







1.实验目的
- 了解与熟悉MapReduce基本原理;
- 掌握MapReduce程序实现词频统计的方法;
- 掌握MapReduce程序实现数据连接的方法。
2.实验内容及结果截屏
(1)MapReduce程序实现词频统计
①map函数
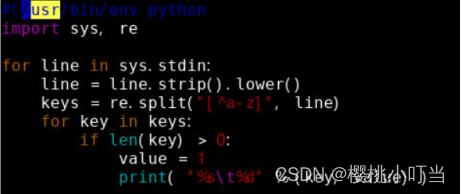
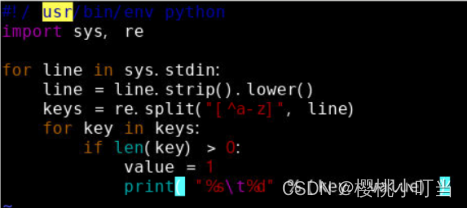
创建map函数的Python脚本mapper.py:
![]()
②reduce函数
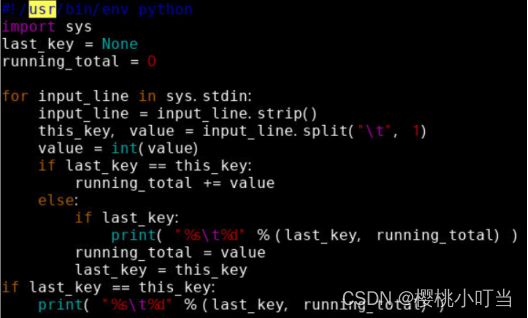
创建reduce函数的Python脚本reducer.py:
![]()
③本地测试
在提交到Hadoop执行前,先在本地进行测试。
使用chmod命令开放脚本的执行权限:
![]()
根据之前章节的例子,使用echo命令和输出重定向,创建一个仅有3行内容的文本文件test.txt:

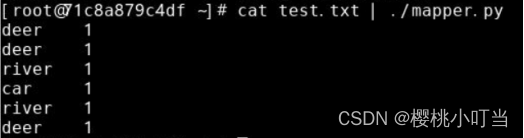
使用cat命令将文本输出,并用管道|将其作为脚本mapper.py的标准输入,执行脚本mapper.py,查看Map阶段的输出:
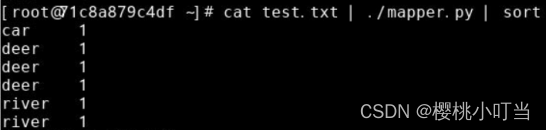
进一步加入管道|,并使用sort命令按字母排序,查看Reduce阶段的输入:
进一步加入管道|,并执行脚本reducer.py,查看Reduce阶段的输出:

