






语义通信
语义通信的目的是 “达意”来提高通信效率,关注数据的含义。
特定任务:
2019年,Bourtsoulatze等[10]提出了一种用于无线图像传输的联合信源信道编码方案。该方案利用卷积神经网络提取语义特征并直接编码为信道输入符号,与JPEG和JPEG2000相比更适应低信噪比(SNR, Signal-to-Noise Ratio)场景,而且不会受到“悬崖效应”的影响。
广义任务:
在文献[16]中,Zhang等考虑了这一点,然后设计了一种用于图像传输的语义通信方案。在该方案中,接收端网络引导语义编码网络学习提取和传输语义信息。实验结果表明,该方案能够在数据恢复和任务执行方面保持高性能。

摘要
该系统由语义编码网络semantic coding(SC)和数据自适应网络 data adaptation(DA)组成。
语义信息被视为 可观察信息的隐藏特征,语义信息与可观察信息之间的关系没有直接给出。是面向任务的信息,不是可观察信息的固有属性。(例如,对于图像上的物体识别和目标检测的语义信息是不同的。)通常,发送方不知道任务,只有接受方知道,这是知识库不共享的现实条件。此外,测试数据(真正传输的数据)与训练数据是不同的,防止过拟合。
接收器主导的动态语义通信系统,发送器不知道语用任务,且应对两个挑战:1)接收方指导发送方编码;2)自适应网络(网络分准备和工作两个阶段,不同阶段的数据的分布不同)数据动态。
两个目标:语用任务和可观察信息的重构。
相关工作
A.语义信息的定义
通常情况,自相矛盾的句子应该包含大量信息,但是接收方却认为没有信息【16】。由此,语义信息出现,它基于真值而不是概率分布,也可以被定义为随机信息源的相对重要性等等。
B.基于神经网络的语义通信
提出很多系统,这些系统可以根据数据分布、任务和通道状态自动学习提取和传输语义信息。训练神经网络NN作为语义编辑器和解码器,以某一度量(KL散度或者二次损失)来恢复语义信息。
C.数据自适应(DA)
将源域样本转换为目标域样本。
系统模型
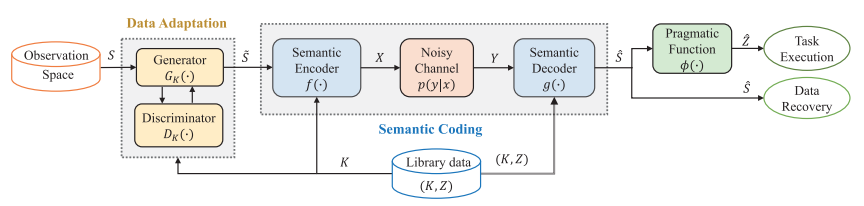
三个网络分两个阶段训练:第一阶段,编码器f和解码器g进行联合训练,f的目的是提取和传输包含最多语义信息的可观测信息的数据,g的目的是重构与语用任务相关的数据和经验数据。第二阶段,训练Gk,并且一个鉴别器来帮助训练。
语义编码网络
A.语义编码网络训练
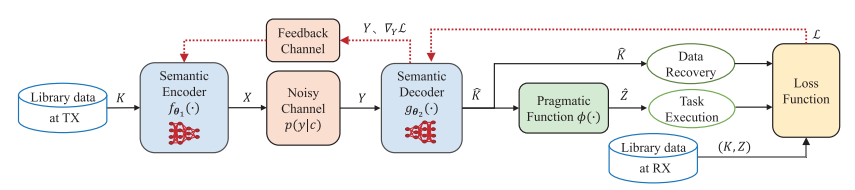
f θ1 和g θ2分别是两个深度神经网络DNNs,其中θ1和 θ2分别是参数集合。从K中抽取Kt训练样本,t=1,2,...,发射器编码:![]() ,接收方重构:
,接收方重构:![]() ;语用任务输出:
;语用任务输出:![]() 完整的训练样本
完整的训练样本![]() (仅对于接收端完整)。
(仅对于接收端完整)。
损失函数可以表示为:![]() ,可以采用Adam算法【46】更新参数:
,可以采用Adam算法【46】更新参数: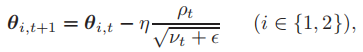 其中,pt和vt分别为梯度的一阶和二阶动量,e为了防止分母为零,n为学习率。
其中,pt和vt分别为梯度的一阶和二阶动量,e为了防止分母为零,n为学习率。
对于接收端:![]()
但,对于发送方,因为缺少Z信息,所以: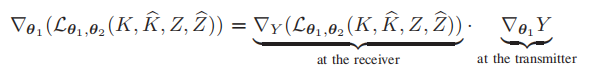
这也保证了一定的安全性,因为接收方单单从![]() 上不足以知道Z。
上不足以知道Z。
整个算法:

