







每隔20s监听本地文件夹“/home/hduser/Streamingtext”下新生成的文本文件,对新文件中的各单词个数进行统计
/*
Streamingtext下操作文件应注意以下几点:
1.监控目录下的文件应该具有统一的数据格式,避免在内部解析时报错。
2.文件必须是在监控目录下创建,可以通过原子性的移动或重命名操作,放入目录。
3.一旦移入目录,文件就不能再修改了,如果文件是持续写入的话,新的数据是无法读取的。
*/
package spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds,StreamingContext}
import org.apache.log4j.{Level, Logger}
object StreamingFileWC {
def main(args: Array[String]): Unit ={
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
Logger.getLogger("org.eclipse.jetty.server").setLevel(Level.OFF)
val sparkConf =new SparkConf().setAppName("StreamingFileWC").setMaster("local[2]")//2为核数
//setMaster("spark://192.168.71.129:7077") //提交jar以集群运行使用此设置
val ssc = new StreamingContext(sparkConf,Seconds(20)) //每隔20秒监听一次
val lines = ssc.textFileStream("/home/hduser/Streamingtext")
//val lines = ssc.textFileStream("hdfs://node01:9000/streamingdata") //手动put上传HDFS
val words= lines.flatMap(_.split(" ")) //每行数据以空格切分
val wordcounts=words.map(x=>(x,1)).reduceByKey(_+_)
wordcounts.print()
ssc.start()
ssc.awaitTermination()
}
}
在IDE以本地模式运行程序时,不断地在/home/hduser/Streamingtext文件夹下手动添加相同数据结构文档,程序每隔20秒抓取并处理数据,控制台输出:
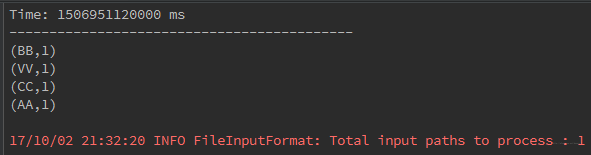
同理,如果是在集群上运行,需要将程序打成JAR包,通过spark主目录下的bin/spark-submit 提交,并不断上传文档到HDFS上指定监听路径下以模拟实时数据流。















 4793
4793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