④数据准备
使用hdfs dfs -put命令从本地文件系统将文件夹/opt/data/novels上传到到HDFS:
![]()
⑤提交到Hadoop集群执行
使用hadoop jar命令将MapReduce程序提交到Hadoop集群执行:
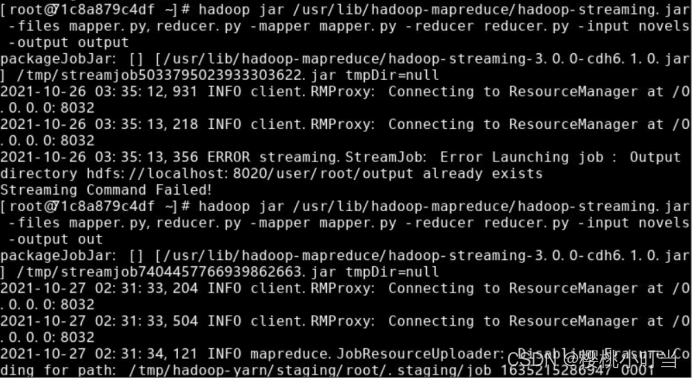
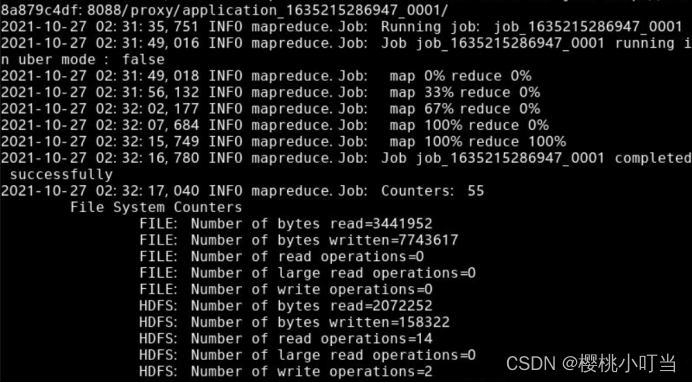
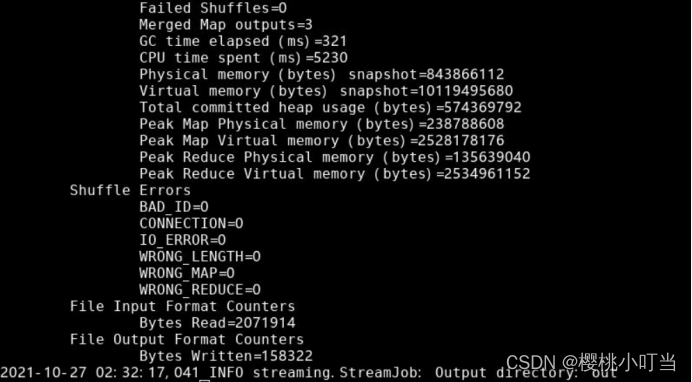
⑥查看结果
使用hdfs dfs -ls命令显示文件(夹)统计信息:
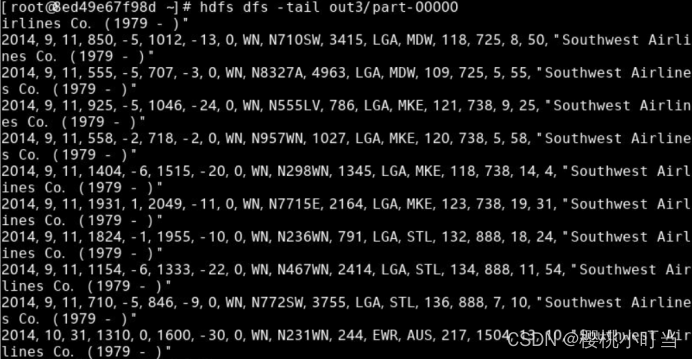
 使用hdfs dfs -tail命令显示文件末尾1KB内容:
使用hdfs dfs -tail命令显示文件末尾1KB内容:
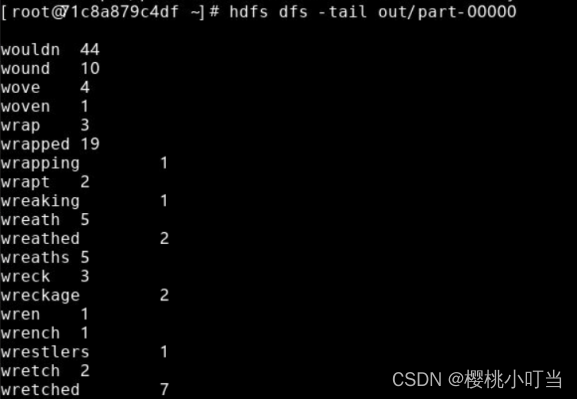
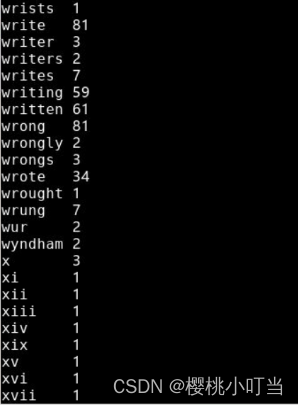
(2)MapReduce程序的Reducer数量
①Hadoop流处理命令中,指定选项numReduceTasks表示Reducer数量,这里设为3:
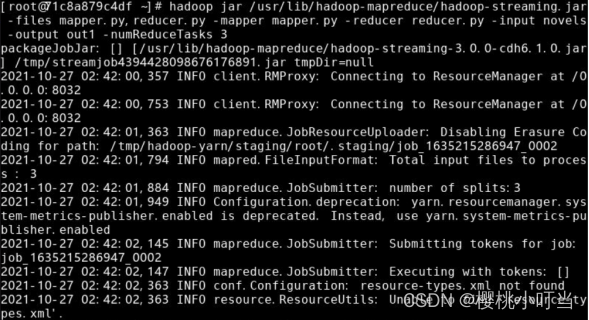
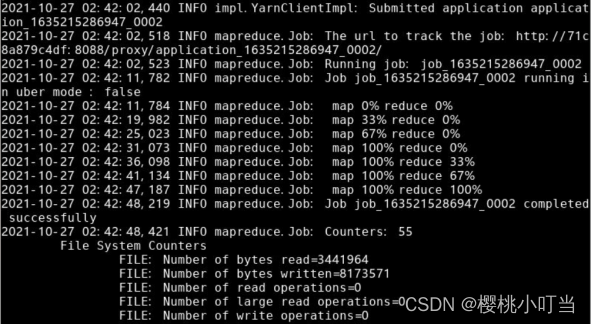
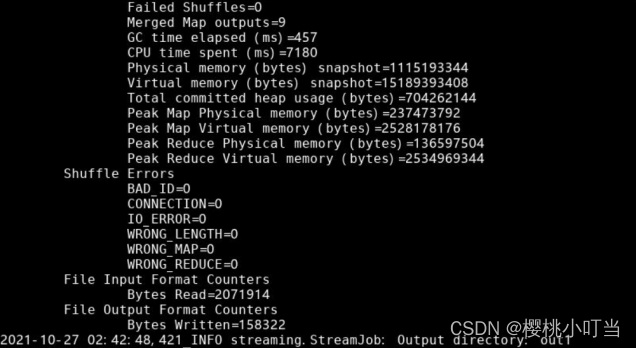
②使用命令hdfs dfs -ls显示文件(夹)统计信息:

