






2014年由GAN之父Ian Goodfellow提出(加拿大蒙特利尔大学)
GAN —— 生成式对抗网络
前面我们讲了自动编码器和变分自动编码器, 不管是哪一个, 都是通过计算生成图像和输入图像在每个像素点的误差来生成 loss, 这一点是特别不好的, 因为不同的像素点可能造成不同的视觉结果, 但是可能他们的 loss 是相同的, 所以通过单个像素点来得到 loss 是不准确的, 这个时候我们需要一种全新的 loss 定义方式, 就是通过对抗进行学习。
生成对抗网络,GAN, 根据这个名字就可以知道这个网络是由两部分组成的, 第一部分是生成, 第二部分是对抗。 简单来说, 就是有一个生成网络和一个判别网络, 通过训练让两个网络相互竞争, 生成网络来生成假的数据, 对抗网络通过判别器去判别真伪, 最后希望生成器生成的数据能够以假乱真。
Discriminator Network 判别网络
GAN的对抗过程简单来说就是一个判断真假的判别器,相当于一个二分类问题, 我们输入一张真的图片希望判别器输出的结果是1, 输入一张假的图片希望判别器输出的结果是0。 这其实已经和原图片的 label 没有关系了, 不管原图片到底是一个多少类别的图片, 他们都统一称为真的图片, label 是 1 表示真实的; 而生成的假的图片的label 是 0 表示假的。
我们训练的过程就是希望这个判别器能够正确的判出真的图片和假的图片, 这其实就是一个简单的二分类问题, 对于这个问题可以用我们前面讲过的很多方法去处理, 比如 logistic 回归, 深层网络, 卷积神经网络, 循环神经网络都可以。
Generator Network 生成网络
生成网络如何生成一张假的图片。 首先给出一个简单的高维的正态分布的噪声向量, 如上图所示的 D-dimensional noise vector, 这个时候我们可以通过仿射变换, 也就是 xw+b 将其映射到一个更高的维度, 然后将他重新排列成一个矩形, 这样看着更像一张图片, 接着进行一些卷积、 转置卷积、 池化、 激活函数等进行处理, 最后得到了一个与我们输入图片大小一模一样的噪音矩阵, 这就是我们所说的假的图片。
这个时候我们如何去训练这个生成器呢? 这就需要通过对抗学习, 增大判别器判别这个结果为真的概率, 通过这个步骤不断调整生成器的参数, 希望生成的图片越来越像真的, 而在这一步中我们不会更新判别器的参数, 因为如果判别器不断被优化, 可能生成器无论生成什么样的图片都无法骗过判别器
训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量辨别出G生成的假图像和真实的图像。这样,G和D构成了一个动态的“博弈过程”,最终的平衡点即纳什均衡点.
