







Style Injection in Diffusion: A Training-free Approach for Adapting Large-scale Diffusion Models for Style Transfer-CVPR2024HighLight
代码:https://github.com/jiwoogit/StyleID
论文:https://jiwoogit.github.io/StyleID_site/

为了解决风格迁移时在推理阶段微调非常耗时的问题,提出操纵自注意力层的特征作为交叉注意力机制的工作方式,目标是通过利用预训练的大规模文本到图像扩散模型的生成能力来解决艺术风格迁移.在生成过程中,用风格形象的key和value来替代内容的key和value。 此外,引入查询保存和注意力温度缩放来减轻原始内容中断的问题,并引入初始潜在自适应实例归一化(AdaIN)来处理不和谐的颜色(未能传输样式颜色)。 实验结果表明,所提出的方法在传统和基于扩散的风格转移基线方面都超越了最先进的方法。
MOTIVATION
-
基于扩散模型(Diffusion Models, DM)的风格迁移的一般方法及其局限性:
- 一般方法利用预训练的扩散模型的生成能力来进行风格迁移。一些研究专注于显式解耦风格和内容,以实现可解释和可控的风格迁移。其他一些研究专注于将风格图像反转(invert)到大规模文本到图像扩散模型的文本潜在空间中。
- 这些方法通常需要对每个风格图像进行基于梯度的优化(fine-tuning)和文本反转(在推理阶段(inference-stage),这是一个耗时的过程。
- DiffStyle是一种无需训练的风格迁移方法,它避免了耗时的优化步骤。然而DiffStyle被认为难以应用于潜在扩散模型(Latent Diffusion Model, LDM),这限制了用户利用大规模模型的显著生成能力,因为DiffStyle无法很好地与这些模型集成。
-
将免训练风格迁移扩展到大规模预训练 DM 上的应用
- Plug-and-play表明,残差块和自注意力(SA)的attention map决定了生成图像的空间布局
- Prompt-to-Prompt通过替换从文本提示中获得的交叉注意(CA)的键和值来本地编辑图像,同时保留其原始注意图。这说明了交叉注意力的键和值可以调整填充图像内容的方式。
- 所有这些工作都表明:1)attention maps决定空间布局,2)CA(交叉注意力) 的键和值调整要填充的内容。
-
相应启发:认为 SA 层是转移风格的有效方法。
- 与 CA 类似,替换 SA 的key和value(用style图像的value和value替contern 图像的key和value),将特定图像的风格(textures)与不同图像的内容(semantics and spatial layout)结合起来。

- 与 CA 类似,替换 SA 的key和value(用style图像的value和value替contern 图像的key和value),将特定图像的风格(textures)与不同图像的内容(semantics and spatial layout)结合起来。
-
此外,强调 SA 层在有风格迁移的特性:
-
语义相似性的保持:在基于SA的风格迁移中,内容图像的patches(查询,query)如果具有语义上的相似性,它们会与相似的风格(键,key)相互作用。这意味着,即使在风格迁移之后,这些内容图像区域之间的关系仍然得以保持。这有助于保持图像内容的完整性和语义连贯性。也就是说,采用 SA 的风格迁移可以保留原始内容,因为具有相似性的内容块往往会从相应的风格图像块接收相似的注意力分数。

-
强大的特征表示能力:由于大规模扩散模型(Diffusion Model, DM)具有强大的特征表示能力,content image对应的每个查询区域(each patch of the query)都能与具有相似纹理和语义的键(key)建立更高的相似性。换句话说,内容图像中的每个小区域都能够在风格图像中找到具有相似纹理和语义的对应区域,这种相似性有助于模型在进行风格迁移时更好地保留内容图像的语义信息,并根据风格图像的纹理特征进行调整。这种特性允许模型更精确地识别和迁移与内容图像区域相匹配的风格特征。这种相似性鼓励模型基于内容和风格图像之间局部纹理(例如边缘)的相似性来进行风格迁移。

