










目录
正文: Spring框架是一个功能强大且广泛应用的Java开发框架,而Stream流是Java 8引入的一种新的数据处理方式。结合Spring和Stream流可以帮助我们更加优雅和高效地处理数据。本文将介绍如何在Spring应用中使用Stream流来简化数据处理。
1. 引入依赖
首先,在您的Spring项目中引入以下依赖:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>2. 创建实体类和Repository接口
假设我们有一个User实体类和一个UserRepository接口。这些类可以通过Spring Data JPA来定义和管理。
@Entity
public class User {
@Id
private Long id;
private String name;
// 其他属性和方法省略...
}
@Repository
public interface UserRepository extends JpaRepository<User, Long> {
// 自定义查询方法...
}3. 使用Stream流进行数据处理
在Service或Controller层,您可以使用Stream流对从数据库查询得到的数据进行简单而强大的处理。
@Service
public class UserService {
private final UserRepository userRepository;
public UserService(UserRepository userRepository) {
this.userRepository = userRepository;
}
public List<String> getAllUserNames() {
return userRepository.findAll()
.stream()
.map(User::getName)
.collect(Collectors.toList());
}
}在上述示例中,我们通过调用userRepository.findAll()从数据库中获取所有的User对象,然后使用Stream流对每个User对象进行处理。通过调用map(User::getName),我们仅提取User对象的名称属性,并将其转换为一个新的Stream<String>。最后,我们通过调用collect(Collectors.toList())将这些用户名收集到一个列表中并返回。
1. 在配置文件 开启注解扫描包
<!--注解扫描包 -->
<context:component-scan base-package="com.cskt.mapper,com.cskt.service"/>
2.在mapper 使用@Repostroy (瑞泼贼提) 相当于在配置文件写了 配置bean
里面可以放一个名字@Repostroy("userMapper") 相当于id名字
如果不给就是类名名字 首字母小写
3.在service @Service (赊v思) 相当于在配置写了配置bean
// <bean id="userService" class="com.cskt.service.UserServiceImpl" >
// <constructor-arg ref="userMapper"/>
// </bean>
4.在service 引入 自动装配
@Autowired //自动装配 四种 get set 构造函数 根据名称 根据类型
public UserMapperImpl userMapper;
注解使用aop
1. 在配置文件加入 扫描 包
<bean id="myAcpect" class="com.cskt.aspect.MyAspect" />
<aop:aspectj-autoproxy/>
2.定义一个切面 类上面加一个注解 @Aspect (艾斯派克特)
// 给那个方法增强 。。。。。,
@Before("execution( * com.cskt.service..*.*(..))")
public void before(){
System.out.println("前置通知.... 在方法之前要執行的公共代码放在这里");
}
@AfterThrowing 异常通知
@Before 前置通知
@AfterReturning 后置通知
@Around 环绕通知
@After 最终通知
@Aspect 切面
@Pointcut 切入点
Stream流
1.filter
可以对流中的元素进行条件过滤,符合过滤条件的才能继续留在流中。
2.map
可以把对流中的元素进行计算或转换。
3.distinct
可以去除流中的重复元素。
distinct方法是依赖Object的equals方法来判断是否是相同对象的。所以需要注意重写equals方法。
4.sorted
可以对流中的元素进行排序。
如果调用空参的sorted()方法,需要流中的元素是实现了Comparable。
5.limit
可以设置流的最大长度,超出的部分将被抛弃。
6.skip
跳过流中的前n个元素,返回剩下的元素
7.flatMap
map只能把一个对象转换成另一个对象来作为流中的元素。而flatMap可以把一个对象转换成多个对象作为流中的元素。
4. 结论
使用Spring和Stream流的组合可以帮助我们在数据处理方面编写更简洁、可读性更高的代码。它们提供了丰富的操作方法和函数式编程的优势,可以使我们的代码更加优雅和高效。
思维图:
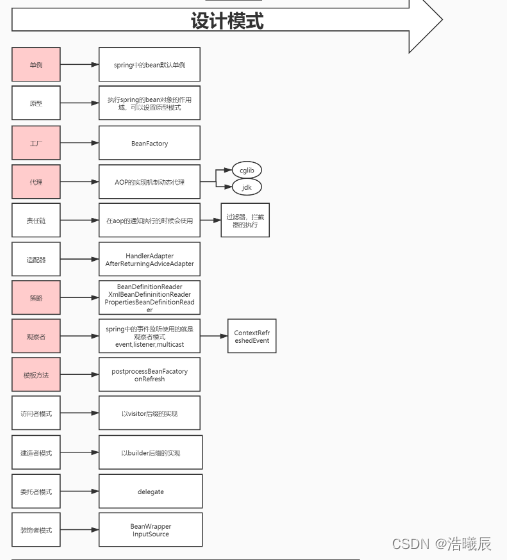
还是不会的去看看别人的思路:
第四节 基于注解管理bean(Spring第一章)_在控制器方法中访问自定义配置文件属性和配置类bean对象并输出_管程序猿的博客-CSDN博客















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









