果与biases加起来
z = tf.nn.bias_add(conv, biases)
# 使用激活函数relu进行非线性处理
activation = tf.nn.relu(z, name=scope)
# 将卷积核和biases加入到参数列表
p += [kernel, biases]
return activation
def fc_op(input_op, name, n_out, p):
"""
全连接层FC创建函数
"""
# 获取input_op的通道数
n_in = input_op.get_shape()[-1]
with tf.name_scope(name) as scope:
# 全连接层参数w
kernel = tf.get_variable(scope + "w", shape=[n_in, n_out], dtype=tf.float32,
initializer=tf.contrib.layers.xavier_initializer())
# 初始化biases为0.1而不为0,避免dead neuron
biases = tf.Variable(tf.constant(0.1, shape=[n_out], dtype=tf.float32), name='b')
# 计算Z和A
activation = tf.nn.relu_layer(input_op, kernel, biases, name=scope)
# 将权重和biases加入到参数列表
p += [kernel, biases]
return activation
def mpool_op(input_op, name, kh, kw, dh, dw):
"""
最大池化层创建函数
"""
return tf.nn.max_pool(input_op,
ksize=[1, kh, kw, 1], # 池化窗口大小
strides=[1, dh, dw, 1], # 池化步长
padding='SAME',
name=name)
def inference_op(input_op, keep_prob):
"""
创建VGGNet-16-D的网络结构
input_op为输入数据,keep_prob为控制dropoout比率的一个placeholder
"""
p = []
# 卷积层1
# 第一段卷积网络第一个卷积层,输出尺寸224*224*64,卷积后通道数(厚度)由3变为64
conv1_1 = conv_op(input_op, name="conv1_1", kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)
# 第一段卷积网络第二个卷积层,输出尺寸224*224*64
conv1_2 = conv_op(conv1_1, name="conv1_2", kh=3, kw=3, n_out=64, dh=1, dw=1, p=p)
# 第一段卷积网络的最大池化层,经过池化后输出尺寸变为112*112*64
pool1 = mpool_op(conv1_2, name="pool1", kh=2, kw=2, dw=2, dh=2)
# 卷积层2
# 第二段卷积网络第一个卷积层,输出尺寸112*112*128,卷积后通道数由64变为128
conv2_1 = conv_op(pool1, name="conv2_1", kh=3, kw=3, n_out=128, dh=1, dw=1, p=p)
# 第二段卷积网络第二个卷积层,输出尺寸112*112*128
conv2_2 = conv_op(conv2_1, name="conv2_1", kh=3, kw=3, n_out=128, dh=1, dw=1, p=p)
# 第二段卷积网络的最大池化层,经过池化后输出尺寸变为56*56*128
pool2 = mpool_op(conv2_2, name="pool2", kh=2, kw=2, dw=2, dh=2)
# 卷积层3
# 第三段卷积网络第一个卷积层,输出尺寸为56*56*256,卷积后通道数由128变为256
conv3_1 = conv_op(pool2, name="conv3_1", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
# 第三段卷积网络第二个卷积层,输出尺寸为56*56*256
conv3_2 = conv_op(conv3_1, name="conv3_2", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
# 第三段卷积网络第三个卷积层,输出尺寸为56*56*256
conv3_3 = conv_op(conv3_2, name="conv3_3", kh=3, kw=3, n_out=256, dh=1, dw=1, p=p)
# 第三段卷积网络的最大池化层,池化后输出尺寸变为28*28*256
pool3 = mpool_op(conv3_3, name="pool3", kh=2, kw=2, dh=2, dw=2)
# 卷积层4
# 第四段卷积网络第一个卷积层,输出尺寸为28*28*512,卷积后通道数由256变为512
conv4_1 = conv_op(pool3, name="conv4_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 第四段卷积网络第二个卷积层,输出尺寸为28*28*512
conv4_2 = conv_op(conv4_1, name="conv4_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 第四段卷积网络第三个卷积层,输出尺寸为28*28*512
conv4_3 = conv_op(conv4_2, name="conv4_3", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 第四段卷积网络的最大池化层,池化后输出尺寸为14*14*512
pool4 = mpool_op(conv4_3, name="pool4", kh=2, kw=2, dh=2, dw=2)