-
CONTRIBUTION
- 提出了一种风格迁移方法,通过对自注意力特征的简单操作来利用大规模预训练的 DM; 用样式替换内容的键和值,无需任何优化或监督(例如文本)。
- 通过提出三个组件进一步改进风格迁移的朴素方法,以正确适应风格; 查询保存(query preservation)、注意力温度缩放(attention temperature scaling)和初始潜在 AdaIN(initial latent AdaIN)。
- 对风格迁移数据集的大量实验验证了所提出的方法显着优于以前的方法并实现了最先进的性能。
RELATED WORKS
Diffusion Model-based Neural Style Transfer
- InST 引入了一种基于文本反转的方法,旨在将给定的风格映射到相应的文本嵌入。
- StyleDiffusion旨在通过引入基于CLIP的风格分离损失来解耦风格和内容,并微调DM以进行风格迁移。
- DiffStyle 提出了一种免训练的风格转移方法,该方法利用 h-space并调整跳跃连接(skip connections),分别有效地传达风格和内容信息。 然而,当 DiffStyle 应用于稳定扩散SD时,它们的行为与典型的风格转移方法有很大不同; 不仅纹理也发生了变化,空间布局等语义也发生了变化。
Attention-based Image Editing in DM
预训练的文本到图像扩散模型在图像编辑方面取得了显著进展,这些模型被广泛用于各种图像编辑任务。
- Prompt-to-Prompt方法:
- 提出了一种基于文本的局部图像编辑方法,通过操纵交叉注意力(cross-attention)图来实现。
- 该方法观察到交叉注意力在建立图像空间布局与文本提示中每个词之间的关系方面起着重要作用。
- Prompt-to-Prompt在保持注意力图的同时改变交叉注意力(CA)的文本条件。 由于注意力图影响输出的空间布局,替换的文本条件决定了在生成的图像中绘制什么,这些条件实际上是 CA 中的键和值。通过替换原始文本和交叉注意力图为期望的版本,可以获得与文本条件匹配的编辑图像。
- Plug-and-play方法:
- “Plug-and-play”引入了一种文本引导的图像到图像翻译方法。
- 发现空间特征(即来自残差块的特征)和自注意力图决定了合成图像的空间布局。
- 在给定文本条件下生成新图像时,使用原始图像的特征和注意力图引导扩散模型,以保留原始的空间布局。
- MasaCtrl方法:
- “MasaCtrl”提出了一种使用文本提示进行一致性图像编辑的相互自注意力控制方法。
- 该方法保留了源图像自注意力层的键和值,同时用期望的文本提示对模型进行条件化。
LDM(Latent Diffusion Model)
潜在扩散模型(LDM)是一种在低维潜在空间中训练的扩散模型,目的是聚焦于数据的语义比特,降低计算成本。其利用预先训练的编码器encoder,将数据集中的全部图像编码为潜在空间 z中的表示。并在潜在空间 z上训练扩散模型,训练时需要预测在时间步t时潜在表示
z
t
z_t
zt对应的噪声
ϵ
\epsilon
ϵ。文本利用stable diffusion:
L
L
D
M
=
E
z
,
ϵ
,
t
[
∥
ϵ
−
ϵ
θ
(
z
t
,
t
,
y
)
∥
2
2
]
,
L_{\mathrm{LDM}}=\mathbb{E}_{z,\epsilon,t}[\|\epsilon-\epsilon_\theta(z_t,t,y)\|_2^2],
LLDM=Ez,ϵ,t[∥ϵ−ϵθ(zt,t,y)∥22],
- ϵ∈N(0,1)是噪声
- 在给定图像 x ∈ R x∈R%{h×W×3} x∈R的情况下,编码器E将x编码为潜在表示 z ∈ R h × w × c z∈R^{h×w×c} z∈Rh×w×c,并且解码器从潜在表示重建图像。
- t是从{1,…,T}均匀采样的时间步数
- y是条件,即文本
- ϵ θ ϵ_θ ϵθ是预测加到上的噪声的unet神经网络,每个block for each resolution依次包括残差块、自我注意块(SA)和交叉注意块(CA)
自注意力快
重点关注利用 SA 块(自注意力机制块)来传输style:
Q
=
W
Q
(
ϕ
)
,
K
=
W
K
(
ϕ
)
,
V
=
W
V
(
ϕ
)
,
ϕ
o
u
t
=
A
t
t
n
(
Q
,
K
,
V
)
=
s
o
f
t
m
a
x
(
Q
K
T
d
)
⋅
V
,
Q=W_{Q}(\phi),K=W_{K}(\phi),V=W_{V}(\phi),\\\phi_{\mathrm{out}}=\mathrm{Attn}(Q,K,V)=\mathrm{softmax}(\frac{QK^{T}}{\sqrt{d}})\cdot V,
Q=WQ(ϕ),K=WK(ϕ),V=WV(ϕ),ϕout=Attn(Q,K,V)=softmax(dQKT)⋅V,
- ϕ {\phi} ϕ:残差快residual后面的特征
- d:投影query的维度
- W(.):投影层
- y:我们不使用任何文本提示,y始终是空文本提示" "
- ϕ o u t {\phi}_{out} ϕout:每个位置的注意力权重
METHODS

