






 本文详细介绍了van Emde Boas树的数据结构及其操作方法,包括查找、插入、删除等基本操作,并深入探讨了其背后的原理和实现细节。
本文详细介绍了van Emde Boas树的数据结构及其操作方法,包括查找、插入、删除等基本操作,并深入探讨了其背后的原理和实现细节。
van Emde Boas树
- van Emde Boas树中文名不知道,所以暂且叫它v树吧。v树是一种数据结构,和二叉树、红黑树类似。一种数据结构被创建出来,肯定有其特别的优点,v树的优点就是实现数据的基本操作的最差的时间复杂度为O(lglgn),在算法导论前面知识可以知道,红黑树的性能是最好的,基本操作最坏的时间复杂度为O(lg(n)),所以v树的性能相对于红黑树要好很多,如果真的这样的话,红黑树这种数据结构估计就被淘汰了,完全可以被v树取代,然而红黑树仍然存在,说明就取代不了,因为v树要实现O(lglgn)是有前提条件的,这限制了v树的使用范围:
- 条件1:关键字必须要在0~n-1内的整数(也就是说这里的n是指关键字的取值范围,不是元素个数)
- 条件2:关键字还不能重复,就是没有相等的关键字
- 条件3:维护树的性质复杂
- 虽然有这些限制,但是v树的优点还是有相当大的吸引力的,这也是v树在这里被介绍的原因。
基本方法
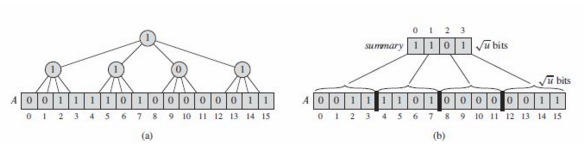
这里我准备按照算法导论中的步骤来讲,我发现写算法导论书的人真的很牛逼,他的牛逼之处不是把这种方法教会给你,而是教会你一种怎么去想问题并解决问题的思路。假如现在给你一个问题,让你设计一种数据结构,这种数据结构的时间复杂度为O(lglg(n)),你应该怎么去设计呢??下面一起来思考这个问题。叠加的二叉树结构

由上图可以看出,该叠加的二叉树结构是通过0和1来区分元素是否在集合中,其中二叉树结构中父节点是两个子节点的逻辑或。下面对基本操作的过程进行讲述:这种数据结构,对于查找最大值和最小值的时间复杂度为O(lgu),u为数据的大小,对于插入一个数据和删除一个节点也是O(lgu),因为操作需要对树分支进行遍历一遍。所以这种数据结构的性能和红黑树差不多。现在我们来对这种结构进行改进。
- 查找最小值:从根节点开始,一直向下到叶节点,总是走左边包含1的节点
- 查找最大值:从根节点开始,一直向下到叶节点,总是走右边包含1的节点
- 查找后继节点:从叶节点开始,一直向上到根节点,直到有一个节点其右孩子节点为1,然后从右孩子一直向下往最左边进行查找
- 查找前继节点:从叶节点开始,一直向上到根节点,直到有一个节点其左孩子节点为1,然后从右孩子一直向下往最右边进行查找
- 插入一个节点:将该标记位修改为1,然后将该叶节点到根节点的分支都修改为1
- 删除一个节点:将该标记为修改为0,然后将该叶节点到根节点的分支上的节点都进行或逻辑运算
叠加的高度恒定的树
由叠加二叉树可以知道,插入和删除的时间复杂度为O(lg(u)),这取决于树的高度。所以要想减少时间复杂度就要从减小树的高度上想办法。这里我们想到了b树,通过扩大子节点的数目,从而减少高度,这是一个非常直接的解决方法。由此我们可以得到如下的数据结构。
 由上图可以看出,每个节点的子节点有原来的2个扩大到了现在的
由上图可以看出,每个节点的子节点有原来的2个扩大到了现在的个,操作方式和叠加二叉树类似。
下面来分析一下这种数据结构的性能,首先对于基本操作,就拿查找最小值来说,首先是需要沿着树的分支进行查找,从树根到叶子节点需要遍历递归结构分析
上面我们可以写出其递归表达式如下:
上述式子中,T(n)表示算法的复杂度,该算法的复杂度是由个节点的时间复杂度加上常数时间组成。换句话说,经过常数的时间的操作,可以将一个处理n个元素的结构转化为处理
