








大数据技术AI
Flink/Spark/Hadoop/数仓,数据分析、面试,源码解读等干货学习资料
121篇原创内容
公众号
1、函数
1.1 窗口函数
-
FIRST_VALUE:取分组内排序后,截止到当前行,第一个值
-
LAST_VALUE:取分组内排序后,截止到当前行,最后一个值
-
LEAD(col,n,DEFAULT) :用于统计窗口内往后第n行值。
-
第一个参数为列名,
-
第二个参数为往下第n行(可选,默认为1),
-
第三个参数为默认值(当往下第n行为NULL时候,取默认值,如不指定,则为NULL)
-
LAG(col,n,DEFAULT) :用于统计窗口内往前第n行值。
-
第一个参数为列名,
-
第二个参数为往上第n行(可选,默认为1),
-
第三个参数为默认值(当往上第n行为NULL时候,取默认值,如不指定,则为NULL)
1.2 over从句
-
使用标准的聚合函数
COUNT、SUM、MIN、MAX、AVG -
使用
PARTITION BY语句,使用一个或者多个原始数据类型的列 -
使用**
PARTITION BY与ORDER BY**语句,使用一个或者多个数据类型的分区或者排序列
使用窗口规范,窗口规范支持以下格式:
(ROWS | RANGE) BETWEEN (UNBOUNDED | [num]) PRECEDING AND ([num] PRECEDING | CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN CURRENT ROW AND (CURRENT ROW | (UNBOUNDED | [num]) FOLLOWING)
(ROWS | RANGE) BETWEEN [num] FOLLOWING AND (UNBOUNDED | [num]) FOLLOWING
注意:
-
当
ORDER BY后面缺少窗口从句条件,窗口规范默认是RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW. -
当**
ORDER BY和窗口从句都缺失**, 窗口规范默认是ROW BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING.
1.3 分析函数
- ROW_NUMBER()
从1开始,按照顺序,生成分组内记录的序列。
比如,按照pv降序排列,生成分组内每天的pv名次,ROW_NUMBER()的应用场景非常多,再比如,获取分组内排序第一的记录;获取一个session中的第一条refer等。
数据顺序:1234
数据排名:1234
- RANK()
生成数据项在分组中的排名,排名相等会在名次中留下空位,如果有重复的,会跳数。
数据顺序:1234
数据排名:1224
- DENSE_RANK()
生成数据项在分组中的排名,排名相等会在名次中不会留下空位,如果有重复的,不会跳数。
数据顺序:1234
数据排名:1223
- CUME_DIST
小于等于当前值的行数/分组内总行数。比如,统计小于等于当前薪水的人数,所占总人数的比例
- PERCENT_RANK
分组内当前行的RANK值-1/分组内总行数-1
- NTILE(n)
用于将分组数据按照顺序切分成n片,返回当前切片值,如果切片不均匀,默认增加第一个切片的分布。
NTILE不支持ROWS BETWEEN:比如 NTILE(2) OVER(PARTITION BY cookieid ORDER BY createtime ROWS BETWEEN 3 PRECEDING AND CURRENT ROW)。
2、案例
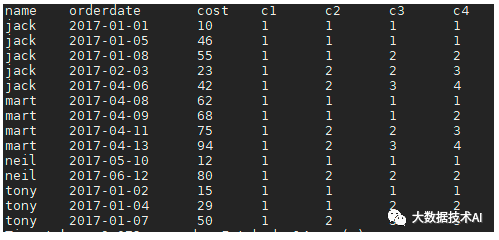
2.1 数据集准备
hive (default)> select * from student;
OK
business.name business.orderdate business.cost
jack 2017-01-01 10
tony 2017-01-02 15
jack 2017-02-03 23
tony 2017-01-04 29
jack 2017-01-05 46
jack 2017-04-06 42
tony 2017-01-07 50
jack 2017-01-08 55
mart 2017-04-08 62
mart 2017-04-09 68
neil 2017-05-10 12
mart 2017-04-11 75
neil 2017-06-12 80
mart 2017-04-13 94
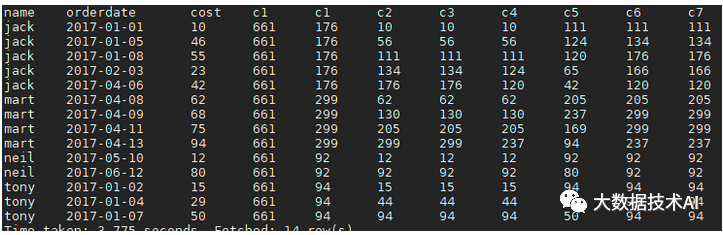
2.2 COUNT、SUM、MIN、MAX、AVG
select name,orderdate,cost,
-- 所有行相加
