







转载请注明出处:http://blog.csdn.net/hxcpp
看内核代码时经常会遇到一些数据结构,包括链表,散列表,树等。之前遇到,仅仅只是从原理上了解大概是干嘛用的,没有深入详细分析代码。这里我想逐步就一些常用的数据结构进行总结,一些代码设计颇为精妙,对于自己编程也会有很大帮助。
1链表
1.1基本链表结构
链表是Linux内核中最简单也是最常用的数据结构。简单的链表结构形如:
单链表:

双链表:
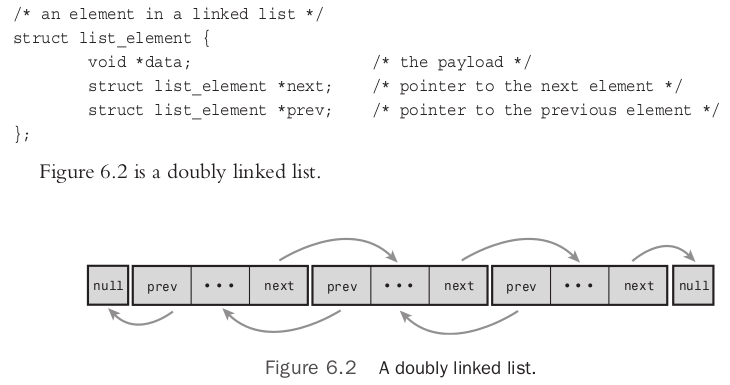
循环链表(分别是单向循环链表和双向循环链表):

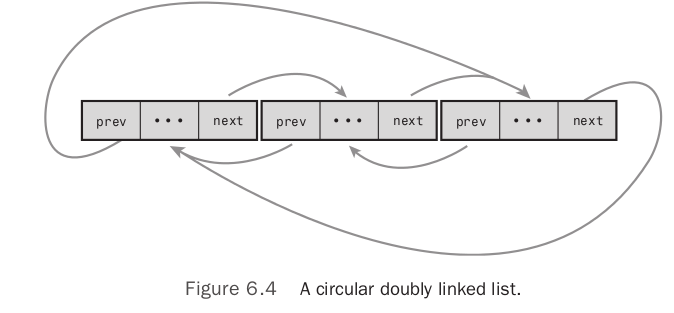
尽管Linux中链表实现十分独特,但本质上是一个双向循环链表。
1.2Linux中链表的实现
自己之前写代码时,定义链表结点均类似上面所示,即将所需的数据结构包含在链表节点中。但是在Linux中,有很多数据结构需要使用链表将其串连,如,task_struct、super_block等等。这样如果按照传统的设计,对于每个链表,必须分别实现一组基本操作:初始化链表,插入删除元素,扫描链表等。这可能既浪费开发人员的精力,也因为对每个不同的链表都要重复相同的基本操作而造成存储空间的浪费。
为此,Linux将链表节点嵌入到需要形成链式结构的数据结构中。内核定义了list_head数据结构,如下所示:
228 "include/linux/types.h"
229 struct list_head {
230 struct list_head *next, *prev;
231 }; 显然,next和prev分别指向下一个和前一个list_head的地址,而并非包含list_head整个数据结构的地址。如下图所示:

那么,这样的list_head是如何使用的呢,也就是如何通过指向list_head的next\prev指针,来获取包含list_head的整个数据结构的地址?
Linux为此提供了一个list_entry(ptr,type,member)宏,其中ptr是指向该数据中list_head成员的指针,也就是存储在链表中的地址值,type是数据项的类型,member则是数据项类型定义中list_head成员的变量名。
例如:定义了如下一个结构
struct fox{
…
struct list_head list;
}fox_a;
现有一个
struct list_head *p; //p指向fox_a中的list
struct fox *f;
则f可以这样获取fox_a的地址:
f=list_entry(p,struct fox, list);
下面具体看看其实现:
343 "include/linux/list.h"
344 /**
345 * list_entry - get the struct for this entry
346 * @ptr: the &struct list_head pointer.
347 * @type: the type of the struct this is embedded in.
348 * @member: the name of the list_struct within the struct.
349 */
350 #define list_entry(ptr, type, member) \
351 container_of(ptr, type, member) 由于在C语言中,一个数据结构分量的偏移地址在编译时就已经确定,则通过container_of()宏,能够很容易获取包含任意成员变量的父数据结构:
672 "include/linux/kernel.h"
673 /**
674 * container_of - cast a member of a structure out to the containing structure
675 * @ptr: the pointer to the member.
676 * @type: the type of the container struct this is embedded in.
677 * @member: the name of the member within the struct.
678 *
679 */
680 #define container_of(ptr, type, member) ({ \
681 const typeof( ((type *)0)->member ) *__mptr = (ptr); \
682 (type *)( (char *)__mptr - offsetof(type,member) );}) 其中,offsetof定义如下("include/linux/stddef.h"):
20 #define offsetof(TYPE, MEMBER) ((size_t) &((TYPE *)0)->MEMBER) size_t 最终定义为unsigned long(i386)。
这里使用的是一个利用编译器技术的小技巧,即先求得结构成员在与结构中的偏移量,然后根据成员变量的地址反过来得出属主结构变量的地址。
container_of()和offsetof()并不仅用于链表操作,这里最有趣的地方是
((type*)0)->member,它将0地址强制"转换"为type结构的指针,再访问到type结构中的member成员。在container_of宏中,它用来给typeof()提供参数(typeof()是gcc的扩展,和sizeof()类似),以获得member成员的数据类型;在offsetof()中,这个member成员的地址实际上就是type数据结构中member成员相对于结构变量的偏移量。(看,符号&用于取地址,这里由于((TYPE*)0)的作用,也就是结构变量起始地址为0,那么获得MEMBER的地址当然是偏移值了。size_t再将地址类型强制转换为整数类型,用于减法)
***这样看上面的式子还是有些怪异,比如就前面f=list_entry(p,struct fox, list); 这句话来说,宏展开后即为
f=({ const typeof( (( struct fox *)0)->list) * __mptr = (p);
( struct fox *)( (char *)__mptr – offsetof( struct fox,list) );
});上面这个赋值语句,其右值为一个复合语句,问题就是既然复合语句能够赋值给f,那么这个复合语句的值又是多少呢?复合语句能作为右值出现么?我查了一下资料:(http://blog.csdn.net/npy_lp/article/details/7015066)GCC对C的扩展,有机会需要详细看看语法,现在就不管这么多吧。
如下:
在GNUC中,允许用小括号括起来的复合语句出现在一个表达式中。
例如下面程序:

运行结果:
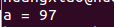
因此,可以知道f的值实际上为该复合语句最后一句话的值,该语句返回一个struct fox *类型值。这样,所有问题应该都弄清楚了吧。
能够从嵌入的list_head类型变量的地址获取包含它的数据结构的地址,剩下的问题就好办了,这样便可以根据list_head定义一组关于链表的基本操作(Armed with list_entry(), the kernel provides routines to create,manipulate, and otherwise manage linked lists—all without knowinganything about the structures that the list_head resides within.):
1.3list_head相关操作("include/linux/list.h")
(1)定义链表(声明和初始化)
实际上Linux只定义了链表节点,并没有专门定义链表头,那么一个链表结构是如何建立起来的呢?让我们来看看LIST_HEAD()这个宏:
18
19 #define LIST_HEAD_INIT(name) { &(name), &(name) }
20
21 #define LIST_HEAD(name) \
22 struct list_head name = LIST_HEAD_INIT(name)
LIST_HEAD(name) 定义了类型为list_head的新变量name,该变量作为新链表头的占位符,是一个哑元素,同时初始化了prev、next字段,让它们指向name变量本身,见前面图3-3。
对于很多包含list_head的数据结构,需要在动态运行时初始化,此时需要使用INIT_LIST_HEAD()内联函数进行初始化,如下:
24 static inline void INIT_LIST_HEAD(struct list_head *list)
25 {
26 list->next = list;
27 list->prev = list;
28 }
(2)判空
182 /**
183 * list_empty - tests whether a list is empty
184 * @head: the list to test.
185 */
186 static inline int list_empty(const struct list_head *head)
187 {
188 return head->next == head;
189 }
191 /**
192 * list_empty_careful - tests whether a list is empty and not being modified
193 * @head: the list to test
194 *
195 * Description:
196 * tests whether a list is empty _and_ checks that no other CPU might be
197 * in the process of modifying either member (next or prev)
198 *
199 * NOTE: using list_empty_careful() without synchronization
200 * can only be safe if the only activity that can happen
201 * to the list entry is list_del_init(). Eg. it cannot be used
202 * if another CPU could re-list_add() it.
203 */
204 static inline int list_empty_careful(const struct list_head *head)
205 {
206 struct list_head *next = head->next;
207 return (next == head) && (next == head->prev);
208 }
(3)插入/删除/移动/替换/合并/旋转
a)插入
对链表的插入操作有两种:在指定节点后插入和之前插入。Linux为此提供了两个接口:
60 static inline void list_add(struct list_head *new, struct list_head *head)
61 {
62 __list_add(new, head, head->next);
63 }
74 static inline void list_add_tail(struct list_head *new, struct list_head *head)
75 {
76 __list_add(new, head->prev, head);
77 }
因为Linux链表是双向循环表,所以,list_add和list_add_tail的区别并不大,实际上,Linux最后均调用__list_add()函数:
30 /*
31 * Insert a new entry between two known consecutive entries.
32 *
33 * This is only for internal list manipulation where we know
34 * the prev/next entries already!
35 */
37 static inline void __list_add(struct list_head *new,
38 struct list_head *prev,
39 struct list_head *next)
40 {
41 next->prev = new;
42 new->next = next;
43 new->prev = prev;
44 prev->next = new;
45 }
b )删除
99 static inline void __list_del_entry(struct list_head *entry)
100 {
101 __list_del(entry->prev, entry->next);
102 }
103
104 static inline void list_del(struct list_head *entry)
105 {
106 __list_del(entry->prev, entry->next);
107 entry->next = LIST_POISON1;
108 entry->prev = LIST_POISON2;
109 }
同时需要注意,list_del不会释放任何属于entry或者它所在数据结构的内存空间,仅仅是将entry元素从链表上摘下来:
设置LIST_POISON1和LIST_POISON2是为了保证不在链表中的节点项不可访问——对LIST_POSITION1和LIST_POSITION2的访问都将引起缺页。
86 static inline void __list_del(struct list_head * prev, struct list_head * next)
87 {
88 next->prev = prev;
89 prev->next = next;
90 }
同时,内核提供了这样一个函数:
138 /**
139 * list_del_init - deletes entry from list and reinitialize it.
140 * @entry: the element to delete from the list.
141 */
142 static inline void list_del_init(struct list_head *entry)
143 {
144 __list_del_entry(entry);
145 INIT_LIST_HEAD(entry);
146 }
这样的好处是可以重利用从链表上删除的元素。
c)移动
很简单,如下:153 static inline void list_move(struct list_head *list, struct list_head *head)
154 {
155 __list_del_entry(list);
156 list_add(list, head);
157 }
164 static inline void list_move_tail(struct list_head *list,
165 struct list_head *head)
166 {
167 __list_del_entry(list);
168 list_add_tail(list, head);
169 }
d) 替换
115 /**
116 * list_replace - replace old entry by new one
117 * @old : the element to be replaced
118 * @new : the new element to insert
119 *
120 * If @old was empty, it will be overwritten.
121 */
122 static inline void list_replace(struct list_head *old,
123 struct list_head *new)
124 {
125 new->next = old->next;
126 new->next->prev = new;
127 new->prev = old->prev;
128 new->prev->next = new;
129 }
130
131 static inline void list_replace_init(struct list_head *old,
132 struct list_head *new)
133 {
134 list_replace(old, new);
135 INIT_LIST_HEAD(old);
136 }
e )合并
287 /**
288 * list_splice - join two lists, this is designed for stacks
289 * @list: the new list to add.
290 * @head: the place to add it in the first list.
291 */
292 static inline void list_splice(const struct list_head *list,
293 struct list_head *head)
294 {
295 if (!list_empty(list))
296 __list_splice(list, head, head->next);
297 }
299 /**
300 * list_splice_tail - join two lists, each list being a queue
301 * @list: the new list to add.
302 * @head: the place to add it in the first list.
303 */
304 static inline void list_splice_tail(struct list_head *list,
305 struct list_head *head)
306 {
307 if (!list_empty(list))
308 __list_splice(list, head->prev, head);
309 }
273 static inline void __list_splice(const struct list_head *list,
274 struct list_head *prev,
275 struct list_head *next)
276 {
277 struct list_head *first = list->next;
