









声明:在学习linux 内核数据结构之链表部分时参考了http://blog.chinaunix.net/uid-14114479-id-2932024.html。
Linux kernel里面从来就不缺少简洁,优雅和高效的代码,只是我们缺少发现和品味的眼光。在Linux kernel里面,简洁并不表示代码使用神出鬼没的超然技巧,相反,它使用的不过是大家非常熟悉的基础数据结构,但是kernel开发者能从基础的数据结构中,提炼出优美的特性。
Linux kernel中有很多用的很经典的数据结构,链表就算其中之一,还有队列,哈希查找,红黑树查找等等,链表的设计很经典,就连很多开发内核的黑客们都觉得内核中链表的设计是他们引以自豪的一部分。内核链表的好主要体现为两点,1是可扩展性,2是封装。可扩展性肯定是必须的,内核一直都是在发展中的,所以代码都不能写成死代码,要方便修改和追加。将链表常见的操作都进行封装,使用者只关注接口,不需关注实现。分析内核中的链表我们可以做些什么呢?可以将其复用到用户态编程中,以后在用户态下编程就不需要写一些关于链表的代码了,直接将内核中list.h中的代码拷贝过来用也可以整理my_list.h,在以后的用户态编程中直接将其包含到C文件中,代码不仅简洁(绝无多余的一行代码多去定义一个变量,可以通过位运算实现的绝对不用数学运算来实现)而且更加高效。一:Linux kernel链表定义及结构
内核源码include/linux/list.h定义了链表的数据结构,如下:
struct list_head {
struct list_head *next, *prev;
};
list_head结构包含两个指向list_head结构的指针prev和next,由此可见,内核的链表具备双链表功能,实际上,通常它都组织成双循环链表。list_head从字面上理解,好像是头结点的意思。但从这里的代码来看却是普通结点的结构体,在后面的代码中将list_head当成普通的结点来处理。在Linux内核链表中不是在链表结构中包含数据,而是在数据结构中包含链表节点链表作为连接件。这里的list_head没有数据域,它作为数据成员嵌入到用户定义的数据结构中,知道list_head节点的内存地址(也就是指向list_head节点的指针)就能知道list_head节点所在数据结构的起始地址(指向list_head节点所在的父数据结构内存中指针),进而也就知道宿主数据结构中其它数据成员的情况,这种设计思路不得不说很巧妙。
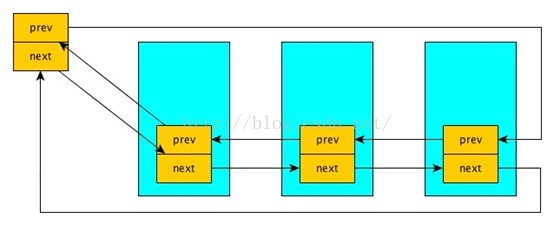
二:链表head节点的生成及初始化
需要注意的一点是,头结点head是不使用的,这点需要注意。生成双向链表的头结点
LIST_HEAD(name) -- 生成一个名为name的双向链表头节点
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
上面两个宏就生成双向链表的头结点name,并进行了初始化,就相当于
struct list_head name = {.next=&name, .prev=&name}也就是说head节点初始化后其指针变量next和prev都指向的自己。那么我们通过这条信息可以来判断一个链表是否为空链表,只要是head节点的next指针指向自己就说明了链表中没有其他节点是个空链表。
static inline int list_empty(const struct list_head *head){
return head->next == head;
}