(3)MapReduce程序的Combiner
①Hadoop流处理命令中,指定选项combiner表示Combiner函数脚本:
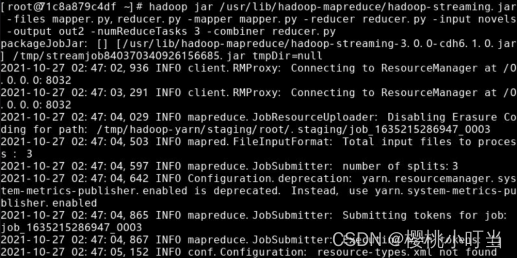
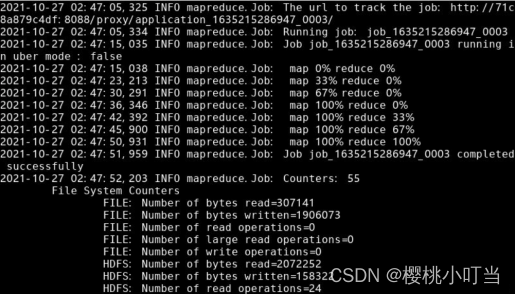
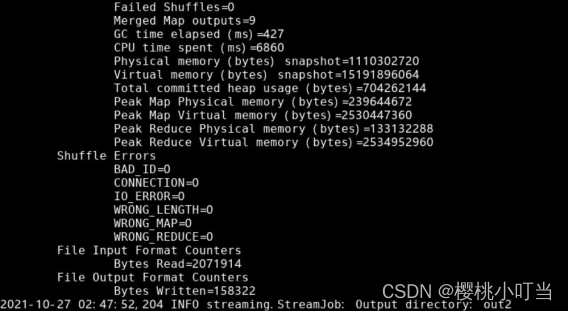
(4)MapReduce程序实现数据连接
第一个数据集的路径为/opt/data/flights/flights14.csv:
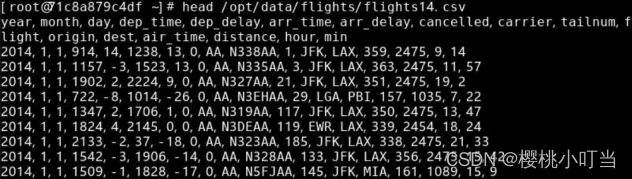
第二个数据集的路径为/opt/data/flights/carrier.csv: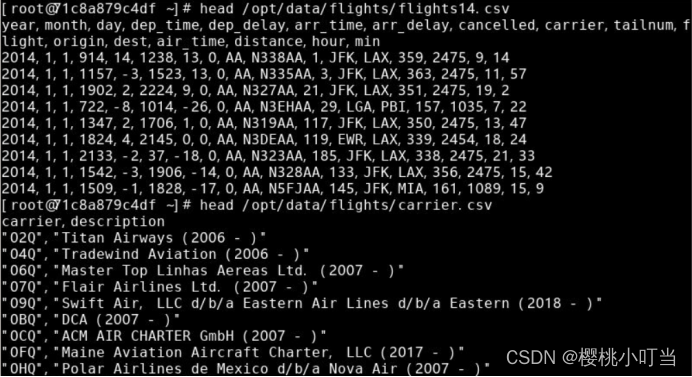
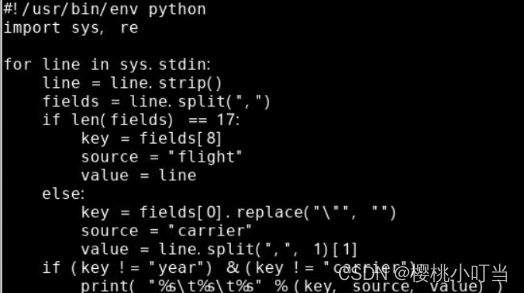
①map函数
创建map函数的Python脚本join_mapper.py:
![]()
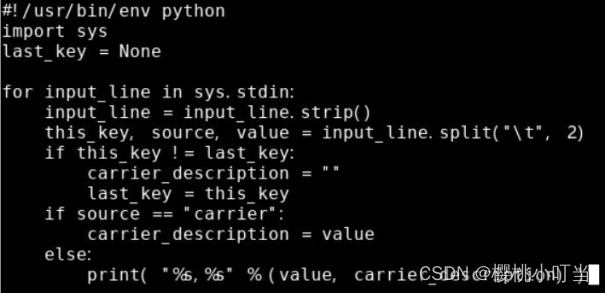
②reduce函数
创建reduce函数的Python脚本join_reducer.py:
![]()
③本地测试
创建一个测试文本文件flights14_sample.csv,为航班准点情况数据的一小部分:
![]()