Attention-based Style Injection
输入风格
启发与方法:
- 从“Prompt-to-Prompt”获得启发,文章提出一种操作自注意力层(SA)的方法,类似于交叉注意力(CA)。
- 将风格图像 I s I_s Is 的特征作为条件,通过在生成过程中替换内容图像的键和值,实现风格图像纹理向内容图像的迁移。
潜在特征获取:
- 使用DDIM(Denoising Diffusion Implicit Models)反演技术来获取内容和风格图像的潜在特征,在反演过程中,收集风格图像的自注意力层特征。
- 定义从
t
=
0
t=0
t=0到
t
=
T
t=T
t=T 的时间步长集合,用于描述图像从清晰状态
z
c
0
z_c^0
zc0和
z
s
0
z_s^0
zs0(内容图像和风格图像)逐步转化为
t
=
T
t=T
t=T时的高斯噪声的扩散过程特征收集.在正向过程的每个时间步
t
t
t收集内容图像的查询特征
Q
c
t
Q_c^t
Qct和风格图像的键和值特征
K
s
t
,
V
s
t
K_s^t, V_s^t
Kst,Vst

风格注入:
- 通过复制内容潜在噪声 z T c z_T^c zTc 来将风格化处理后的潜在噪声 (stylized latent noise) z T c s z_T^{cs} zTcs初始化.
- 在 z t c s z_t^{cs} ztcs逆扩散过程,将风格图像的键 K s t K_s^t Kst和值 V s t V_s^t Vst 注入到自注意力层,替代原有的键 K c s t K_{cs}^t Kcst和值 V c s t V_{cs}^t Vcst。
内容干扰问题以及查询保留
原因:仅替换键和值可能导致内容干扰( content disruption).因为随着逆扩散过程的进行,注意力值的变化会逐步改变风格化潜在表示的内容,由于注意力值的变化,原始内容的关键信息可能会逐渐丢失,导致生成的图像内容与原始图像内容有所不同。