import torch from torch import nn import torchvision.transforms as transforms from torch.utils.data import DataLoader from torchvision.datasets import MNIST import numpy as np import matplotlib.pyplot as plt import matplotlib.gridspec as gridspec from visdom import Visdom NOISE_DIM = 96 batch_size = 128 def show_images(images): # 定义画图工具 images = np.reshape(images, [images.shape[0], -1]) sqrtn = int(np.ceil(np.sqrt(images.shape[0]))) sqrtimg = int(np.ceil(np.sqrt(images.shape[1]))) fig = plt.figure(figsize=(sqrtn, sqrtn)) gs = gridspec.GridSpec(sqrtn, sqrtn) gs.update(wspace=0.05, hspace=0.05) for i, img in enumerate(images): ax = plt.subplot(gs[i]) plt.axis('off') ax.set_xticklabels([]) ax.set_yticklabels([]) ax.set_aspect('equal') plt.imshow(img.reshape([sqrtimg,sqrtimg])) # plt.show() return def generator(noise_dim=NOISE_DIM): net = nn.Sequential( nn.Linear(noise_dim, 1024), nn.ReLU(True), nn.Linear(1024, 1024), nn.ReLU(True), nn.Linear(1024, 784), nn.Tanh() ) return net def discriminator(): net = nn.Sequential( nn.Linear(784, 256), nn.LeakyReLU(0.2), nn.Linear(256, 256), nn.LeakyReLU(0.2), nn.Linear(256, 1) ) return net def discriminator_loss(logits_real, logits_fake): # 判别器的 loss size = logits_real.shape[0] true_labels = torch.tensor(torch.ones(size, 1)).float().cuda() #全1 false_labels = torch.tensor(torch.zeros(size, 1)).float().cuda() #全0 loss = bce_loss(logits_real, true_labels) + bce_loss(logits_fake, false_labels) #表示logits_real和全1还差多少,logits_fake和全0还差多少 return loss def generator_loss(logits_fake): # 生成器的 loss size = logits_fake.shape[0] true_labels = torch.tensor(torch.ones(size, 1)).float().cuda() #true_label就全是1 loss = bce_loss(logits_fake, true_labels) return loss def train_gan(D_net, G_net, D_optimizer, G_optimizer, discriminator_loss, generator_loss, show_every=10, noise_size=96, num_epochs=10): iter_count = 0 for epoch in range(num_epochs): for input, _ in train_data: batchsz = input.shape[0] # 判别网络----------------------------------- #把图片打平 real_img = torch.tensor(input).view(batchsz, -1).cuda() # 真实数据 logits_real = D_net(real_img) # 判别网络得分 #随机噪声,generator就是输入随机噪声然后生成图片 sample_noise = (torch.rand(batchsz, noise_size) - 0.5) / 0.5 # -1 ~ 1 的均匀分布 g_fake_seed = torch.tensor(sample_noise).cuda() fake_images = G_net(g_fake_seed) # 生成的假的数据 logits_fake = D_net(fake_images) # 判别网络得分 # 判别器的 loss d_total_loss = discriminator_loss(logits_real, logits_fake) # 优化判别网络 D_optimizer.zero_grad() d_total_loss.backward() D_optimizer.step() # 生成网络---------------------------- g_fake_seed = torch.tensor(sample_noise).cuda() fake_images = G_net(g_fake_seed) # 生成的假的数据 gen_logits_fake = D_net(fake_images) g_loss = generator_loss(gen_logits_fake) # generator要让生成的图片尽可能地为真 G_optimizer.zero_grad() g_loss.backward() G_optimizer.step() # 优化生成网络 if (iter_count % show_every == 0): print('Epoch: {}, Iter: {}, D_loss: {:.4}, G_loss:{:.4}'.format(epoch, iter_count, d_total_loss.item(), g_loss.item())) imgs_numpy = deprocess_img(fake_images.data.cpu().numpy()) show_images(imgs_numpy[0:16]) plt.savefig('plt_img/%d.png'% iter_count) plt.close() viz.line([d_total_loss.item()], [iter_count], win='D_loss', update='append') viz.line([g_loss.item()], [iter_count], win='G_loss', update='append') iter_count += 1 checkpoint = { "net_D": D.state_dict(), "net_G": G.state_dict(), 'D_optim':D_optim.state_dict(), 'G_optim':G_optim.state_dict(), "epoch": epoch } torch.save(checkpoint, 'checkpoints/ckpt_%s.pth' %(str(epoch))) print('checkpoint of epoch %d has been saved!'