创建另一个测试文本文件carrier_sample.csv,为航空公司简写与描述映射数据的一小部分:
![]()

使用chmod命令开放脚本的执行权限:
![]()
使用cat命令将文件flights14_sample.csv输出,并用管道|将其作为脚本join_mapper.py的标准输入,执行脚本join_mapper.py,查看Map阶段的输出:

对文件carrier_sample.csv做同样操作:

进一步加入管道|,并使用sort命令按字母排序,查看Reduce阶段的输入:
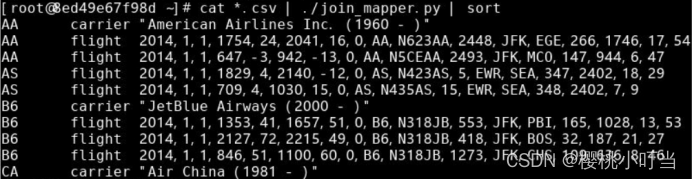
进一步加入管道|,并执行脚本join_reducer.py,查看Reduce阶段的输出:
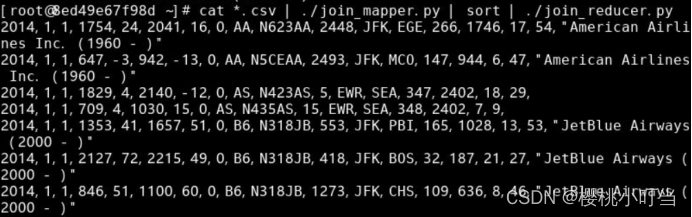
④数据准备
使用hdfs dfs -put命令从本地文件系统将文件夹/opt/data/flights上传到到HDFS:
![]()
⑤提交到Hadoop集群执行
使用hadoop jar命令将MapReduce程序提交到Hadoop集群执行:
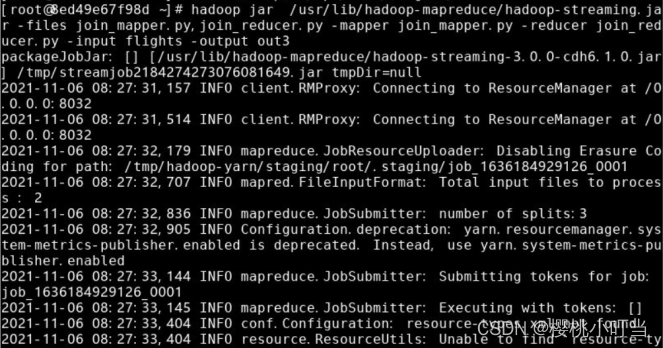
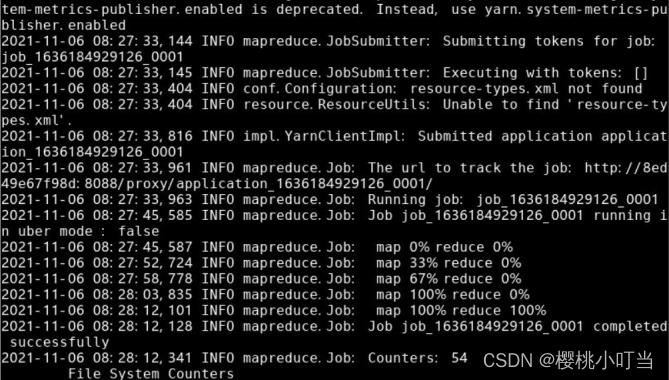