通过上述递归式来求算法的时间复杂度,可以令m=lgn,则有
换种形式可得: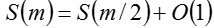 上述形式就可以通过主方法得到该算法的时间复杂度为O(lglgn),由此,van Emde Boas树大体的思路就有了。为了下面叙述的方便,这里定义三个变量:
上述形式就可以通过主方法得到该算法的时间复杂度为O(lglgn),由此,van Emde Boas树大体的思路就有了。为了下面叙述的方便,这里定义三个变量:
上面式子中,暂且把high(x)当成x的高位,即为每一组元素的组号,low(x)当成x的低位,即为每一组元素在组内的序号。index为元素在整个元素整体中的位置。原型van Emde Boas结构
上面是v树原型的基本结构,第一眼看到该结构的时候我脑海中只出现两个值(恶心),但是恶心还得看,静下心来发现其实也没那么复杂,下面来具体讲讲这个结构。开始将该结构前,重新看看迭代式:
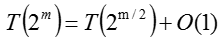
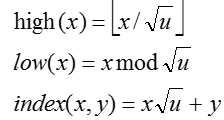
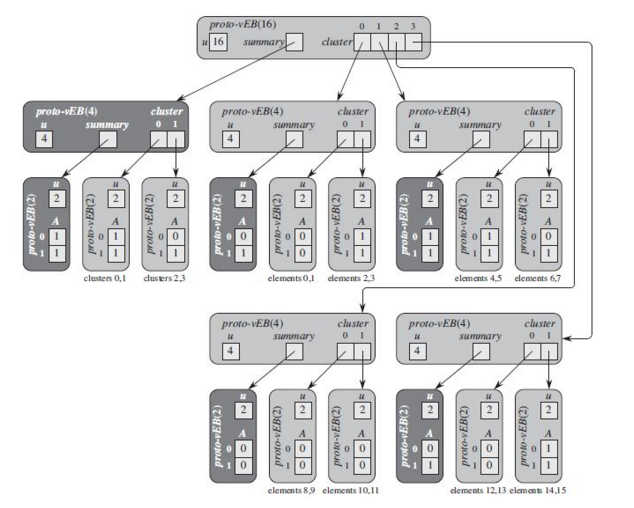
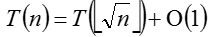
可以看到对于任意操作,可以通过常数时间复杂度将元素个数缩小根号倍。你设计这种结构会怎么设计??以查找元素操作为例,将元素个数缩小根号倍好办,将n个元素分割成
下面根据该数据结构,讲讲每个数据操作的具体实现过程,同时计算其时间复杂度。
- 如果u=2,那么proto-veb中包含数组A[0,1]。
- 一个名为summary的指针,指向包含组信息的proto-veb结构中,用于查询。
- 一个数组cluster[1...],每个元素都指向每个组的初始元素。
- 判断一个值是否在集合中
首先看看其伪代码,通过伪代码来讲述整个操作过程。
PROTO-vEB-MEMBER(V,x) if v.u==2 //到达最小组元素 return V.A[x] //返回该数组A[]的值,1表示存在,0表示不存在 else return PROTO-vEB-MEMBER(V.cluster[high(x)],low(x)) //根据元素值查找下一层的节点从上面伪代码可以看出,我们采用递归式寻找,先确定我们寻找元素所处的组号high,递归到最小单元每个组只有两个元素时,用过low(x)来确定组中的相应位,通过相应位为0还是1来确定查找元素是否在集合中。
- 查找最小元素
伪代码如下:
PROTO-vEB-MINIMUM(V) if V.u==2 //最小单元下进行分析 if V.A[0]==1 //当第一个数存在时返回其下标0 return 0 else if V.A[1]==1 return 1 else //如果不存在该数时,返回空 return NIL else min_cluster= PROTO-vEB-MINIMUM(V.summary) //查找一个大集合中对应的最小值所在的组号 if min-cluster==NIL return NIL else offset=PROTO-vEB-MINIMUM(V.cluster[min-cluster]) //根据组号来查找组中的偏移量 return index(min-cluster,offset) //利用组号和偏移量来算最小值不知道你们看出来没有,伪代码写的是相当的巧妙。整个操作过程主要分为两个部分,第一部分确定最小值所在组的的组号,第二部分确定最小值所在组的偏移量。通过组号和偏移量就可以求出最小值。而伪代码当中用了多层递归,能这样做其实也得益与它的结构特点,每个集合都分为而后我们分析一下算法的时间复杂度,由于程序中两次递归调用该函数,所以递归式如下: 通过主方法可以算出,该时间复杂度为