B.语义编码的损失函数的设计
一般有两个失真约束:语义信息损失和可观察信息损失。
语义失真SD:语义编码器和解码器联合优化:
![]()
其中,Dob和Dpr函数分别为对K和Z的失真衡量函数,可以为KL散度,交叉熵,MSE等。
再次强调,语义信息是由特定任务决定的,而不是源的固有特征。所以定义SD时,同时考虑K和Z。
对于训练样本,使用经验SD(ESD):
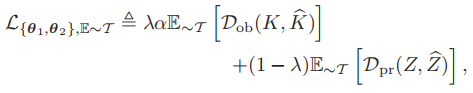
其中,E~T()是经验分布。
对于SD中的超参数λ,文章给定了一个初始值,但是实际使用不是一个固定值。
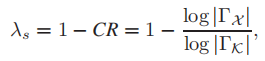
语义通信作为一种编码速率有限的有损联合信源通道,压缩率CR取值范围在【0,1】。当压缩率较大时,即CR趋近1,λ趋近于0,“当压缩率较大时,我们的语义编码器可以选择对语义信息Z进行编码,也可以选择对非语义信息K进行编码,其性能收敛于传统编码器。在压缩率较小的情况下,语义编码器可以给予语义信息较高的优先级,并相应地收敛为语用编码器。”????
因此,联合优化问题可以写为: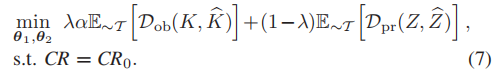
Dpr因为语用任务的不同而不同,如果是分类任务,输出为离散变量,那么Dob选择MSE,Dpr选择交叉熵: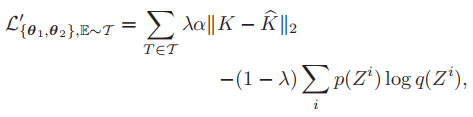
如果是图像分割任务,我们将Dob和Dpr都设置为MSE: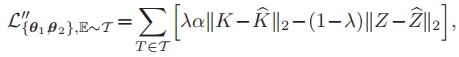
域自适配网络
A.域适配架构
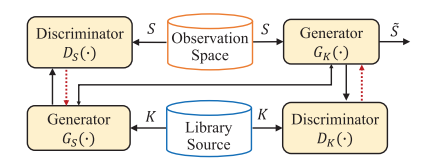
基于循环GAN,实现域自适应的功能。Gk为转换函数,S转换为S~;对应一个判别器Dk,用于判别S~和K之间的差别,并反馈(红色虚线);此外,还有一个发生器Gs和判别器Ds做相对应的转换。虽然DA中有两对,但是在推理阶段只需要Gk。
敌对损失函数: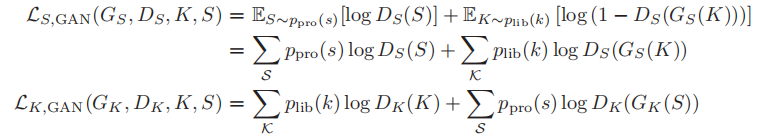
循环损失函数: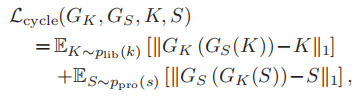
总损失函数:
![]()
![]()

