






The semantic extraction part
of the proposed method in "Deep Learning-Enabled Semantic Communication Systems with Task-Unaware Transmitter and Dynamic Data".
Train the Classifier (Pragmatic Function)
1) For the MNIST dataset
import torch
import numpy as np
from torchvision.datasets import mnist # dataset
from torch.utils.data import DataLoader
# 数据变换
def data_transform(x):
x = np.array(x, dtype='float32') / 255 #转化为矩阵并用255规范化
x = (x - 0.5) / 0.5
x = x.reshape((-1,))
x = torch.from_numpy(x) #Tensor和Numpy相互转换——torch.from_numpy()
return x
# load data
trainset = mnist.MNIST('./dataset/mnist', train=True,
transform=data_transform, download=True) #下载数据,但是为class
testset = mnist.MNIST('./dataset/mnist', train=False,
transform=data_transform, download=True)
train_data = DataLoader(trainset, batch_size=64, shuffle=True) #根据batch进行数据切片,shuffle表示是否重新洗牌。
test_data = DataLoader(testset, batch_size=128, shuffle=False)这里与原文有出入,文章中设定说是5w为训练集,其实训练集为6w,测试集为1w。
可以用下面的包,看一下数据的样子。前面reshape扯为一维的了,为了看图变回28x28.
import matplotlib.pyplot as plt
#看图
a_data, a_label = trainset[0]
plt.imshow(a_data.reshape(28,28))
plt.colorbar()
plt.show() 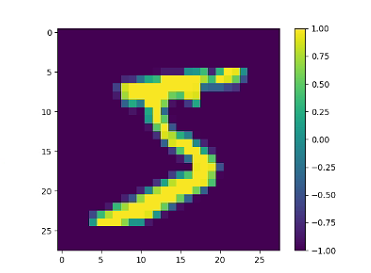
定义训练网络:
from torch import nn
import torch.nn.functional as F
#定义一个class
class MLP(nn.Module):
# classifier
def __init__(self):
super(MLP, self).__init__() #用于继承父类的init函数 继承自父类nn.Module的属性进行初始化
self.fc1 = nn.Linear(28 * 28, 500) #线性y=xA+b 输入;输出;若bias为false则不学习b。
self.fc2 = nn.Linear(500, 250)
self.fc3 = nn.Linear(250, 125)
# self.fc4 = nn.Linear(125, 10)
self.fc4 = nn.Linear(125, 10)
def forward(self, x):
# 用一下全连接层fc1,然后做一个激活。
x = F.relu(self.fc1(x)) #[64,500]
# 用一下全连接层fc2,然后做一个激活。
x = F.relu(self.fc2(x)) #[64,250]
#dim=0,按列求平均 输出 250 个值
aver_tmp = torch.mean(x, dim=0, out=None) #250
aver = torch.mean(aver_tmp, dim=0, out=None) #还是输出1个值
snr = 1
aver_noise = aver * (1 / 10 **(snr/10)) #1个值
noise = torch.randn(size=x.shape) * aver_noise #[64,250] 随机噪声
x = x + noise #[64,250]
x = F.relu(self.fc3(x)) #[64,125]
x = self.fc4(x) #[64,10]
return xnn.Module是nn中十分重要的类,包含网络各层的定义及forward方法。
定义自已的网络时,需要继承nn.Module类,并实现forward方法。
一般把网络中具有可学习参数的层放在构造函数__init__()中,不具有可学习参数的层(如ReLU)可放在构造函数中,也可不放在构造函数中(而在forward中使用nn.functional来代替)
只要在nn.Module的子类中定义了forward函数,backward函数就会被自动实现(利用Autograd)。
在forward函数中可以使用任何Variable支持的函数,毕竟在整个pytorch构建的图中,是Variable在流动。还可以使用if,for,print,log等python语法.
