







深度学习论文精读(1):ResNet
深度的神经网络往往难以训练,而这篇文章则提出了一个残差学习的框架,使得神经网络能在更深的层数中获得更好的效果。
论文地址:Deep Residual Learning for Image Recognition
译文地址:http://blog.csdn.net/wspba/article/details/57074389
作者github地址:https://github.com/KaimingHe/deep-residual-networks
文章目录
1.提出问题
- 理论上来说,更深的神经网络能够获取图像更多的特征,给予神经网络更优秀的性能。
- 问题1:首先考虑一个简单的问题,如果我们有一对相同的浅层网络,那么我们在另一个浅层网络上叠加恒等变化,那么理论上来说,更深的网络效果不应该变差。
- 问题2:深度的网络会导致的梯度弥漫/消失(即Vanishing/Exploding Gradients),也基本上可以通过更好的初始化以及中间层的归一化(即Normalized Initialization, Intermediate Normalization Layers)来解决。
- 实际上,并不是这样,在更深的神经网络中存在退化问题(Degradation Problem),如下图所示:
- 由图中的例子可见不是过拟合,更深的网络训练误差也更大。
- 残差网络的提出,很好的解决了深度神经网络的退化问题。

2.解决方案
-
作者提出了如下图展示的深度残差学习框架(deep residual learning framework. )
-
核心思想就是,通过一个快捷通道(shortcut connection)进行一次恒等映射。
这样,残差块输出的结果就是非线性映射( F ( x ) \mathcal {F}(x) F(x))再加上恒等映射( x x x)。因此,在极端情况下,我们可以使非线性映射 F ( x ) \mathcal{F}(x) F(x)为0,那么残差块的结果至少为一次恒等映射,不至于使网络的效果变差。
-
设最终得到的映射为 H ( x ) \mathcal{H}(x) H(x),则 F ( x ) = H ( x ) − x \mathcal{F}(x)=\mathcal{H}(x) - x F(x)=H(x)−x。即学习的是应有的映射与原始输入之间的差值。因此被称为残差映射(residual mapping)。
-

- 快捷通道(shortcut connection)和高速网络(“highway networks”)的对比
- 快捷通道总是能够保留恒等映射,而高速网络通过一个gate来控制恒等映射的大小。这样的结果导致在gate为0的时候,它就退化为了普通的神经网络。
- 实验也证明,“highway networks”并不能通过增加层数(100层以上)获得准确率的提升。
3.实现方式
-
输入与输出的维度相等的情况下:
- y = F ( x , { W i } ) + x y = \mathcal{F}(x,\{W_i\}) + x y=F(x,{Wi})+x
-
输入与输出的维度不等的情况下:(相同的情况下也可以,因为 W s W_s Ws做的只是一个维度变换,可以使其不变换维度。)
- y = F ( x , { W i } ) + W s x y = \mathcal{F}(x,\{W_i\}) + W_sx y=F(x,{Wi})+Wsx
-
shortcut的实现方式:
- 维度增加时,使用0来填充增加的维度。维数相同时,直接相加。
- 维度增加时,使用projection shortcuts增加维度。维数相同时,直接相加。
- 不管维数相不相同,都用projection shortcuts进行维度的调整。
- 其中projection shortcuts指 y = F ( x , { W i } ) + W s x y = \mathcal{F}(x,\{W_i\}) + W_sx y=F(x,{Wi})+Wsx中的 W s x W_sx Wsx。一个全连接操作。
- 效果上,3>2>1,实际情况下一般用2,兼顾计算量和效果。
深度瓶颈结构:
-
使用右下图所示的瓶颈结构代替左下图的双卷积结构。
-
先通过1*1卷积减少维度,再进行3*3卷积,最后通过1*1卷积恢复维度。
-
能够有效的减少参数,以及运行效率。

