









Per-Job 新老版本启动方法
- 老版本(<=1.10)
flink run -m yarn-cluster -c xxx xxx.jar
- 新版本(>=1.11)
flink run -t yarn-per-job -c xxx xxx.jar
Per-Job 启动的三个进程
-
CliFrontend
-
参数解析
-
封装CommandLine
-
封装配置
-
执行用户代码 execute()
-
生成StreamGraph
-
Executor:生成JobGraph
-
集群描述器:上传jar包、配置, 封装提交给yarn的命令
-
yarnclient提交应用
-
YarnJobClusterEntryPoint:AM执行的入口类
-
Dispatcher 的创建和启动
-
ResourceManager的创建、启动(slotmanager真正的管理资源,向yarn申请资源)
-
Dispatcher 启动 JobMaster。生成ExecutionGraph(slotpool,真正的发送请求)
-
slotpool向slotmanger申请资源,slotmanger向yarn申请资源(启动节点)
-
YarnTaskExecutorRunner:Yarn模式下的TaskManager的入口类
-
启动 TaskExecutor
-
向ResourceManager注册slot
-
ResouceManger分配slot
-
TaskExecutor接收到分配的指令,提供offset给JobMaster
-
JobMaster提交任务给TaskExecutor去执行
程序起点
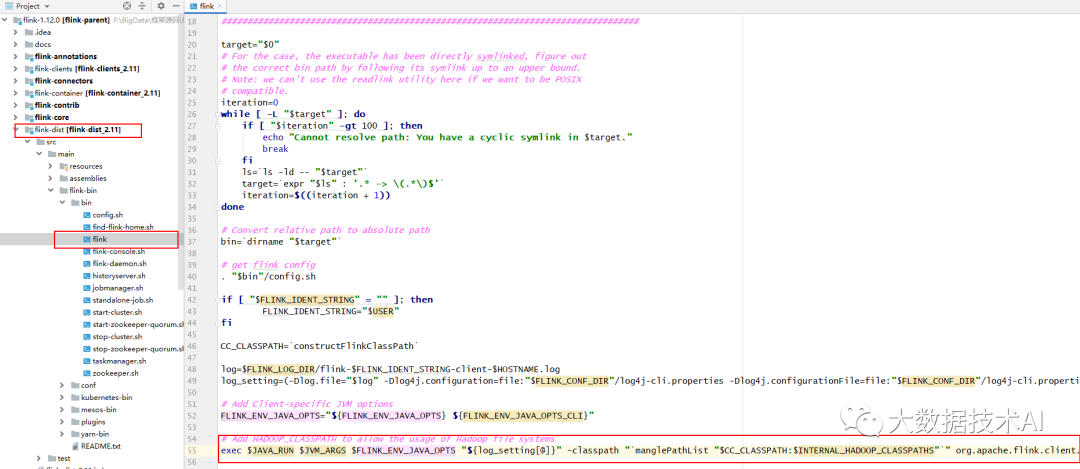
flink-1.12.0\flink-dist\src\main\flink-bin\bin\flink
#!/usr/bin/env bash
target="$0"
iteration=0
while [ -L "$target" ]; do
if [ "$iteration" -gt 100 ]; then
echo "Cannot resolve path: You have a cyclic symlink in $target."