实现:混合风格后化的潜在表示的query和内容图像的query
Q ~ t c s = γ × Q t c + ( 1 − γ ) × Q t c s , ϕ o u t c s = A t t n ( Q ~ t c s , K t s , V t s ) , \tilde{Q}_{t}^{cs}=\gamma\times Q_{t}^{c}+(1-\gamma)\times Q_{t}^{cs},\\ \phi_{\mathrm{out}}^{\mathrm{cs}}=\mathrm{Attn}(\tilde{Q}_{t}^{cs},K_{t}^{s},V_{t}^{s}), Q~tcs=γ×Qtc+(1−γ)×Qtcs,ϕoutcs=Attn(Q~tcs,Kts,Vts),
- Q c s t Q_{cs}^t Qcst:风格化处理后的的潜在表示的query
- Q c t Q_c^t Qct: 内容图像的query
- γ \gamma γ :一个介于 0 到 1 之间的混合比例参数,通过调整 γ \gamma γ的值,可以控制风格迁移的程度。较高的 γ \gamma γ值会保留更多的原始内容信息,而较低的 γ \gamma γ值会加强风格迁移的效果
- ϕ o u t \phi_{\mathrm{out}} ϕout:自注意力计算的输出
- 将这些操作应用于与局部纹理相关的解码器的后面层(SD 中的第 7-2 个解码器层)。
Attention Temperature Scaling
注意力图是通过查询(query)和键(key)特征之间的缩放点积来计算的。
- 在训练期间,SA层中的查询和键特征来自同一图像,因此它们之间的相似性很高。
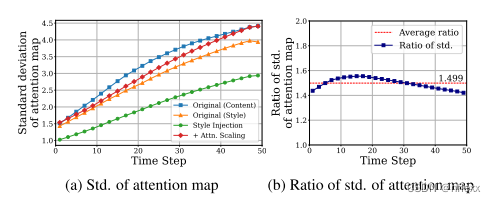
- 在风格迁移中,如果用风格图像的键特征替换内容图像的键特征,由于风格和内容很可能是不相关的,整体相似性会降低。这会导致计算出的注意力图变得模糊或平滑,从而使输出图像变得不清晰,这对于同时捕捉内容和风格信息是不利的。
为了解决这个问题,作者测量了注意力图的标准差,同时消除了基于注意力的风格注入。
-
计算在应用 softmax 之前的attention map,即计算查询和键之间的缩放点积,以得到注意力图,实验验证了这种风格注入往往会降低整个时间步上注意力图的标准差
-
为了更清晰地校正注意力图,我们引入了注意力温度缩放参数。 具体来说,我们将进行softmax之前的注意力图(attention map)乘以大于1的恒定温度缩放参数τ:
-
A t t n τ ( Q t c s ~ , K t s , V t s ) = s o f t m a x ( τ Q t c s ~ ( K t s ) T d ) ⋅ V t s , τ > 1 \mathrm{Attn}_{\tau}(\tilde{Q_{t}^{cs}},K_{t}^{s},V_{t}^{s})=\mathrm{softmax}(\frac{\tau \tilde{Q_{t}^{cs}}(K_{t}^{s})^{T}}{\sqrt{d}})\cdot V_{t}^{s},\tau>1 Attnτ(Qtcs~,Kts,Vts)=softmax(dτQtcs~(Kts)T)⋅Vts,τ>1
-
使用 τ = 1.5 作为默认设置,这是整个时间步长的平均比率。 如图 (b) 所示,确认它有效地校准了注意力图的标准差,使其与其原始值相似.softmax之后的注意力图将比其原始值更清晰
-
Initial Latent AdaIN
仅使用基于注意力的样式注入进行的样式迁移通常无法捕获给定样式的色调。
- 图5(a)表示:纹理和局部图案成功转移到内容图像,同时内容图像的色调仍然保留。

- 图5(b)表示即使注入样式的查询、键和值,生成的图像仍然保留内容的色调。(为了确定 SA 中每个特征对色调的影响,还在样式注入过程中添加了query。 然而,色调仍然与内容相似,因此自注意力特征对色调的影响较小)