4. 训练细节
- 图像增强:使用与AlexNet、VGG一样的图像增强方式,截取224*224的图片,随机水平变换。调整图像的大小使它的短边长度随机的从256,480中采样来增大图像的尺寸。
- 预处理:减去像素均值。
- 普通卷积结构为:conv-bn-relu。
- 优化算法:初始学习率0.1,验证集精度不变化后学习率除以10;batch size取256;l2 loss取0.0001;使用带动量的SGD,动量参数为0.9;weight decay取0.0001
- 测试时使用模型融合,分别计算224 256 384 480 640的图片,计算平均数。
- 没用dropout
5.一些解释以及一些理解
-
残差学习(residual learning)
-
在神经网络中,假设多个非线性层可以逼近某种复杂的函数,则它一定也可以逼近复杂的残差函数。例如 F ( x ) \mathcal{F}(x) F(x)。所有我们令神经网络逼近 F ( x ) \mathcal{F}(x) F(x)而不是 H ( x ) \mathcal{H}(x) H(x),并令多个非线性层需要逼近的函数为 F ( x ) = H ( x ) − x \mathcal{F}(x)=\mathcal{H}(x) - x F(x)=H(x)−x。
这么做的好处是,如果在这个残差块中,恒等映射是最优解,那么残差块久很容易驱使自己去学习到恒等变换,而不至于因为网络层数的增加而出现退化(degradtion)现象。
同时,对已有的恒等变换进行学习,比重新寻找一个近似最优解要方便的多。
6.一些图片
- VGG-19网络,朴素网络,残差网络的构架。
- 实线为同维度残差,虚线为不同维度残差。
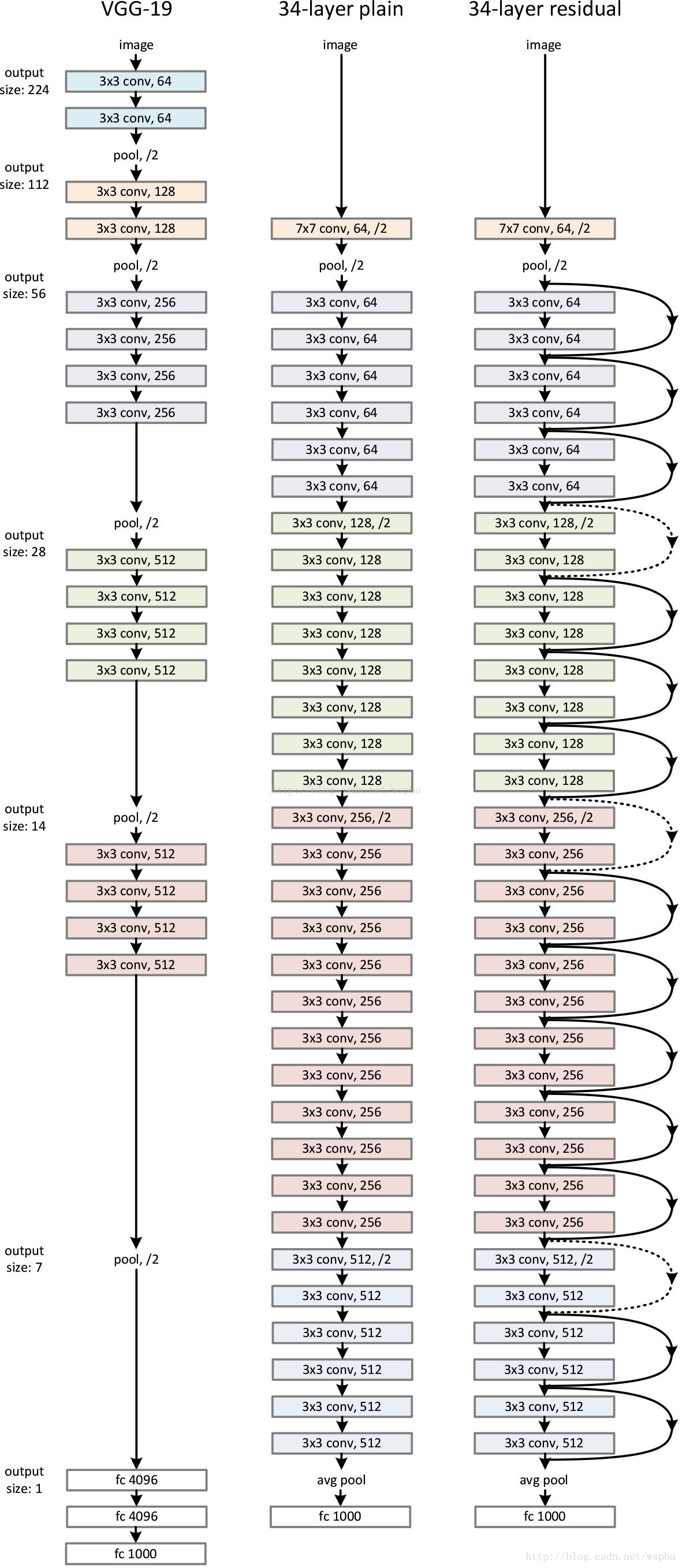
- 不同深度的残差网络结构

- 不同深度对于残差网络与朴素网络的影响。(朴素网络会受到退化问题的影响,而残差网络不会。)

单词整理:
-
preceptron
-
auxiliary
-
contrast
-
precondition
-
condition
-
asymptotically approximate complicated functions
-
notation















 3249
3249











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









