







中文文档
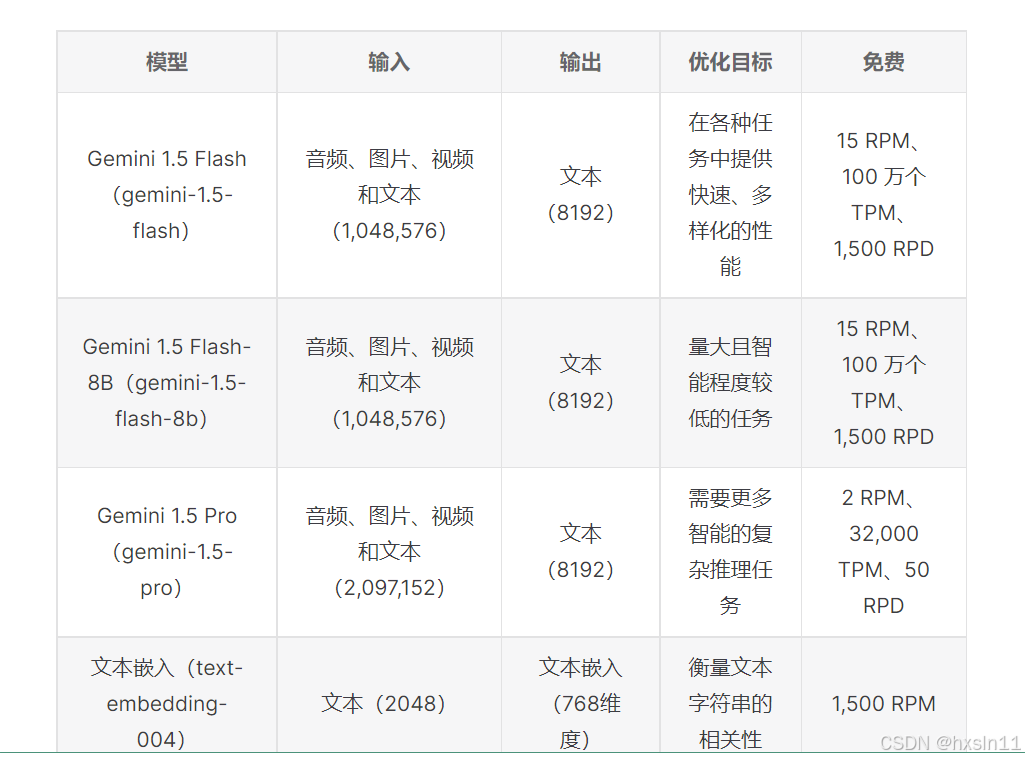
Gemini 1.5 Flash
最平衡的多模态模型,适用于大多数任务,并且性能出色。快速且多才多艺的多模态模型,每个问题的图片数量上限3600,视频时长上限 1 小时,音频时长上限大约 9.5 小时。
- 输入音频、图片、视频和文本,获取文本回复
- 生成代码、提取数据、编辑文本等
- 最适合平衡性能和费用的任务
Gemini 1.5 Flash-8B
最快、最具成本效益的多模态模型,适用于高频率任务,性能出色。小型模型,每个问题的图片数量上限3600,视频时长上限 1 小时,音频时长上限大约 9.5 小时。
- 输入音频、图片、视频和文本,获取文本回复
- 生成代码、提取数据、编辑文本等
- 最适合低智能、高频率任务
Gemini 1.5 Pro
最佳的多模态模型,具有适用于各种推理任务的功能。中型多模态模型,可以一次处理大量数据,包括 2 小时的视频、19 小时的音频、6 万行代码的代码库或 2,000 页的文本。
- 输入音频、图片、视频和文本,获取文本回复
- 生成代码、提取数据、编辑文本等
- 适用于需要提升广告效果时
总结时刻
待续ing

















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









