







准备:
系统盘raid1或raid5,数据盘直通或raid0,电口为集群网络,用作osd守护进程之间的复制、恢复、心跳,光口为存储网络,用作对外存储流量
下载cephadm:https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadm
yum install --downloadonly docker-ce --downloaddir=/root/offline-pkg/docker-ce
yum install --downloadonly python3 --downloaddir=/root/offline-pkg/python3
添加官方源ceph.repo,可更换为国内源
./cephadm add-repo --release Octopus
yum install --downloadonly cephadm --downloaddir=/root/offline-pkg/cephadm
yum install --downloadonly ceph-common --downloaddir=/root/offline-pkg/ceph-common
Default container images
DEFAULT_IMAGE = ‘quay.io/ceph/ceph:v15’
DEFAULT_IMAGE_IS_MASTER = False
DEFAULT_PROMETHEUS_IMAGE = ‘quay.io/prometheus/prometheus:v2.18.1’
DEFAULT_NODE_EXPORTER_IMAGE = ‘quay.io/prometheus/node-exporter:v0.18.1’
DEFAULT_ALERT_MANAGER_IMAGE = ‘quay.io/prometheus/alertmanager:v0.20.0’
DEFAULT_GRAFANA_IMAGE = ‘quay.io/ceph/ceph-grafana:6.7.4’
所有节点:
设置主机名:
hostnamectl set-hostname ceph1
hostnamectl set-hostname ceph2
配置hosts解析:
cat >> /etc/hosts <<EOF
ip1 ceph1
ip2 ceph2
ip3 ceph3
EOF
时间同步至第一节点:
vi /etc/chrony.conf
server ceph1 iburst
systemctl restart chronyd
systemctl enable chronyd
安装docker-ce、python3:
rpm -ivh /root/ceph-install/offline-pkg/docker-ce/.rpm
rpm -ivh /root/ceph-install/offline-pkg/python3/.rpm
docker load -i /root/offline-pkg/image/ceph.tar
docker load -i /root/offline-pkg/image/ceph-grafana.tar
docker load -i /root/offline-pkg/image/prometheus.tar
docker load -i /root/offline-pkg/image/alertmanager.tar
docker load -i /root/offline-pkg/image/node-exporterr.tar
ceph1节点:
时间源:
vi /etc/chrony.conf
allow all
local stratum 10
修改后的离线版cephadm添加执行权限
chmod +x cephadm
./cephadm --help
安装ceph-common、cephadm:
rpm -ivh /root/ceph-install/offline-pkg/ceph-common/*.rpm
ceph -v
rpm -ivh /root/ceph-install/offline-pkg/cephadm/*.rpm
which cephadm
引导新集群:
cephadm bootstrap --mon-ip ip1 --cluster-network ip/mask
引导命令产生以下结果:
1、为本地主机上创建新集群的monitor和manager守护程序
2、ssh密钥:/root/.ssh/authorized_keys
3、与新集群通信的最小配置文件:/etc/ceph/ceph.conf
4、client.admin的特权级管理密钥的副本放在/etc/ceph/ceph.client.admin.keyring
5、公钥副本放在/etc/ceph/ceph.pub
成功如下所示:
Ceph Dashboard is now available at:
URL: https://ceph1:8443/
User: admin
Password: 28n1ce5qc8
You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid 569eaaec-d4f0-11ed-8a92-000c29737e01 -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
Bootstrap complete.
ceph1公钥免密:
ssh-copy-id -f -i /etc/ceph/ceph.pub ceph2
ssh-copy-id -f -i /etc/ceph/ceph.pub ceph3
添加新主机
