







论文:https://arxiv.org/abs/2312.03817
代码:https://diffusionillusions.com/
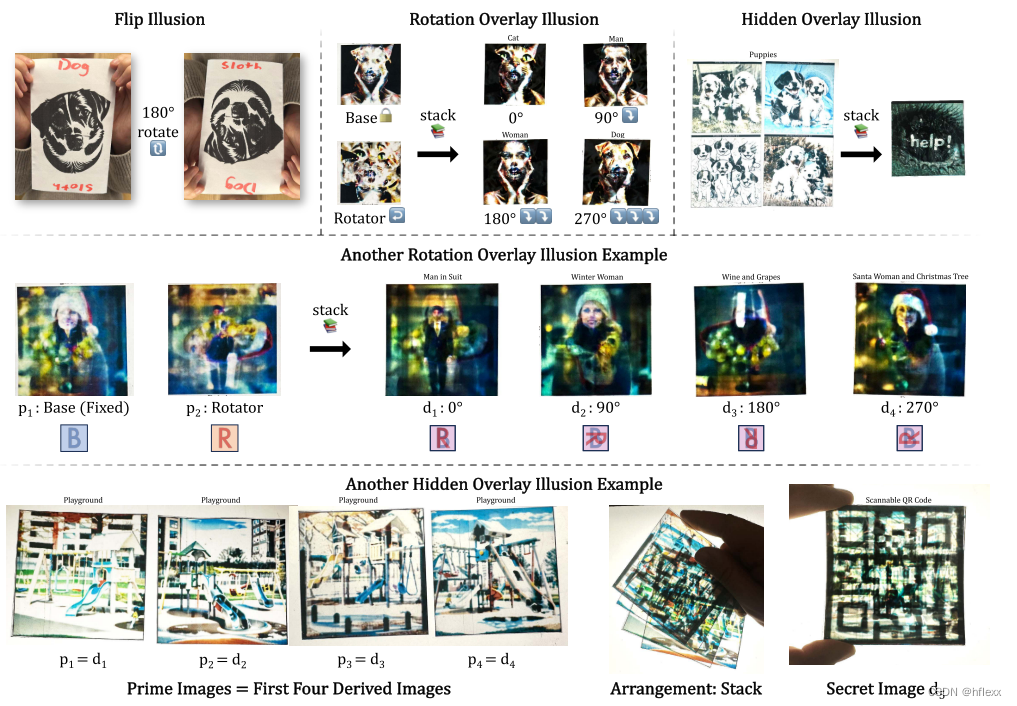
图片分析:正面朝上观看的图像似乎是一张普通的狗照片,但正面朝下观看则看起来像树懒。 四张图像,每张都显示一个日常游乐场,叠加后形成一个二维码。
First, we propose a formal definition for this problem. Next, we introduce Diffusion Illusions, the first comprehensive pipeline designed to automatically generate a wide range of these illusions. Specifically, we both adapt the existing ‘score distillation loss’ and propose a new ‘dream target loss’ to optimize a group of differentially parametrized prime images, using a frozen text-to-image diffusion model.
论文
MOTIVATION
文章的动机是探索如何使用计算方法自动生成视觉错觉。视觉错觉是一种特殊的图像,它们的解释依赖于它们是如何被排列和查看的。尽管视觉错觉有着悠久的创作和研究历史,但高保真的、逼真的错觉直到最近才成为可能,且之前没有通用的框架来生成和理解这类错觉。
CONTRIBUTION
1.为产生幻觉illusion的问题提供了第一个正式定义
2. 提出了一种形式化的通用方法,能够生成各种类型的错觉。提出了 Diffusion Illusions,一种用于生成多种类型illusions的灵活工具;
3. Dream Target Loss:引入了一种新的损失函数,用于优化图像以匹配目标描述,这在生成特定视觉错觉时特别有用。
4. 从多个方面评估计算机生成的错觉的质量,并进行全面的实验来验证我们方法的有效性;
5. 成功地在现实世界中制造了生成的图像及其相应的幻象。
related works分析与讲解
Computationally-generated illusions
- Hybrid images
混合图像是通过将一幅图像的低频特征与另一幅图像的高频特征相结合而从两幅图像创建的。 观看者从远处观看混合图像时从低频图像中看到物体,而在近距离观看时从高频图像中看到物体。 虽然此过程可能是自动化的,但作者指出,为了获得最佳结果,应手动对齐低频和高频图像的整体形状。 - multi-view wire art
当从不同角度观看时,它们会被解释为不同的物体。 在多视图线艺术中,可以从多个角度观看或照亮单个3D线以获得不同的干净线条图; 在依赖于视点的表面中,可以从不同角度观察彩色3D打印高度场以获得不同的彩色图像。 - steganography
其中看似正常的物体可以以特定的方式查看以揭示隐藏的含义
Dream Fusion
DreamFusion 中引入的分数蒸馏是一种基础技术,可以在任意参数空间中优化样本,而无需通过扩散模型进行反向传播。 我们利用这些技术构建了一个新的幻觉生成框架。
FFN:傅里叶特征网络
SDEdit
随机微分编辑(Stochastic Differential Editing,SDEdit),通过随机微分方程(stochastic differential equation,SDE)迭代去噪来合成逼真的图像。给定一个带有用户指引(以操纵 RGB 像素的形式)的输入图像,SDEdit 首先向输入添加噪声,然后通过 SDE 先验迭代去噪生成的图像,以增加其逼真性。SDEdit 不需要任务特定的训练或反演,并且可以自然地实现逼真性和忠实性之间的平衡。
给定带有用户指南输入的输入图像,例如笔画或带有笔画编辑的图像,作者添加适当数量的噪声来平滑不需要的伪影和扭曲(例如,笔画像素上的不自然细节),同时仍然保留输入用户指南的整体结构。然后,作者用这个有噪声的输入初始化SDE,并逐步去除噪声,以获得既真实又忠实于用户指导输入的去噪结果。
METHODS
问题陈述
我们将错觉定义为当一组称为主图像 p p p 的物理图像以多种方式查看或排列时发生的情况,每种排列都会产生一个独特的感知图像,称为派生图像 d d d,它代表特定的对象或 场景。
illusion:当一组称为原始图像(prime images)的物理图像 p p p以多种方式查看或排列时发生的情况。每种排列都会产生一个独特的感知图像(perceived image),称为派生图像(derived image) d d d,它代表特定的对象或场景。
- p p p:prime images, a set of physical images called prime images.指那些将被用来通过某种排列或操作产生视觉错觉的原始图像
- d d d:derived image.指通过排列和操作基础图像后得到的图像,它们是观察者最终看到的图像,能够触发视觉错觉。