通过主方法可以算出,该时间复杂度为,就是说还没有达到我们
的要求,仍然需要改进。
- 查找后继
伪代码如下:
PROTO-vEB-SUCCESSOR(V,x) if V.u==2 if x==0 and V.A[1]==1 return 1 else return NIL else offset=PROTO-vEB-SUCCESSOR(V.cluster[high(x)],low[x])//判断该组中是否存在后继 if(offset!=NIL) //如果存在,则在下一组元素中进行寻找 return index(high(x),offset) else //如果不存在,则在下一组中寻找最小节点 succ-cluster=PROTO-vEB-SUCCESSOR(V.summary,high(x)) //查找该组的后继 if succ-cluster==NIL //如果该组的后继不存在,则赋空 return NIL else //如果存在,则找到在该组中的偏移量 offset=PROTO-vEB-SUCCESSOR(V.summary,high(x)) return index
整个递归过程和查找最小元素差不多,只不过这里需要有个判断,是否后继在节点x所在组中,如果在的话直接可以输出,如果不在的话就需要在下一组中进行寻找,具体实现过程可以根据代码中的注释进行理解。
下面我们来分析其时间复杂度,由伪代码可以知道,该操作自身递归调用了俩次,还调用了一次min函数,所以递归表达式如下:
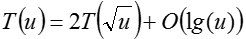 用主方法可以算出该操作的时间复杂度为
用主方法可以算出该操作的时间复杂度为。也没有达到我们的目的。
- 插入元素
伪代码如下:
上面操作也分为两部分,第一部分修改由子节点到根节点该支路上cluster值,第二部分修改summary指针的值。因为两次递归调用,所以和查找最小值一样,时间复杂度为PROTO-vEB-INSERT(V,x) if(V.u==2) V.A[x]=1 //相应位置1 else PROTO-vEB-INSERT(V.cluster[high],low[x]) //插入元素该分支上的cluster数组的值都需要更改 PROTO-vEB-INSERT(V.summary,high(x)) //summary的值也要更改
- 删除操作
删除操作其实和插入类似,插入是将值置1,删除置0.时间复杂度还是
- van Emde Boas结构
由上可知,v树原型还达不到我们最后的要求,虽然性能好了很多,所以我们仍然需要改进。下面我们来看v树的终极结构:
这个结构比原型还要复杂,时间复杂度的缩小一般情况下都增加了算法的复杂度来实现的。该结构和原型相比主要是每个节点的属性上增加了两个属性:要理解上述的结构图,必须要明白一点,这很重要,就是每个数v中储存的元素为V.min的值加上V.cluster[0,1...]的值,就拿上述图举例,该图包含了集合{2,3,4,5,7,14,15},正常情况下V.cluster[0]的最小值应该为2,但是结构图上写的却是3,问题就在VEB[16]中的最小值为2,所以不会体现在V.cluster[0]这个组里面,知道这个理解上述图就好多了。
- min存储了veb树中的最小元素
- max存储了veb树中的最大元素
增加了max和min两个属性有什么好处呢??