B.两个数据集之间的相似性度量。.....这里不展开
实验结果部分
信息瓶颈理论:激活函数相比于卷积函数或全连接函数,更容易导致更大的信息损失。因此,语义编码器不包含激活函数。在语义编码器输出处还增加了一个额外的规范化层,以确保传输功率约束。在整个实验中,AWGN通道的信噪比(SNR)设置为3dB和10dB,分别代表低信噪比和高信噪比。
A.Experiments on Semantic Coding Network
分别在三个任务上进行评估:MNIST手写数字识别,在CIFAR-10数据集上的图像分类,以及在PASCAL-VOC2012数据集上的图像分割。
比较:基方案 传统的分离源信道编码(SSCC),它采用JPEG2000[57]进行图像压缩,并采用容量实现编码,以每个信道使用log (1+ SNR)比特的速率进行可靠的信道传输。因此,JPEG2000的压缩率应该是我们提出的神经网络编码器的压缩率乘以log(1 + SNR)。第二种是基于变分自编码器(VAE)的语义通信[58],具有KL散度损失,为方便起见,写成基于VAE的方法。请注意,我们选择VAE而不是标准的自编码器,因为现有的实验表明,VAE可以更好地响应噪声的影响[58],[59]。
MNIST数字识别的语义通信:MNIST数据集由60,000张图像组成,每张图像都是28 × 28灰度像素的手写数字[60]。在数据集中,50000张图片用于训练,剩下的10000张图片用于测试。
语用函数φ已经训练好。
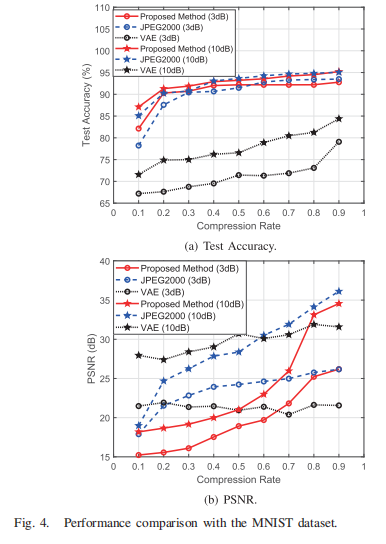 两个指标,不同的信噪比(3dB,10dB),两个对比方法。
两个指标,不同的信噪比(3dB,10dB),两个对比方法。
从图4(a)中可以看出,当CR < 0.4时,本文方法在所有考虑的方案中准确率最高,而VAE方法在所有不同CR下的准确率最差,这是因为本文提出的损失函数可以根据可观测信息和实用信息的重要性进行加权,依据不同的压缩率CR。当CR较低时,建议的方案将优先考虑确保任务的执行,即。数字识别的准确性。当CR大于0.2时,本文方法与基于jpeg2000的方法在3dB和10dB信噪比上均有微小差异。其中,当CR ∈[0.1,0.4]时,本文方法的识别精度较好,而当CR ∈[0.6,0.9]时,基于jpeg2000的方法的识别精度略好。
从a中可以看出,所提出的方法的优势并不明显,这是因为数据集中的样本非常简单,可以以非常低的压缩率进行编码,而信息损失可以忽略不计,这使得JSCC(基于联合信源信道编码)相对于SSCC的性能优势非常小。
而且在b中,可以看出所提出的方法都没有性能优势,但是随着CR变大,性能变好,这与所提出的损失函数设计相吻合。
这可以看出权衡,当压缩率较低时,使用任务的优先级会损害图像重建的性能,但是较高时,又回到图像重建性能中。
2)CIFAR-10图像分类同样。
 图像恢复较为清晰。
图像恢复较为清晰。
3)图像分割

所提出的方法可以恢复轮廓,但是细节不行。















 1058
1058











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