illusion process:感知错觉的生成过程
- P P P:some prime image space P P P.这是一个代表可以物理实现的视觉刺激的图像空间。基础图像(prime images)是指那些将被用来通过某种排列或操作产生视觉错觉的原始图像。
- D D D:这是代表人类观察者视角下的场景的图像空间。衍生图像(derived images)是指通过排列和操作基础图像后得到的图像,它们是观察者最终看到的图像,能够触发视觉错觉。
- a Tuple of n Prime Images: p 1 , p 2 , p 3 . . . p n , p i ∈ P {p_1,p_2,p_3...p_n},p_i∈P p1,p2,p3...pn,pi∈P,一个包含n个基础图像的元组,每个 p i p_i pi都属于图像空间 P P P。这些图像是构成视觉错觉的起点。
- a tuple of m arrangement operations A: a 1 , a 2 , . . . . a m , a j : P n ⇒ D {a_1,a_2,....a_m},a_j:P ^ n \Rightarrow D a1,a2,....am,aj:Pn⇒D,一个包含m个排列操作的元组,表示为 a 1 , a 2 , . . . . a m {a_1,a_2,....a_m} a1,a2,....am,其中每个 a j a_j aj都是一个从基础图像空间的 n n n维到衍生图像空间的函数.这些操作定义了如何将基础图像排列或转换成单一的衍生图像。 A A A的目的是对一组原始图像(包括单元素集)进行操作并产生独特的输出,即派生图像。
- Tuple of Derived Images:每个排列操作 a j a_j aj都将所有的基础图像以某种方式操作,以获得一个单一的衍生图像 d j d_j dj。最终,illusion由m个衍生图像的元组构成,表示为 d 1 , d 2 , . . . , d m {d_1, d_2, ..., d_m} d1,d2,...,dm,其中每个 d j d_j dj都属于图像空间 D D D。这些衍生图像是错觉的最终输出,它们代表了不同的观察角度或条件下的视觉效果。 d i = a i ( P ) d_i=a_i(P) di=ai(P)
DIffusion illusion

架构中:训练组件以蓝色显示,中间变量以红色显示,不可训练函数以白色显示,输入以绿色显示。
-
扩散网络提供两种不同的损失信号,将派生图像(prime images)拉向文本提示。
-
每个训练步骤仅计算一个损失信号,即Score Distillation Loss或 Dream Target Loss。
-
派生图像上的梯度通过 the arrangement operations and prime images反向传播到傅里叶特征网络的参数。 通过扩散网络不会发生反向传播。
-
the Diffusion Illusions pipeline consists of:
- a set of prime images parameterized by θ ( P ) θ(P) θ(P),一组基础图像
- a set of specific arrangement processes ( A A A, that derive images from all primes),一组特定的排列过程
- a frozen text-to-image diffusion model ( F F F)一个冻结的文本到图像的扩散模型
Prime Images
-
基础图像的尺寸和颜色表示:
这些基础图像在框架中被表示为512×512像素的RGB图像,即每个图像有512像素宽、512像素高,并且使用三个颜色通道(红色、绿色、蓝色)来表示颜色信息。数学上,这可以表示为P ≃ R(512,512,3),其中P代表基础图像空间,R表示实数集。 -
使用傅里叶特征网络(Fourier Features Networks, FFN):
与直接在像素空间中表示图像不同,文章采用了FFN来以参数化形式表示基础图像。这种方法允许以更紧凑和更高效的方式来表示图像,并且可以更容易地进行数学操作。 -
多层感知器(MLP)网络的使用:
每个基础图像由一个单独的MLP网络的可学习权重表示。MLP网络是一种常见的神经网络结构,它通过一组神经元对输入数据进行线性或非线性映射。在这种情况下,MLP网络将图像空间坐标映射到相应的RGB值,形成一个隐式图像表示。这意味着图像不是直接以像素数据存储,而是以能够生成这些像素数据的网络权重的形式存储。 -
FFN的优势:
FFN通常可以更好地处理图像的高频信息,并且在打印和物理实现过程中更为稳健。此外,FFN可以减少图像之间的相互干扰,使得每个基础图像能够更独立地表示,同时在特定排列下产生所需的错觉效果。
Arrangement Processes
A A A 的目的是对一组原始图像prime images(包括单元素集)进行操作并产生独特的输出,即派生图像。 d i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