分析了 DM 的另一个重要部分:initial latent noise
- 扩散模型在合成纯白色或黑色图像时存在困难,倾向于生成具有中等颜色的图像,因为初始噪声是从均值为零、方差为单位的正态分布中采样的。
- 因此假设初始噪声的统计数据对生成图像的颜色和亮度有很大影响。
为了利用两种初始潜在(initial latents)中的有价值信息,作者采用AdaIN(自适应实例归一化)来调节初始潜在,以有效传递色调信息。
z T c s = σ ( z T s ) ( z T c − μ ( z T c ) σ ( z T c ) ) + μ ( z T s ) , z_T^{cs}=\sigma(z_T^s)\left(\frac{z_T^c-\mu(z_T^c)}{\sigma(z_T^c)}\right)+\mu(z_T^s), zTcs=σ(zTs)(σ(zTc)zTc−μ(zTc))+μ(zTs),
- AdaIN通过调整初始潜在的通道均值和标准差来实现颜色风格的迁移
- 若尝试直接从 Z s T Z_s^T ZsT生成图像,合成结果的结构信息也会跟随风格图像,丢失内容的结构。
- μ(⋅) 和 σ(⋅) :分别表示通道级别的均值(channel-wise mean)和标准差
- 通过AdaIN处理后的初始潜在 z c s T z_{cs}^T zcsT 保留了内容信息 z c T z_c^T zcT,同时使通道均值和标准差与风格图像 z s T z_s^T zsT对齐。
Experiment
实验设置
作者在LAION数据集上使用了Stable Diffusion 1.4预训练模型,并采用了DDIM采样方法,总共进行了50个时间步(t = {1, …, 50})的迭代。于超参数的默认设置,作者使用了γ = 0.75和τ = 1.5。
评估协议
AIGC常见图像质量评估可以跳转到这篇博客~
AIGC-常见图像质量评估MSE、PSNR、SSIM、LPIPS、FID、CSFD,余弦相似度
ArtFID
为了避免传统风格迁移方法可能过度拟合 Style Loss 的问题,作者采用了 ArtFID 作为评估指标,它综合考虑了内容和风格的保持,并与人类判断高度一致。
A r t F I D = ( 1 + L P I P S ) ⋅ ( 1 + F I D ) ArtFID = (1 + LPIPS) · (1 + FID) ArtFID=(1+LPIPS)⋅(1+FID)
-
LPIPS 测量风格化图像和相应内容图像之间的内容保真度
- Learned Perceptual Image Patch Similarity 学习感知图像块相似度,LPIPS是一种衡量图像感知相似性的指标,它通过比较图像块的深层特征来工作,这些特征能够捕捉到人类视觉系统中对图像质量的感知。
- LPIPS的值越低表示两张图像越相似,反之,则差异越大
-
d
(
x
,
x
0
)
=
∑
l
1
H
l
W
l
∑
h
,
w
∣
∣
w
l
⊙
(
y
^
h
w
l
−
y
^
0
h
w
l
)
∣
∣
2
2
d(x,x_0)=\sum_l\frac1{H_lW_l}\sum_{h,w}||w_l\odot(\hat{y}_{hw}^l-\hat{y}_{0hw}^l)||_2^2
d(x,x0)=∑lHlWl1∑h,w∣∣wl⊙(y^hwl−y^0hwl)∣∣22
- d d d: x , x 0 x,x_0 x,x0之间的距离
- 从 l l l层提取特征堆(feature stack)并在通道维度中进行单位规格化(unit-normalize)。
- 利用向量 W l W_l Wl来放缩激活通道数,最终计算 L 2 L_2 L2距离。
- 最后在空间上平均,在通道上求和。
-
FID 评估风格化图像和相应风格图像之间的风格保真度
- F I D = ∥ μ r − μ g ∥ 2 2 + T r ( Σ r + Σ g − 2 ( Σ r Σ g ) 1 / 2 ) \mathrm{FID}=\|\mu_r-\mu_g\|_2^2+\mathrm{Tr}(\Sigma_r+\Sigma_g-2(\Sigma_r\Sigma_g)^{1/2}) FID=∥μr−μg∥22+Tr(Σr+Σg−2(ΣrΣg)1/2)
- FID得分越低,表示生成图像的特征分布与真实图像的特征分布越接近,即生成模型的性能越好。
- FID能够捕捉到图像的全局风格和分布特性
dataset
使用 MSCOCO 数据集的内容图像和 WikiArt 数据集的风格图像进行评估。 所有输入图像均经过中心裁剪,分辨率为 512 × 512。 此外,为了进行定量比较,从每个数据集中随机选择 20 个内容图像和 40 个风格图像,产生 800 个风格化图像,如 StyTR2所做的那样。
Content Feature Structural Distance-CFSD内容特征结构距离
在风格迁移评估中,内容保真度通常依赖于LPIPS距离,该指标使用了在ImageNet数据集上预训练的AlexNet模型的特征空间,这使得LPIPS对纹理有偏见。图像的风格信息可能会影响LPIPS分数,因为它偏向于纹理特征。为了减少风格信息对评估的影响,作者引入了CFSD,这是一种只考虑图像块之间空间相关性的新距离度量。
CFSD的计算步骤:
- 获取特征图:对于给定图像 I I I,首先获取特征图 F ∈ R h × w × c F \in \mathbb{R}^{h \times w \times c} F∈Rh×w×c,这是VGG19网络中conv3层的输出特征。
- 计算相似性矩阵:计算特征图 F F F中每对特征之间的相似性,得到相似性矩阵 M = F × F T M = F \times F^T M=F×FT,其中 M ∈ R h × w × h × w M \in \mathbb{R}^{h \times w \times h \times w} M∈Rh×w×h×w。
- 应用softmax操作:对相似性矩阵 M M M 的每个元素应用softmax操作,将其建模为概率分布,得到相关性矩阵 S = [ softmax ( M i ) ] h × w i = 1 S = [\text{softmax}(M_i)]_{h \times w}^{i=1} S=[softmax(Mi)]h×wi=1,其中 M i ∈ R 1 × h × w M_i \in \mathbb{R}^{1 \times h \times w} Mi∈R1×h×w 是第 i i i 个图像块与其他块的相似性。
- 计算KL散度:CFSD定义为两个相关性矩阵之间的Kullback-Leibler散度(KL-divergence)。
CFSD公式:
C F S D = 1 h w ∑ i = 1 h w D K L ( S i c ∣ ∣ S i c s ) , \mathrm{CFSD}=\frac{1}{hw}\sum_{i=1}^{hw}D_{\mathrm{KL}}(S_{i}^{c}||S_{i}^{cs}), CFSD=hw1i=1∑hwDKL(Sic∣∣Sics),
- S i c S_{i}^{c} Sic:内容图像对应的相关性矩阵的第i个元素,这些矩阵是通过计算图像特征图(例如,VGG19网络的conv3层输出)中每对特征之间的相似性得到的。
- S i c s S_{i}^{cs} Sics:风格图像对应的相关性矩阵的第i个元素
- D K L D_{KL} DKL:KL散度
#F:\AIGCprojects\StyleID\evaluation\eval_artfid.py
def compute_patch_simi(path_to_stylized, path_to_content, batch_size, device, num_workers=1):
"""Computes the distance for the given paths.
Args:
path_to_stylized (str): Path to the stylized images.
path_to_style (str): Path to the style images. [注:这里应该为 path_to_content,修正为 path_to_content]
batch_size (int): Batch size for computing activations.
content_metric (str): Metric to use for content distance. Choices: 'lpips', 'vgg', 'alexnet' [注:缺少 content_metric 参数]
device (str): Device for computing activations.
num_workers (int): Number of threads for data loading.
Returns:
(float) FID value. [注:文档中写的是 FID value,但函数名为 compute_patch_simi,可能存在混淆,需要核对和确认]