- minimum和maximum操作不需要利用递归,可以直接得出。
- 在successor操作中,有了max和min属性我们就可以不用再确定后继是否在high(x)组中,如果x的后继在x元素所处的组中,只有在x小于该组的最大值,这里就少了递归调用一次。
- 通过min和max元素就可以在常数时间知道树是否为空。
van Emde Boas树的操作
- 查找最小元素和最大元素

vEB-TREE-MINIMUM(V) return V.min vEB-TREE-MAXIMUM(V) return V.max
- 操作只要一行代码,比较简单。
- 判断一个值是否在集合中
vEB-TREE-MEMBER(V,x) if x==V.min or x==V.max //基础情形下只有两个元素,一个最小值,一个最大值 return TRUE elseif V.u==2 //如果情形下,既不是最小值,也不是最大值,则该元素不存在 return FALSE else //如果不是基础情形 return vEB-TREE-MEMBER(V.cluster[high],low(x)) //迭代寻找最小情形查找元素分为两种情况,一种是不在基础情形(v=2)中,这种情况下递归迭代寻找相应的最小组,第二种是基础情形下,如果元素和最小值或者最大值相等,则返回该元素,如果不等,这说明元素不存在集合中。
- 查找后继
vEB-TREE-SUCCESSOR(V,x) if V.u==2 //基础情形,当只有两个时 if x==0 and V.max==1 //如果x的低位为最小值,而且后一个元素为最大值存在 return 1 //返回最大值 else //如果不是上述情况,则返回NIL return NIL //如果x为组中的最小值,因为该元素不在每个其小组中,因此如果严格小于小组的最小值,则该最小值为后继节点 elseif V.min!=NIL and x在后继查找主要分为两个部分:第一部分是基础情况分析,当u=2时,如果查找元素为第一个,且第二个最大存在的情况下,返回第值1,第二部分是非基础情形,这又分为两种情况,如果x为某组中最小元素,因为最小元素不在cluster数组中,所以可以用在其子簇中最小元素比较,如果小于最小元素,则说明最小元素为该元素的后继,因为x为大组中的最小元素,其后继肯定是子小组中的最小元素,如果是这样的话,直接输出该最小元素。如果x不为某组的最小元素,这里又分为两种情况,一种是元素的后继是否在x元素所处的组中,判断是通过元素x与该组的最大值比较,如果小于最大值,说明在该组中,如果大于等于最大值,则说明在另一个组中,且为后继组中的最小值。
下面分析一下算法的复杂度,虽然在伪代码中看到两个vEB-TREE-SUCCESSOR递归调用,但是其处于分支结构,实质上只会调用一次,而查找最小值和最大值都是在O(1)时间内进行的,所以后继查找的时间复杂度的O(lglgu)
查找前继和查找后继的过程类似,但是有一种附加情况需要处理,就是如果x的前驱存在,但是不在x所处的该组中,这该组的前继没有,这种情况出现只能说明x前继为该组的最小值。
- 插入一个元素
vEB-EMPTY-TREE-INSERT
V.min=x
V.max=x
vEB-TREE-INSERT(V,x)
if V.min==NIL //如果该树为空
vEB-EMPTY-TREE-INSERT(V,x) //只需要在该组的最大值和最小值即可
else
if x
2
if vEB-TREE-MINIMUM(v.cluster[high(x)])==NIL //如果该组为空
vEB-TREE-INSTER(V.summary,high(x)) //修改summary指针的值
vEB-EMPTY-TREE-INSERT(V.cluster[high(x)],low(x)) //修改该组的最大值和最小值
else //如果在组不为空,这summary指针就不需要修改,只需要修改组内值
vEB-TREE-INSTER(V.cluster[high(x)],low(x))
if x>V.max
V.max=x
在看到v树的结构时,我其实一直有一个疑惑,就是为什么每个组的最小值不放在cluster数组里面??直到我看到了插入元素的伪代码,我懂了,我不得不佩服设计该结构的人,真的把资源用到了极致。下面来分析一下这段伪代码,首先我们需要考虑的是怎么才能通过一次调用该函数,完成递归呢??当插入元素时,每个组要么存在一个元素,要么为空。如果为空的话,我们将插入元素中唯一的元素,我们仅仅需要将其保存在最小值里面就可以了,不需要递归调用cluster数组找到元素位置,这就为什么每个组的最小值不放在cluster数组里面,这里仅仅需要修改summary的值即可。如果存在元素,这就不需要修改summary的值,我们仅仅需要找到cluster的位置,将其赋值即可。综上所述,不管情况如何,我们仅仅需要一次调用完成。具体的思想就是这样,所以插入操作的时间复杂度为O(lglgu).