278 struct list_head *last = list->prev;
279
280 first->prev = prev;
281 prev->next = first;
282
283 last->next = next;
284 next->prev = last;
285 }
类似的,还有
318 static inline void list_splice_init(struct list_head *list,
319 struct list_head *head)
320 {
321 if (!list_empty(list)) {
322 __list_splice(list, head, head->next);
323 INIT_LIST_HEAD(list);
324 }
325 }
335 static inline void list_splice_tail_init(struct list_head *list,
336 struct list_head *head)
337 {
338 if (!list_empty(list)) {
339 __list_splice(list, head->prev, head);
340 INIT_LIST_HEAD(list);
341 }
342 }
f )旋转
210 /**
211 * list_rotate_left - rotate the list to the left
212 * @head: the head of the list
213 */
214 static inline void list_rotate_left(struct list_head *head)
215 {
216 struct list_head *first;
217
218 if (!list_empty(head)) {
219 first = head->next;
220 list_move_tail(first, head);
221 }
222 }
g )其他
224 /**
225 * list_is_singular - tests whether a list has just one entry.
226 * @head: the list to test.
227 */
228 static inline int list_is_singular(const struct list_head *head)
229 {
230 return !list_empty(head) && (head->next == head->prev);
231 }
232
233 static inline void __list_cut_position(struct list_head *list,
234 struct list_head *head, struct list_head *entry)
235 {
236 struct list_head *new_first = entry->next;
237 list->next = head->next;
238 list->next->prev = list;
239 list->prev = entry;
240 entry->next = list;
241 head->next = new_first;
242 new_first->prev = head;
243 }
245 /**
246 * list_cut_position - cut a list into two
247 * @list: a new list to add all removed entries
248 * @head: a list with entries
249 * @entry: an entry within head, could be the head itself
250 * and if so we won't cut the list
251 *
252 * This helper moves the initial part of @head, up to and
253 * including @entry, from @head to @list. You should
254 * pass on @entry an element you know is on @head. @list
255 * should be an empty list or a list you do not care about
256 * losing its data.
257 *
258 */
259 static inline void list_cut_position(struct list_head *list,
260 struct list_head *head, struct list_head *entry)
261 {
262 if (list_empty(head))
263 return;
264 if (list_is_singular(head) &&
265 (head->next != entry && head != entry))
266 return;
267 if (entry == head)
268 INIT_LIST_HEAD(list);
269 else
270 __list_cut_position(list, head, entry);
271 }
(4) 遍历
遍历是链表最经常的操作之一,为了方便核心应用遍历链表,Linux链表将遍历操作抽象成几个宏。
最基本的当然是list_for_each()宏,如下:
364 /**
365 * list_for_each - iterate over a list
366 * @pos: the &struct list_head to use as a loop cursor.
367 * @head: the head for your list.
头节点
368 */
369 #define list_for_each(pos, head) \
370 for (pos = (head)->next; pos != (head); pos = pos->next)
当然,遍历链表的目的是为了获取包含list_head结构的数据结构,那么此时可以这样使用,如下:
static LIST_HEAD(fox_list);
….
struct list_head *p;
struct fox *f;
list_for_each(p, &fox_list){
f=list_entry(p,struct fox,list);
}大多数内核使用list_for_each_entry()宏来遍历链表
412 /**
413 * list_for_each_entry - iterate over list of given type
414 * @pos: the type * to use as a loop cursor.
415 * @head: the head for your list.
416 * @member: the name of the list_struct within the struct.
417 */
418 #define list_for_each_entry(pos, head, member) \
419 for (pos = list_entry((head)->next, typeof(*pos), member); \
420 &pos->member != (head); \
421 pos = list_entry(pos->member.next, typeof(*pos), member))
422
某些应用需要反向遍历链表,Linux提供了list_for_each_prev()和list_for_each_entry_reverse()来完成这一操作,使用方法和上面介绍的list_for_each()、list_for_each_entry()完全相同。
如果遍历不是从链表头开始,而是从已知的某个节点pos开始,则可以使用list_for_each_entry_continue(pos,head,member)。有时还会出现这种需求,即经过一系列计算后,如果pos有值,则从pos开始遍历,如果没有,则从链表头开始,为此,Linux专门提供了一个list_prepare_entry(pos,head,member)宏,将它的返回值作为list_for_each_entry_continue()的pos参数,就可以满足这一要求。
遍历时节点删除
前面介绍了用于链表遍历的几个宏,它们都是通过移动pos指针来达到遍历的目的。但如果遍历的操作中包含删除pos指针所指向的节点,pos指针的移动就会被中断,因为list_del(pos)将把pos的next、prev置成LIST_POSITION2和LIST_POSITION1的特殊值。
当然,调用者完全可以自己缓存next指针使遍历操作能够连贯起来,但为了编程的一致性,Linux链表仍然提供了两个对应于基本遍历操作的"_safe"接口:list_for_each_safe(pos,n, head)、list_for_each_entry_safe(pos,n, head,member),它们要求调用者另外提供一个与pos同类型的指针n,在for循环中暂存pos下一个节点的地址,避免因pos节点被释放而造成的断链。
391 /**
392 * list_for_each_safe - iterate over a list safe against removal of list entry
393 * @pos: the &struct list_head to use as a loop cursor.
394 * @n: another &struct list_head to use as temporary storage
395 * @head: the head for your list.
396 */
397 #define list_for_each_safe(pos, n, head) \
398 for (pos = (head)->next, n = pos->next; pos != (head); \
399 pos = n, n = pos->next)
485 /**
486 * list_for_each_entry_safe - iterate over list of given type safe against removal of list entry
487 * @pos: the type * to use as a loop cursor.
488 * @n: another type * to use as temporary storage
489 * @head: the head for your list.
490 * @member: the name of the list_struct within the struct.
491 */
492 #define list_for_each_entry_safe(pos, n, head, member) \
493 for (pos = list_entry((head)->next, typeof(*pos), member), \
494 n = list_entry(pos->member.next, typeof(*pos), member); \
495 &pos->member != (head); \
496 pos = n, n = list_entry(n->member.next, typeof(*n), member))
对于其他一些定义的宏或者函数,功能和作用也都类似,这里就不再分析了,Linux链表这块,差不多就结束了吧,以后如果发现有意思的新内容再添加吧。















 121
121

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