sum(cost) over() as c1,
-- 按name分组,组内相加
sum(cost) over(partition by name) as c1,
-- (默认起点到当前行相加)按name分组,orderdate排序,组内相加
sum(cost) over(partition by name order by orderdate) as c2,
-- 起点到当前行的
sum(cost) over(partition by name order by orderdate rows between unbounded preceding and current row ) as c3,
-- 当前行+前面2行
sum(cost) over(partition by name order by orderdate rows between 2 preceding and current row ) as c4,
-- 当前行+后面2行
sum(cost) over(partition by name order by orderdate rows between current row and 2 following ) as c5,
-- 前面2行+当前行+后面2行
sum(cost) over(partition by name order by orderdate rows between 2 preceding and 2 following ) as c6,
-- (partition by .. order by)可替换为(distribute by .. sort by ..)
sum(cost) over(partition by name order by orderdate rows between 2 preceding and 2 following ) as c7
from business;
注意:
-
结果和ORDER BY相关,默认为升序
-
如果不指定ROWS BETWEEN,默认为从起点到当前行;
-
如果不指定ORDER BY,则将分组内所有值累加;
-
order by必须跟在partition by后;
-
Rows必须跟在Order by子;
-
(partition by … order by)可替换为(distribute by … sort by …)
Window子句:
-
PRECEDING:往前
-
FOLLOWING:往后
-
CURRENT ROW:当前行
-
UNBOUNDED:无界限(起点或终点)
-
UNBOUNDED PRECEDING:表示从前面的起点
-
UNBOUNDED FOLLOWING:表示到后面的终点
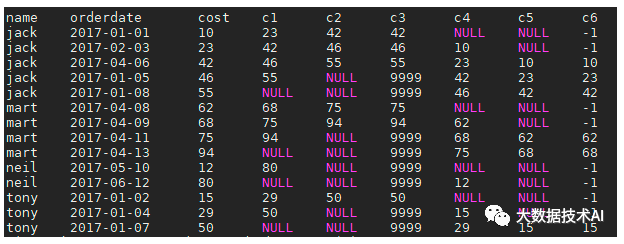
2.3 first_value与last_value
select name,orderdate,cost,
row_number() over(partition by name order by cost) c1,
-- 正序时:当前行到第一个值之间,第一个值
first_value(cost) over(partition by name order by cost) c2,
-- 正序时:当前行到最后一个值之间,最后一个值
last_value(cost) over(partition by name order by cost) c3,
-- 倒序时:当前行到第一个值之间,第一个值
first_value(cost) over(partition by name order by cost desc) c4,
-- 倒序时:当前行到最后一个值之间,最后一个值
last_value(cost) over(partition by name order by cost desc) c5,
row_number() over(partition by name order by cost desc) c6
from business;
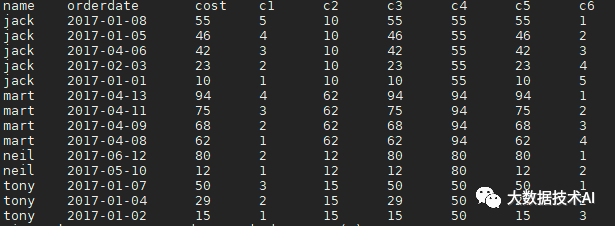
2.4 lead与lag
select name,orderdate,cost,
-- 分组内当前行,往后第一行的值(不包括当前行)
lead(cost) over(partition by name order by cost) c1,
-- 分组内当前行,往后第二行的值(不包括当前行)
lead(cost,2) over(partition by name order by cost) c2,
-- 分组内当前行,往后第二行的值(不包括当前行),如果为null,则用9999代替
lead(cost,2,9999) over(partition by name order by cost) c3,