%epoch) def preprocess_img(x): x = transforms.ToTensor()(x) return (x - 0.5) / 0.5 #把preprocess_img的操作逆回来 def deprocess_img(x): return (x + 1.0) / 2.0 train_set = MNIST( root='dataset/', train=True, download=True, transform=preprocess_img ) train_data = DataLoader( dataset=train_set, batch_size=batch_size, # sampler=ChunkSampler(NUM_TRAIN, 0) #从第0个开始,采样NUM_TRAIN个 ) val_set = MNIST( root='dataset/', train=False, download=True, transform=preprocess_img ) val_data = DataLoader( dataset=val_set, batch_size=batch_size, # sampler=ChunkSampler(NUM_VAL, NUM_TRAIN) ) # print(len(train_set))# 是 391 # print(len(val_set))# 是 40 viz = Visdom() viz.line([0.], [0.], win='G_loss', opts=dict(title='G_loss')) viz.line([0.], [0.], win='D_loss', opts=dict(title='D_loss')) bce_loss = nn.BCEWithLogitsLoss() D = discriminator().cuda() G = generator().cuda() D_optim = torch.optim.Adam(D.parameters(), lr=3e-4, betas=(0.5, 0.999)) G_optim = torch.optim.Adam(G.parameters(), lr=3e-4, betas=(0.5, 0.999)) train_gan(D, G, D_optim, G_optim, discriminator_loss, generator_loss, num_epochs=500)对抗过程体现在,generator要让生成的图片尽可能地为真,而discrimanator要让generator生成的图片尽可能地被判为假
最开始是这样
最终也就能学到这个样子了
我们已经完成了一个简单的生成对抗网络,但是可以看到效果并不是特别好,生成的数字也不是特别完整,因为我们仅仅使用了简单的多层全连接网络。
除了这种最基本的生成对抗网络之外,还有很多生成对抗网络的变式,有结构上的变式,也有 loss 上的变式,我们先讲一讲其中一种在 loss 上的变式,Least Squares GAN








least squares GAN
Least Squares GAN 比最原始的 GANs 的 loss 更加稳定,通过名字我们也能够看出这种 GAN 是通过最小平方误差来进行估计,而不是通过二分类的损失函数,下面我们看看 loss 的计算公式
可以看到 Least Squares GAN 通过最小二乘代替了二分类的 loss,下面我们定义一下 loss 函数
import torch from torch import nn import torchvision.transforms as transforms from torch.utils.data import DataLoader, sampler from torchvision.datasets import MNIST import numpy as np import matplotlib.pyplot as plt import matplotlib.gridspec as gridspec from visdom import Visdom NOISE_DIM = 96 batch_size = 128 def show_images(images): # 定义画图工具 images = np.reshape(images, [images.shape[0], -1]) sqrtn = int(np.ceil(np.sqrt(images.shape[0]))) sqrtimg = int(np.ceil(np.sqrt(images.shape[1]))) fig = plt.figure(figsize=(sqrtn, sqrtn)) gs = gridspec.GridSpec(sqrtn, sqrtn) gs.update(wspace=0.05, hspace=0.05) for i, img in enumerate(images): ax = plt.subplot(gs[i]) plt.axis('off') ax.set_xticklabels([]) ax.set_yticklabels([]) ax.set_aspect('equal') plt.imshow(img.reshape([sqrtimg,sqrtimg])) # plt.show() return def generator(noise_dim=NOISE_DIM): net = nn.Sequential( nn.Linear(noise_dim, 1024), nn.ReLU(True), nn.Linear(1024, 1024), nn.ReLU(True), nn.Linear(1024, 784), nn.Tanh() ) return net def discriminator(): net = nn.Sequential( nn.Linear(784, 256), nn.LeakyReLU(0.2), nn.Linear(256, 256), nn.LeakyReLU(0.2), nn.Linear(256, 1) ) return net def ls_discriminator_loss(scores_real, scores_fake): loss = 0.5 * ((scores_real - 1) ** 