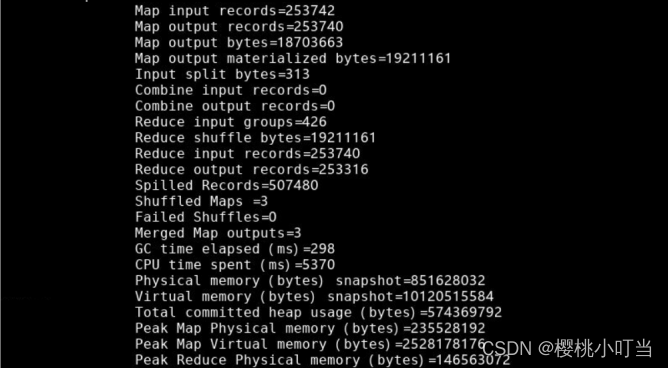
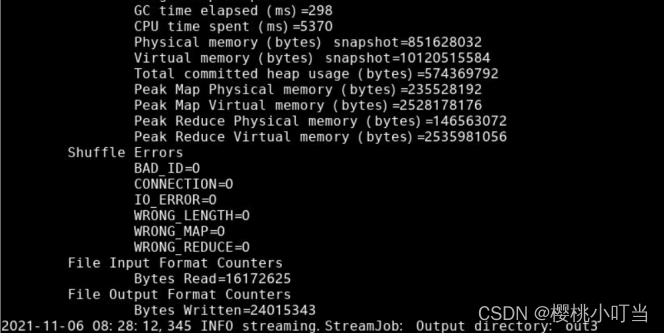
⑥查看结果
使用hdfs dfs -ls命令显示文件(夹)统计信息:

使用hdfs dfs -tail命令显示文件末尾1KB内容:
3.实验分析及小结
通过此次实验,我对MapReduce的基本原理有了一定的了解与熟悉,同时对MapReduce程序实现词频统计、数据连接的方法也有了一定掌握。
由于步步紧跟实验指导,在实验过程中我并没有遇到太多问题,只有一些细小的错误。
例如在编辑mapper.py时多输入了一个空格,导致报了如下错误:
![]()
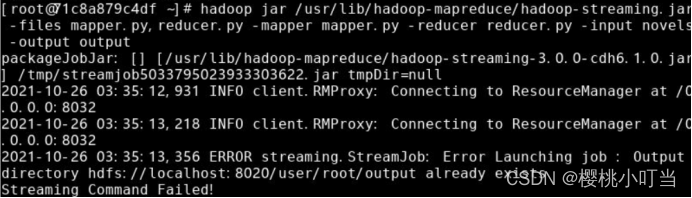
再例如使用hadoop jar命令将MapReduce程序提交到Hadoop集群执行时,教程告诉我将文件存为output,但报错说output已存在,于是更改文件名为out,之后便不再报错了。
还有在使用hdfs dfs -tail命令显示文件末尾1KB内容时,教程中给出的语句为hdfs dfs -tail output/part-00000,但因为先前将文件存为out3,所以应当将这条语句改为hdfs dfs -tail out3/part-00000。
![]()
通过此次实验,我学习了MapReduce的相关知识,同时也提升了对代码编写的仔细程度。在之后的实验中,我会更加细心,减少可能会产生的问题。















 4980
4980











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