- 删除一个元素
vEB-TREE-DELETE(V,x)
if V.min==V.max //如果树只有一个元素
V.min==NIL
V.max=NIL
elseif V.u==2 //如果基础情形,u==2,且该基础情况下两个元素都存在
if x==0 //删除值为0,则将最小值更改为1
V.min=1
else //如果删除值为1,则将其最小值改为0,最大值为0
V.min=0
V.max=V.min
else //其他情况
//如果x为组中的最小值,这将最小值换为第一子簇中的最小值,然后将原来最小值删除
if x==V.min
first-cluster=vEB-TREE-MINIMUM(V.summary)
//找到新的最小值
x=index(frist-cluster,vEB-TREE-MINIMUM(V.cluster[first-cluster]))
V.min=x
//同时需要删除子簇中的x
vEB-TREE-DELETE(V.cluster[high(x)],low(x))
//如果删除x后该簇为空
if vEB-TREE-MINIMUM(V.cluster[high(x)])==NIL
//更新簇号
vEB-TREE-DELETE(V.summary,high(x))
//可能出现x与V.max相等的情形,即该簇中只有两个元素,最大值和最小值,所以还需要更新V.max
if x==V.max
summary-max=vEb-TREE-MAXIMUM(V.summary)
//如果最大值被更新,则给最大值重新赋值
if summary-max==NIL
V.max=V.min
else
V.max=index(summary-max,vEB-TREE-MAXIMUM(V.cluster[summary-max]))
//如果删除x之后,簇不为空,更新V.max
else
if x==V.max
V.max=index(high(x),vEB-TREE-MAXIMUM(V.cluster[high]))
删除元素的伪代码确实比较难理解,其中一个原因就是其考虑的可能性多,造成代码分支较严重。下面我来分析一下各种情况。大的方面可以将程序分为三种情况:
情况1:当树中只有一个元素时(这里不分u=2还是u!=2),这种情况下,将最小值和最大值都赋空就可以了。
情况2:当u=2时,因为前面已经分析了只有一个元素的情况,所以该簇中只可能有两个元素,所以删除哪个,修改相应的最大和最小值即可。
情况3:当u!=2时,此时也要分为3种情况考虑:
情况1:如果删除元素为该簇的最小值,因为最小值没在cluster数组里面,所以我们需要更新最小值,则找到第一子簇中的最小元素更新最小值。然后将x值删除。
情况2:如果将x值删除之后,发现第一子簇没有元素了,这时我们需要将summary数组相应位赋空。这种情况下还需要更新V.max的值,假设整棵树只有两个元素,最大值和最小值,将最小值删除,我们就会将最大值作为树的最小值,然后更新子树中的summary里面的最大值,然而这里我们需要将其修改过来。
情况3:如果删除的是树中的最大值,我们需要用前一个值将最大值进行更新。
上述就是v树产生的整个过程,造就了v树操作时间复杂度为O(lglg(n))的优点。

















 1745
1745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