2).mean() + 0.5 * (scores_fake ** 2).mean() return loss def ls_generator_loss(scores_fake): loss = 0.5 * ((scores_fake - 1) ** 2).mean() return loss def train_gan(D_net, G_net, D_optimizer, G_optimizer, discriminator_loss, generator_loss, show_every=10, noise_size=96, num_epochs=10): iter_count = 0 for epoch in range(num_epochs): for input, _ in train_data: batchsz = input.shape[0] # 判别网络----------------------------------- #把图片打平 real_img = torch.tensor(input).view(batchsz, -1).cuda() # 真实数据 logits_real = D_net(real_img) # 判别网络得分 sample_noise = (torch.rand(batchsz, noise_size) - 0.5) / 0.5 # -1 ~ 1 的均匀分布 g_fake_seed = torch.tensor(sample_noise).cuda() fake_images = G_net(g_fake_seed) # 生成的假的数据 logits_fake = D_net(fake_images) # 判别网络得分 # 判别器的 loss d_total_loss = discriminator_loss(logits_real, logits_fake) # 优化判别网络 D_optimizer.zero_grad() d_total_loss.backward() D_optimizer.step() # 生成网络---------------------------- g_fake_seed = torch.tensor(sample_noise).cuda() fake_images = G_net(g_fake_seed) # 生成的假的数据 gen_logits_fake = D_net(fake_images) g_loss = generator_loss(gen_logits_fake) # 生成网络的 loss G_optimizer.zero_grad() g_loss.backward() G_optimizer.step() # 优化生成网络 if (iter_count % show_every == 0): print('Epoch: {}, Iter: {}, D_loss: {:.4}, G_loss:{:.4}'.format(epoch, iter_count, d_total_loss.item(), g_loss.item())) imgs_numpy = deprocess_img(fake_images.data.cpu().numpy()) show_images(imgs_numpy[0:16]) plt.savefig('plt_img/%d.png'% iter_count) plt.close() viz.line([d_total_loss.item()], [iter_count], win='D_loss', update='append') viz.line([g_loss.item()], [iter_count], win='G_loss', update='append') iter_count += 1 checkpoint = { "net_D": D.state_dict(), "net_G": G.state_dict(), 'D_optim':D_optim.state_dict(), 'G_optim':G_optim.state_dict(), "epoch": epoch } torch.save(checkpoint, 'checkpoints/ckpt_%s.pth' %(str(epoch))) print('checkpoint of epoch %d has been saved!'%epoch) def preprocess_img(x): x = transforms.ToTensor()(x) return (x - 0.5) / 0.5 #把preprocess_img的操作逆回来 def deprocess_img(x): return (x + 1.0) / 2.0 train_set = MNIST( root='dataset/', train=True, download=True, transform=preprocess_img ) train_data = DataLoader( dataset=train_set, batch_size=batch_size, # sampler=ChunkSampler(NUM_TRAIN, 0) #从第0个开始,采样NUM_TRAIN个 ) val_set = MNIST( root='dataset/', train=False, download=True, transform=preprocess_img ) val_data = DataLoader( dataset=val_set, batch_size=batch_size, # sampler=ChunkSampler(NUM_VAL, NUM_TRAIN) ) # print(len(train_set))# 是 391 # print(len(val_set))# 是 40 viz = Visdom() viz.line([0.], [0.], win='G_loss', opts=dict(title='G_loss')) viz.line([0.], [0.], win='D_loss', opts=dict(title='D_loss')) bce_loss = nn.BCEWithLogitsLoss() D = discriminator().cuda() G = generator().cuda() D_optim = torch.optim.Adam(D.parameters(), lr=3e-4, betas=(0.5, 0.999)) G_optim = torch.optim.Adam(G.parameters(), lr=3e-4, betas=(0.5, 0.999)) train_gan(D, G, D_optim, G_optim, ls_discriminator_loss, ls_generator_loss, num_epochs=500)
最终能学到是这个样子
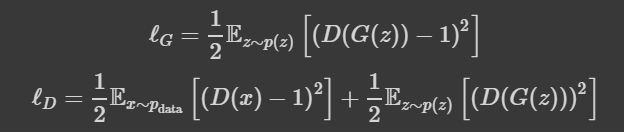


















 2014
2014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