ceph orch host add ceph2
ceph orch host add ceph3
若成功会自动扩展mon和mgr节点
ceph -s
安装osd
前置条件:设备无分区、无lvm相关状态、无已挂载、无文件系统、无Ceph Bluestore存储引擎、大于5G
查看所有osd:ceph orch device ls
查看单机osd:ceph orch device ls --hostname=ip --wide --refresh
测试全安装:ceph orch apply osd --all-available-devices --dry-run
正式全安装:ceph orch apply osd --all-available-devices
单主机安装:ceph orch daemon add osd ip:/dev/标识
默认情况:集群内发现新硬盘会自动创建osd;若移除osd,其上数据会自动迁移,可以通过命令禁用该功能:ceph orch apply osd --all-available-devices --unmanaged=true
补充
删除单个osd:ceph orch osd rm <osd_id(s)> [–replace] [–force]
停止删除osd:ceph orch osd rm stop <osd_id(s)>
删除单机上的所有osd:ceph orch device zap
删除主机:ceph orch host drain
查看删除进程:ceph orch osd rm status
查看是否单机是否包含ceph相关守护进程:ceph orch ps
强制删除:ceph orch host rm --offline --force
扫描设备:ceph orch host rescan [–with-summary]
其他
RGW:是Ceph对象存储网关服务RADOS Gateway的简称,是一套基于librado接口封装而实现的FastCGI服务
libvirt:是用于管理虚拟化平台的开源api、后台程序、管理工具。它可以用于管理kvm、Xen、esxi,qemu等
librbd:是ceph基于对象存储librados之上实现的块存储接口librbd、krbdqemu,客户端都是通过它进行块设备卷的io访问
libvirt的rbd存储需要在其他ceph节点上能执行ceph的命令,所以:
mkdir -p /etc/ceph
scp /etc/ceph/ceph* ceph2:/etc/ceph
scp /etc/ceph/ceph* ceph3:/etc/ceph
crushmap
1、crush算法通过计算数据存储位置来确定如何存储和检索,授权客户端直接连接osd
2、对象通过算法被切分成数据片,分布在不同的osd上
3、提供很多种的bucket,最小的节点是osd
#结构
osd (or device)
host #主机
chassis #机架
rack #机柜
row
pdu
pod
room #机房
datacenter #数据中心
zone #区域
region #地区
root #最高:根
#查看crushmap
ceph osd crush tree
ceph osd tree
# 查看详细
ceph osd crush dump
#查看规则
ceph osd crush rule ls
#某个规则关联起来的pool
ceph osd pool get xxxxx crush_rule
举例
环境: 一个pool包含3个host,多个osd,通过不同crushmap rule分隔,数据按照不同pool rule落盘。
1、先做crushmap文件备份
2、修改引起大量pg变更,后期不要动
3、调整配置osd crush update on start = false,
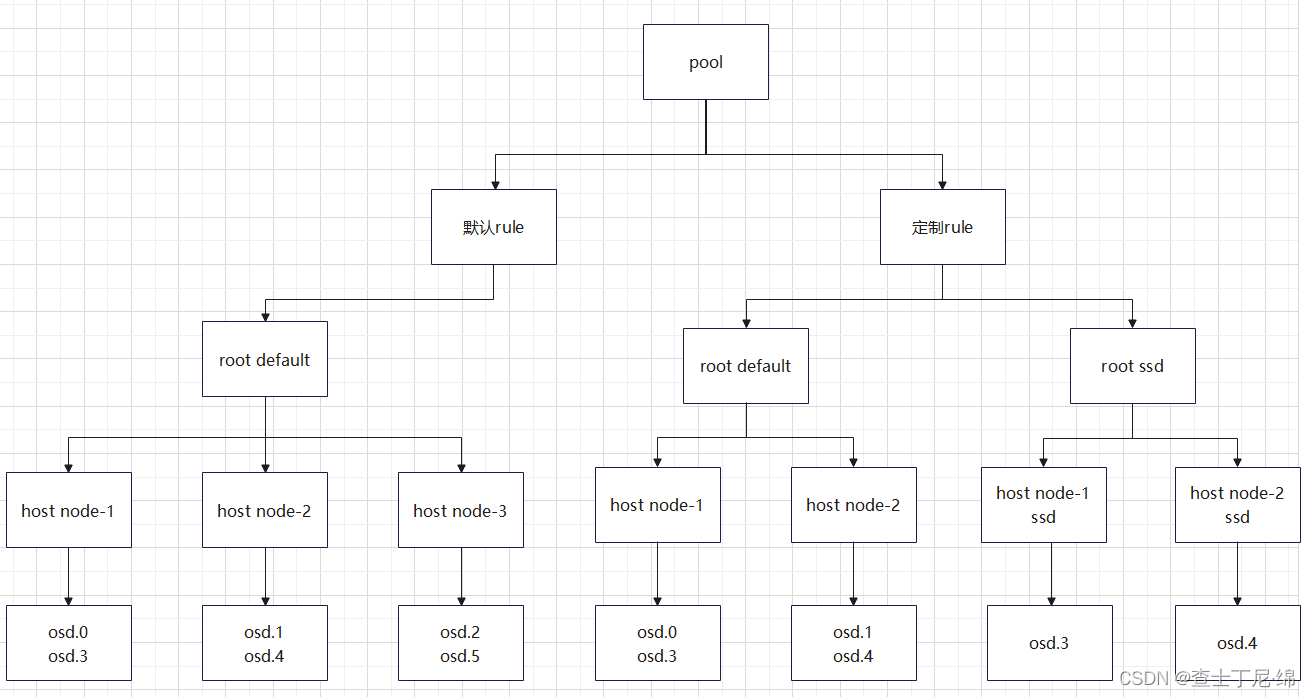
#创建root类型bucket,ssd是名称
ceph osd crush add-bucket ssd-bucket root
# 添加host类型bucket
ceph osd crush add-bucket node-1-ssd-bucket host
ceph osd crush add-bucket node-2-ssd-bucket host
# host bucket移到root bucket中去
ceph osd crush move node-1-ssd-bucket root=ssd-bucket
ceph osd crush move node-2-ssd-bucket root=ssd-bucket
# 把osd移到host bucket中
ceph osd crush move osd.3 host=node-1-ssd-bucket root=ssd-bucket
ceph osd crush move osd.4 host=node-2-ssd-bucket root=ssd-bucket
ceph osd tree
#规则名称、rootbucket名称、容灾机制(默认default)、host类型、磁盘类型
#创建一条名为ssd-demo的新rule,将基于ssd的OSD作为复制池的目标
ceph osd crush rule create-replicated ssd-rule ssd-bucket host ssd
#关联pool和规则
ceph osd pool set ceph-ssd crush_rule ssd-rule














 2244
2244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