"""
device = torch.device('cuda') if device == 'cuda' and torch.cuda.is_available() else torch.device('cpu')
# 根据路径获取图像路径并排序以匹配样式化图像与对应的内容图像
stylized_image_paths = get_image_paths(path_to_stylized, sort=True)
content_image_paths = get_image_paths(path_to_content, sort=True)
# 确保样式化图像和内容图像数量相等
assert len(stylized_image_paths) == len(content_image_paths), 'Number of stylized images and number of content images must be equal.'
# 定义图像转换方法
style_transforms = ToTensor()
# 创建样式化图像的数据集和数据加载器
dataset_stylized = ImagePathDataset(stylized_image_paths, transforms=style_transforms)
dataloader_stylized = torch.utils.data.DataLoader(dataset_stylized,
batch_size=batch_size,
shuffle=False,
drop_last=False,
num_workers=num_workers)
# 创建内容图像的数据集和数据加载器
dataset_content = ImagePathDataset(content_image_paths, transforms=style_transforms)
dataloader_content = torch.utils.data.DataLoader(dataset_content,
batch_size=batch_size,
shuffle=False,
drop_last=False,
num_workers=num_workers)
# 初始化用于计算距离的度量类
metric = image_metrics.PatchSimi(device=device).to(device)
dist_sum = 0.0
N = 0
pbar = tqdm(total=len(stylized_image_paths))
# 遍历样式化图像和内容图像的批次
for batch_stylized, batch_content in zip(dataloader_stylized, dataloader_content):
# 在不计算梯度的上下文中进行操作,节省内存和计算资源
with torch.no_grad():
# 计算当前批次的距离
batch_dist = metric(batch_stylized.to(device), batch_content.to(device))
N += batch_stylized.shape[0]
dist_sum += torch.sum(batch_dist)
pbar.update(batch_stylized.shape[0])
pbar.close()
return dist_sum / N
def compute_cfsd(path_to_stylized, path_to_content, batch_size, device, num_workers=1):
"""Computes CFSD for the given paths.
Args:
path_to_stylized (str): Path to the stylized images.
path_to_content (str): Path to the content images.
batch_size (int): Batch size for computing activations.
device (str): Device for computing activations.
num_workers (int): Number of threads for data loading.
Returns:
(float) CFSD value.
"""
print('Compute CFSD value...')
# 计算 Patch Similarity,该函数返回样式化图像和内容图像的距离值
simi_val = compute_patch_simi(path_to_stylized, path_to_content, 1, device, num_workers)
# 将距离值保留四位小数
simi_dist = f'{simi_val.item():.4f}'
return simi_dist
#evaluation\image_metrics.py
class PatchSimi(nn.Module):
def __init__(self, device=None):
# 初始化函数
super(PatchSimi, self).__init__()
# 加载预训练的 VGG19 模型,并移到指定设备上进行评估
self.model = models.vgg19(pretrained=True).features.to(device).eval()
# 指定层名称和替换名称的映射
self.layers = {"11": "conv3"}
# 图像归一化的均值和标准差
self.norm_mean = (0.485, 0.456, 0.406)
self.norm_std = (0.229, 0.224, 0.225)
# KL 散度损失函数
self.kld = torch.nn.KLDivLoss(reduction='batchmean')
self.device = device
def get_feats(self, img):
features = []
# 遍历 VGG19 模型的各层并提取特征
for name, layer in self.model._modules.items():
img = layer(img)
if name in self.layers:
features.append(img)
return features
def normalize(self, input):
# 图像归一化处理
return transforms.functional.normalize(input, self.norm_mean, self.norm_std)
def patch_simi_cnt(self, input):
b, c, h, w = input.size()
# 转置和重塑特征
input = torch.transpose(input, 1, 3)
features = input.reshape(b, h*w, c).div(c)
feature_t = torch.transpose(features, 1, 2)
# 计算内容图像的特征相似度
patch_simi = F.log_softmax(torch.bmm(features, feature_t), dim=-1)
return patch_simi.reshape(b, -1)
def patch_simi_out(self, input):
b, c, h, w = input.size()
# 转置和重塑特征
input = torch.transpose(input, 1, 3)
features = input.reshape(b, h*w, c).div(c)
feature_t = torch.transpose(features, 1, 2)
# 计算样式化图像的特征相似度
patch_simi = F.softmax(torch.bmm(features, feature_t), dim=-1)
return patch_simi.reshape(b, -1)
def forward(self, input, target):
src_feats = self.get_feats(self.normalize(input))
target_feats = self.get_feats(self.normalize(target))
init_loss = 0.
# 计算各层的 KL 散度并求和作为初始损失值
for idx in range(len(src_feats)):
init_loss += F.kl_div(self.patch_simi_cnt(src_feats[idx]), self.patch_simi_out(target_feats[idx]), reduction='batchmean')
效果
与传统风格迁移方法的比较:时间快,效果好