# 卷积层5
# 第五段卷积网络第一个卷积层,输出尺寸为14*14*512
conv5_1 = conv_op(pool4, name="conv5_1", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 第五段卷积网络第二个卷积层,输出尺寸为14*14*512
conv5_2 = conv_op(conv5_1, name="conv5_2", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 第五段卷积网络第三个卷积层,输出尺寸为14*14*512
conv5_3 = conv_op(conv5_2, name="conv5_3", kh=3, kw=3, n_out=512, dh=1, dw=1, p=p)
# 第五段卷积网络的最大池化层,池化后尺寸为7*7*512
pool5 = mpool_op(conv5_3, name="conv5_3", kh=2, kw=2, dh=2, dw=2)
# 对卷积网络的输出结果进行扁平化,将每个样本化为一个长度为25088的一维向量
shp = pool5.get_shape()
resh1 = tf.reshape(pool5, [-1, shp[1].value * shp[2].value * shp[3].value], name="resh1")
# 全连接层
fc6 = fc_op(resh1, name="fc6", n_out=4096, p=p)
fc6_drop = tf.nn.dropout(fc6, keep_prob, name="fc6_drop") # dropout层,keep_prob数据待外部传入
fc7 = fc_op(fc6_drop, name="fc7", n_out=4096, p=p)
fc7_drop = tf.nn.dropout(fc7, keep_prob, name="fc7_drop")
# 最后一个全连接层
fc8 = fc_op(fc7_drop, name="fc8", n_out=1000, p=p)
softmax = tf.nn.softmax(fc8) # 使用softmax进行处理得到分类输出概率
predictions = tf.argmax(softmax, 1) # 求概率最大的类别
# 返回参数
return predictions, softmax, fc8, p
def time_tensorflow_run(session, target, feed, info_string):
"""
评测函数
target:需要评测的运算算字, info_string:测试的名称
"""
num_steps_burn_in = 10 # 给程序热身,头几轮迭代有显存的加载、cache命中等问题因此可以跳过,我们只考量10轮迭代之后的计算时间
total_duration = 0.0 # 总时间
total_duration_squared = 0.0 # 平方和
for i in range(num_batches + num_steps_burn_in):
# 记录开始时间
start_time = time.time()
# 运行目标操作,比如前向传播和后向传播
_ = session.run(target, feed_dict=feed)
# 本次运行时长
duration = time.time() - start_time
# 程序热身完成后,记录时间,0-9不计入
if i >= num_steps_burn_in:
if not i % 10: # 每10轮 显示 当前时间,迭代次数(不包括热身),用时
print('%s: step %d, duration = %.3f' % (datetime.now(), i - num_steps_burn_in, duration))
# 累加total_duration和total_duration_squared
total_duration += duration
total_duration_squared += duration * duration
# 循环结束后,计算每轮迭代的平均耗时mn和标准差sd,最后将结果显示出来
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn * mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %
(datetime.now(), info_string, num_batches, mn, sd))
def run_benchmaek():
"""
评测的主函数,不使用ImageNet数据集来训练,只使用随机图片测试前馈和反馈计算的耗时
"""
with tf.Graph().as_default():
image_size = 224
# 利用tf.random_normal()生成随机图片
images = tf.Variable(tf.random_normal([batch_size, # 每轮迭代的样本数
image_size, image_size, # 图片的size:image_size x image_size
3], # 图片的通道数
dtype=tf.float32,
stddev=1e-1))
# 创建keep_prob的placeholder
keep_prob = tf.placeholder(tf.float32)
predictions, softmax, fc8, p = inference_op(images, keep_prob)
# 创建Session并初始化全局参数
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# 前向计算测评
time_tensorflow_run(sess, predictions, {keep_prob: 1.0}, "Forward")
# 前向和反向计算测评
objective = tf.nn.l2_loss(fc8)
grad = tf.gradients(objective, p)
time_tensorflow_run(sess, grad, {keep_prob: 0.5}, "Forward-backward")
run_benchmaek()














 3039
3039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