 https://blog.csdn.net/dongjinkun/article/details/114575998
https://blog.csdn.net/dongjinkun/article/details/114575998mlp = MLP() #创建实例类
criterion = nn.CrossEntropyLoss() #调用交叉熵损失函数
# SGD 就是随机梯度下降
optimizer = torch.optim.SGD(mlp.parameters(), 1e-3)
#mlp.parameters()参数包含weight以及b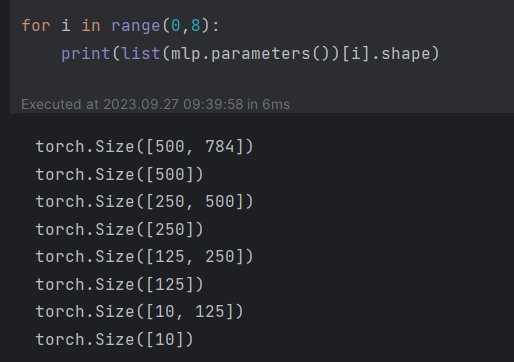
训练以及测试:
losses = []
acces = []
eval_losses = []
eval_acces = []
for e in range(20):
train_loss = 0
train_acc = 0
mlp.train()
for im, label in train_data:
im = Variable(im) #[64,784]
label = Variable(label) #[64]
# forward
out = mlp(im) #[64,10] #最后输出的10 表示0~9种类别
loss = criterion(out, label) #tensor(2.3046, grad_fn=<NllLossBackward0>)
# backward
optimizer.zero_grad() # 将模型的参数梯度初始化为0
loss.backward() # 反向传播计算梯度
optimizer.step() # 更新所有参数
train_loss += loss.item()
_, pred = out.max(1) #每行最大值,以及索引
num_correct = (pred == label).sum().item() #分类对的个数
acc = num_correct / im.shape[0] #占比 im.shape[0]=64
train_acc += acc
losses.append(train_loss / len(train_data)) #938epoch
acces.append(train_acc / len(train_data))
eval_loss = 0
eval_acc = 0
mlp.eval()
for im, label in test_data:
im = Variable(im)
label = Variable(label)
out = mlp(im)
loss = criterion(out, label)
eval_loss += loss.item()
_, pred = out.max(1)
num_correct = (pred == label).sum().item()
acc = num_correct / im.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_data))
eval_acces.append(eval_acc / len(test_data))
print('epoch: {}, Train Loss: {:.6f}, Train Acc: {:.6f}, Eval Loss: {:.6f}, Eval Acc: {:.6f}'
.format(e, train_loss / len(train_data), train_acc / len(train_data),
eval_loss / len(test_data), eval_acc / len(test_data)))
得到的结果之一:
epoch: 0, Train Loss: 2.282670, Train Acc: 0.206706, Eval Loss: 2.258480, Eval Acc: 0.315467
最后保存结果:
# save the model
torch.save(mlp.state_dict(), 'MLP_MNIST.pkl')2) For the CIFAR10 dataset
import sys
sys.path.append("...")添加上一级目录。
import numpy as np
import torch
from torch.autograd import Variable
from torch import nn
from torchvision.datasets import CIFAR10
def conv_relu(in_channels, out_channels, kernel, stride=1, padding=0):
layer = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel, stride, padding),
nn.BatchNorm2d(out_channels, eps=1e-3),
nn.ReLU(True)
)
return layerpytorch教程之nn.Sequential类详解——使用Sequential类来自定义顺序连接模型-CSDN博客
简单理解为一个容器。
定义inception模块:
class inception(nn.Module):
def __init__(self, in_channel, out1_1, out2_1, out2_3, out3_1, out3_5, out4_1):
super(inception, self).__init__()
# the first line
self.branch1x1 = conv_relu(in_channel, out1_1, 1)
# the second line
self.branch3x3 = nn.Sequential(
conv_relu(in_channel, out2_1, 1),
conv_relu(out2_1, out2_3, 3, padding=1)
)
# the thrid line
self.branch5x5 = nn.Sequential(
conv_relu(in_channel, out3_1, 1),
conv_relu(out3_1, out3_5, 5, padding=2)
)
# the fourth line
self.branch_pool = nn.Sequential(
nn.MaxPool2d(3, stride=1, padding=1),
conv_relu(in_channel, out4_1, 1)
)
def forward(self, x):
# forward
f1 = self.branch1x1(x)
f2 = self.branch3x3(x)
f3 = self.branch5x5(x)
f4 = self.branch_pool(x)
output = torch.cat((f1, f2, f3, f4), dim=1) #tensor拼接
return output
check一下输入输出是否一致:
test_net = inception(3, 64, 48, 64, 64, 96, 32)
test_x = Variable(torch.zeros(1, 3, 96, 96))
print('input shape: {} x {} x {}'.format(test_x.shape[1], test_x.shape[2], test_x.shape[3]))
test_y = test_net(test_x)
print('output shape: {} x {} x {}'.format(test_y.shape[1], test_y.shape[2], test_y.shape[3]))
定义goolenet:
class googlenet(nn.Module):
def __init__(self, in_channel, num_classes, verbose=False):
super(googlenet, self).__init__()
self.verbose = verbose
self.block1 = nn.Sequential(
conv_relu(in_channel, out_channels=64, kernel=7, stride=2, padding=3),
nn.MaxPool2d(3, 2)
)
self.block2 = nn.Sequential(
conv_relu(64, 64, kernel=1),
conv_relu(64, 192, kernel=3, padding=1),
nn.MaxPool2d(3, 2)
)
self.block3 = nn.Sequential(
inception(192, 64, 96, 128, 16, 32, 32),
inception(256, 128, 128, 192, 32, 96, 64),
nn.MaxPool2d(3, 2)
)
self.block4 = nn.Sequential(
inception(480, 192, 96, 208, 16, 48, 64),