- 在ArtFID(艺术风格迁移评价指标)方面,作者的方法大大超越了传统方法,ArtFID与人类偏好一致。
- 在FID(Fréchet Inception Distance)方面,作者的方法记录了最低的分数,表明风格化图像与目标风格高度相似。
- 在内容保真度指标CFSD(Content Feature Structural Distance)和LPIPS(Learned Perceptual Image Patch Similarity)方面,作者的方法也展现出了优越的得分。
- 他们的方法可以通过调整参数γ来任意调整风格迁移的程度,并且在匹配LPIPS(内容)的值时,在FID(风格)方面显著超越了其他所有方法。
- 作者的方法比其他方法显著更快,即使使用了大规模的扩散模型。这种更快的速度来自于作者的方法可以使用更少的DDIM反演步骤,因为在反演步骤中额外利用了收集到的特征,大大降低了对内容和风格完美反演的必要性
作者的方法在保持内容图像的结构信息方面表现更好,同时能够有效地迁移风格:

- 以图6为例,作者展示了他们的方法在保留桥梁结构方面的优势,而其他baseline在保持结构或迁移风格方面存在挑战。
- 相比之下,其他基线在给定任意内容风格对时,往往会丢失内容的结构或未能成功迁移风格。例如,DiffuseIT和DiffStyle在生成形状合理且视觉上可信的图像或保留原始内容方面存在问题。另一方面,InST虽然能够合成逼真的图像,但在风格迁移或改变图像内容方面存在挑战。



















 3965
3965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