-- 分组内当前行,往前第一行的值(不包括当前行)
lag(cost) over(partition by name order by cost) c4,
-- 分组内当前行,往前第二行的值(不包括当前行)
lag(cost,2) over(partition by name order by cost) c5,
-- 分组内当前行,往前第二行的值(不包括当前行),如果为null,则用-1代替
lag(cost,2,-1) over(partition by name order by cost) c6
from business;
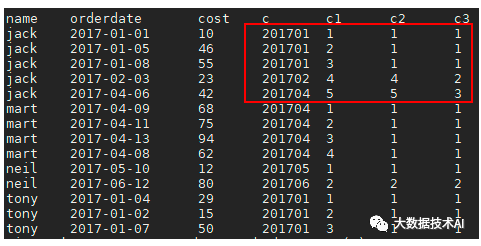
2.5 RANK、ROW_NUMBER、DENSE_RANK
select
name,orderdate,cost,c,
-- 自然序号排序,不跳数,不重复
ROW_NUMBER() over(partition by name order by c) c1,
-- 排序相同,中间会跳数,总数不变
RANK() over(partition by name order by c) c2,
-- 排序相同,中间不会跳数,总数会减少
DENSE_RANK() over(partition by name order by c) c3
from(
select name,orderdate,cost,date_format(orderdate,'yyyyMM') c
from business
)T;
2.6 NTILE
select name,orderdate,cost,
-- 将组内数据分成1片
ntile(1) over(partition by name order by orderdate) c1,
-- 将组内数据分成2片
ntile(2) over(partition by name order by orderdate) c2,
-- 将组内数据分成3片
ntile(3) over(partition by name order by orderdate) c3,
-- 将组内数据分成4片
ntile(4) over(partition by name order by orderdate) c4
from business;
注意:
如果切片不均匀,默认增加第一个切片的分布
例如:求20%的数据(按时间排序)
select * from(
select name,orderdate,cost,
-- 查询20%时间的订单
ntile(5) over(order by orderdate) c
from business
)T where c=1;
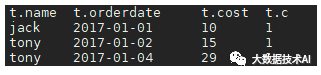
2.7 CUME_DIST、PERCENT_RANK
CUME_DIST
select name,orderdate,cost,
-- 不分组,所有数据为一组,当前行占总行数的比例,
-- 第一行:1/14=0.07142857142857142
-- 第二行:2/14=0.14285714285714285
CUME_DIST() over(order by orderdate) ,
-- 组内,计算当前行的行数/组内总行数
CUME_DIST() over(partition by name order by orderdate)
from business;
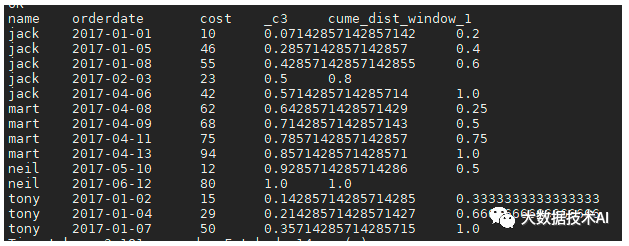
PERCENT_RANK
select name,orderdate,cost,
-- 按name分组,组内的行数
sum(1) over(partition by name),
-- 所有数据,按时间排序,排名
rank() over(order by orderdate),
-- (排名-1)/(总行数-1)
-- 第1行:排名1,(1-1)/(14-1)= 0
-- 第2行:排名4,(4-1)/(14-1)= 0.23076923076923078
-- 第3行:排名6,(6-1)/(14-1)= 0.38461538461538464
PERCENT_RANK() over(order by orderdate),
-- (组内当前行-1) / (当前组总行-1)
-- 第1行:(1-1)/(5-1)=0
-- 第2行:(2-1)/(5-1)=0.25
-- 第3行:(3-1)/(5-1)=0.5
PERCENT_RANK() over(partition by name order by orderdate)
from business;
















 1733
1733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