inception(512, 160, 112, 224, 24, 64, 64),
inception(512, 128, 128, 256, 24, 64, 64),
inception(512, 112, 144, 288, 32, 64, 64),
inception(528, 256, 160, 320, 32, 128, 128),
nn.MaxPool2d(3, 2)
)
self.block5 = nn.Sequential(
inception(832, 256, 160, 320, 32, 128, 128),
inception(832, 384, 182, 384, 48, 128, 128),
nn.AvgPool2d(2)
)
self.classifier = nn.Linear(1024, num_classes)
def forward(self, x):
x = self.block1(x)
if self.verbose:
print('block 1 output: {}'.format(x.shape))
x = self.block2(x)
if self.verbose:
print('block 2 output: {}'.format(x.shape))
x = self.block3(x)
if self.verbose:
print('block 3 output: {}'.format(x.shape))
x = self.block4(x)
if self.verbose:
print('block 4 output: {}'.format(x.shape))
x = self.block5(x)
if self.verbose:
print('block 5 output: {}'.format(x.shape))
x = x.view(x.shape[0], -1)
x = self.classifier(x)
return x
view=reshape python中view()函数怎么用?_view函数-CSDN博客
深度学习|经典网络:GoogLeNet(一) - 知乎 (zhihu.com) https://zhuanlan.zhihu.com/p/73857137
https://zhuanlan.zhihu.com/p/73857137
check一下输出:
test_net = googlenet(3, 10, True)
test_x = Variable(torch.zeros(1, 3, 96, 96))
test_y = test_net(test_x)
print('output: {}'.format(test_y.shape))定义预处理:
def data_tf(x):
x = x.resize((96, 96), 2) # shape of x: (96, 96, 3)
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5
x = x.transpose((2, 0, 1))
x = torch.from_numpy(x)
return x下载数据:
train_set = CIFAR10('./data', train=True, transform=data_tf, download=True)
train_data = torch.utils.data.DataLoader(train_set, batch_size=64, shuffle=True)
test_set = CIFAR10('./data', train=False, transform=data_tf, download=True)
test_data = torch.utils.data.DataLoader(test_set, batch_size=128, shuffle=False)net = googlenet(3, 10) #输入3通道 输出为10
optimizer = torch.optim.SGD(net.parameters(), lr=0.01)
criterion = nn.CrossEntropyLoss()定义ACC函数:
def get_acc(output, label):
total = output.shape[0]
_, pred_label = output.max(1)
num_correct = (pred_label == label).sum().item()
return num_correct / totalfrom datetime import datetime
def train(net, train_data, valid_data, num_epochs, optimizer, criterion):
if torch.cuda.is_available():
net = net.cuda()
prev_time = datetime.now()
for epoch in range(num_epochs):
train_loss = 0
train_acc = 0
net = net.train()
for im, label in train_data:
if torch.cuda.is_available():
im = Variable(im.cuda())
label = Variable(label.cuda())
else:
im = Variable(im)
label = Variable(label)
# forward
output = net(im)
loss = criterion(output, label)
# backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += get_acc(output, label)
cur_time = datetime.now()
h, remainder = divmod((cur_time - prev_time).seconds, 3600)
m, s = divmod(remainder, 60)
time_str = "Time %02d:%02d:%02d" % (h, m, s)
if valid_data is not None:
valid_loss = 0
valid_acc = 0
net = net.eval()
for im, label in valid_data:
if torch.cuda.is_available():
im = Variable(im.cuda(), volatile=True)
label = Variable(label.cuda(), volatile=True)
else:
im = Variable(im, volatile=True)
label = Variable(label, volatile=True)
output = net(im)
loss = criterion(output, label)
valid_loss += loss.item()
valid_acc += get_acc(output, label)
epoch_str = (
"Epoch %d. Train Loss: %f, Train Acc: %f, Valid Loss: %f, Valid Acc: %f, "
% (epoch, train_loss / len(train_data),
train_acc / len(train_data), valid_loss / len(valid_data),
valid_acc / len(valid_data)))
else:
epoch_str = ("Epoch %d. Train Loss: %f, Train Acc: %f, " %
(epoch, train_loss / len(train_data),
train_acc / len(train_data)))
prev_time = cur_time
print(epoch_str + time_str)
torch.save(net.state_dict(), 'google_net.pkl')
train(net, train_data, test_data, 20, optimizer, criterion)Train the Semantic Extraction Part
1) For the MNIST dataset

import torch
from torchvision.datasets import mnist
import torch.nn.functional as F
from torch.utils.data import DataLoader
import pandas as pd
import numpy as np
import copy
import torch
from torch import nn
import scipy
from torch.autograd import Variable
from PIL import Image














 311
311

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