三:通用链表操作接口
1、向链表中添加节点
static inline void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next)
{
next->prev = new;
new->next = next;
new->prev = prev;
prev->next = new;
}
普通的在两个非空结点中插入一个结点,注意new、prev、next都不能是空值。
Prev可以等于next,此时在只含头节点的链表中插入新节点。
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
在head和head->next两指针所指向的结点之间插入new所指向的结点。即:在head指针后面插入new所指向的结点。
当现有链表只含有一个头节点时,上述__list_add(new, head, head->next)仍然成立。
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
在结点指针head所指向结点的前面插入new所指向的结点。当head指向头节点时,也相当于在尾结点后面增加一个new所指向的结点。
注意:head->prev不能为空,即若head为头结点,其head->prev当指向一个数值,一般为指向尾结点,构成循环链表。
上述三个函数实现了添加一个节点的任务,其中__list_add()为底层函数,“__”通常表示该函数是底层函数,供其他模块调用,此处实现了较好的代码复用,list_add和list_add_tail虽然原型一样,但调用底层函数__list_add时传递了不同的参数,从而实现了在head指向节点之前或之后添加新的对象。
2、从链表中删除节点
如果要从链表中删除某个链表节点,则可以调用list_del或list_del_init。需要注意的是,上述操作均仅仅是把节点从双循环链表中拿掉,用户需要自己负责释放该节点对应的数据结构所占用的空间,而这个空间本来就是用户分配的。
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
prev->next = next;
}
在prev和next指针所指向的结点之间,两者互相所指。在后面会看到:prev为待删除的结点的前面一个结点,next为待删除的结点的后面一个结点。
static inline void list_del(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
删除entry所指的结点,同时将entry所指向的结点指针域封死。
对LIST_POISON1,LIST_POISON2的解释说明:
Linux 内核中解释:These are non-NULL pointers that will result in page faults under normal circumstances, used to verify that nobody uses non-initialized list entries.
#define LIST_POISON1 ((void *) 0x00100100)
#define LIST_POISON2 ((void *) 0x00200200)
常规思想是:entry->next = NULL; entry->prev = NULL; 保证不可通过该节点进行访问。
static inline void list_del_init(struct list_head *entry)
{
__list_del(entry->prev, entry->next);
INIT_LIST_HEAD(entry);
}
删除entry所指向的结点,同时调用LIST_INIT_HEAD()把被删除节点为作为链表头构建一个新的空双循环链表。
3、移动节点
Linux还提供了两个移动操作:list_move和list_move_tail。
将list所指向的结点移动到head所指向的结点的后面。
static inline void list_move(struct list_head *list, struct list_head *head)
{
__list_del(list->prev, list->next);
list_add(list, head);
}
将list结点前后两个结点互相指向彼此,删除list指针所指向的结点,再将此结点插入head,和head->next两个指针所指向的结点之间。
static inline void list_move_tail(struct list_head *list, struct list_head *head)
{
__list_del(list->prev, list->next);
list_add_tail(list, head);
}
删除了list所指向的结点,将其插入到head所指向的结点的前面,如果head->prev指向链表的尾结点的话,就是将list所指向的结点插入到链表的结尾。
4、判断是否为空链表
由list-head构成的双向循环链表中,通常有一个头节点,其不含有有效信息,初始化时prev和next都指向自身。判空操作是判断除了头节点外是否有其他节点。
static inline int list_empty(const struct list_head *head)
{
return head->next == head;
}
测试链表是否为空,如果是只有一个结点,head,head->next,head->prev都指向同一个结点,则这里会返回1,表示空;但这个空不是没有任何结点,而是只有一个头结点,因为头节点只是纯粹的list节点,没有有效信息,故认为为空。
static inline int list_empty_careful(const struct list_head *head)
{
struct list_head *next = head->next;
return (next == head) && (next == head->prev);
}
分析:
1.只有一个头结点head,这时head指向这个头结点,head->next,head->prev指向head,即:head==head->next==head->prev,这时候list_empty_careful()函数返回1。
2.有两个结点,head指向头结点,head->next,head->prev均指向后面那个结点,即:head->next==head->prev,而head!=head->next,head!=head->prev.所以函数将返回0
3.有三个及三个以上的结点,这是一般的情况,自己容易分析了。
注意:这里empty list是指只有一个空的头结点,而不是毫无任何结点。并且该头结点必须其head->next==head->prev==head
5、链表合并
static inline void __list_splice(struct list_head *list, struct list_head *head)
{
struct list_head *first = list->next;
struct list_head *last = list->prev;
struct list_head *at = head->next;
first->prev = head;
head->next = first;
last->next = at;
at->prev = last;
}
static inline void list_splice(struct list_head *list, struct list_head *head)
{
if (!list_empty(list))
__list_splice(list, head);
}
这种情况会丢弃list所指向的结点,这是特意设计的,因为两个链表有两个头结点,要去掉一个头结点。只要一个头结点。
static inline void list_splice_init(struct list_head *list, struct list_head *head)
{
if (!list_empty(list))
{
__list_splice(list, head);
INIT_LIST_HEAD(list);
}
}
6、链表遍历
#define __list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
list_for_each()有prefetch()用于复杂的表的遍历,而__list_for_each()无prefetch()用于简单的表的遍历。head在宏定义中用了括号将其括起来。
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev; prefetch(pos->prev), pos != (head); \
pos = pos->prev)
解释类似上面的list_for_each()。
内核中解释的精华部分:
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
这是说你可以边遍历边删除,这就叫safe。十分精彩。刚开始时,我也一直不理解safe的意思,后来在www.linuxforum.net论坛上搜索list_for_each_safe找到了解答。
#define list_entry(ptr, type, member) \
container_of(ptr, type, member)
分析:
list_entry()函数用于将指向某链表结点成员的指针调整到该链表的开始处,并指针转换为该链表结点的类型。
#define list_for_each_entry(pos, head, member) \
for (pos = list_entry((head)->next, typeof(*pos), member); \
prefetch(pos->member.next), &pos->member != (head); \
pos = list_entry(pos->member.next, typeof(*pos), member))















 324
324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