break
fi
ls=`ls -ld -- "$target"`
target=`expr "$ls" : '.* -> \(.*\)$'`
iteration=$((iteration + 1))
done
# Convert relative path to absolute path
bin=`dirname "$target"`
# get flink config
. "$bin"/config.sh
if [ "$FLINK_IDENT_STRING" = "" ]; then
FLINK_IDENT_STRING="$USER"
fi
CC_CLASSPATH=`constructFlinkClassPath`
log=$FLINK_LOG_DIR/flink-$FLINK_IDENT_STRING-client-$HOSTNAME.log
log_setting=(-Dlog.file="$log" -Dlog4j.configuration=file:"$FLINK_CONF_DIR"/log4j-cli.properties -Dlog4j.configurationFile=file:"$FLINK_CONF_DIR"/log4j-cli.properties -Dlogback.configurationFile=file:"$FLINK_CONF_DIR"/logback.xml)
# Add Client-specific JVM options
FLINK_ENV_JAVA_OPTS="${FLINK_ENV_JAVA_OPTS} ${FLINK_ENV_JAVA_OPTS_CLI}"
# Add HADOOP_CLASSPATH to allow the usage of Hadoop file systems
exec $JAVA_RUN $JVM_ARGS $FLINK_ENV_JAVA_OPTS "${log_setting[@]}" -classpath "`manglePathList "$CC_CLASSPATH:$INTERNAL_HADOOP_CLASSPATHS"`" org.apache.flink.client.cli.CliFrontend "$@"
1)入口类(CliFrontend)
exec $JAVA_RUN $JVM_ARGS $FLINK_ENV_JAVA_OPTS "${log_setting[@]}"
-classpath "`manglePathList "$CC_CLASSPATH:$INTERNAL_HADOOP_CLASSPATHS"`"
org.apache.flink.client.cli.CliFrontend "$@"
2)config.sh 相关配置
. "$bin"/config.sh
JAVA_RUN=java
if [ "${UNAME:0:6}" == "CYGWIN" ]; then
JAVA_RUN=java
else
if [[ -d $JAVA_HOME ]]; then
JAVA_RUN=$JAVA_HOME/bin/java
else
JAVA_RUN=java
fi
fi
JAVA_ARGS=conf/flink-conf.yaml
# Arguments for the JVM. Used for job and task manager JVMs.
# DO NOT USE FOR MEMORY SETTINGS! Use conf/flink-conf.yaml with keys
# JobManagerOptions#TOTAL_PROCESS_MEMORY and TaskManagerOptions#TOTAL_PROCESS_MEMORY for that!
if [ -z "${JVM_ARGS}" ]; then
JVM_ARGS=""
fi
HADOOP_CONF_DIR=“$HADOOP_HOME/etc/hadoop”
# Check if deprecated HADOOP_HOME is set, and specify config path to HADOOP_CONF_DIR if it's empty.
if [ -z "$HADOOP_CONF_DIR" ]; then
if [ -n "$HADOOP_HOME" ]; then
# HADOOP_HOME is set. Check if its a Hadoop 1.x or 2.x HADOOP_HOME path
if [ -d "$HADOOP_HOME/conf" ]; then
# It's Hadoop 1.x
HADOOP_CONF_DIR="$HADOOP_HOME/conf"
fi
if [ -d "$HADOOP_HOME/etc/hadoop" ]; then
# It's Hadoop 2.2+
HADOOP_CONF_DIR="$HADOOP_HOME/etc/hadoop"
fi
fi
fi
# if neither HADOOP_CONF_DIR nor HADOOP_CLASSPATH are set, use some common default (if available)
if [ -z "$HADOOP_CONF_DIR" ] && [ -z "$HADOOP_CLASSPATH" ]; then
if [ -d "/etc/hadoop/conf" ]; then
echo "Setting HADOOP_CONF_DIR=/etc/hadoop/conf because no HADOOP_CONF_DIR or HADOOP_CLASSPATH was set."
HADOOP_CONF_DIR="/etc/hadoop/conf"
fi
fi
INTERNAL_HADOOP_CLASSPATHS
INTERNAL_HADOOP_CLASSPATHS="${HADOOP_CLASSPATH}:${HADOOP_CONF_DIR}:${YARN_CONF_DIR}"
if [ -n "${HBASE_CONF_DIR}" ]; then
INTERNAL_HADOOP_CLASSPATHS="${INTERNAL_HADOOP_CLASSPATHS}:${HBASE_CONF_DIR}"
fi
java -cp 就会开启 JVM 虚拟机,在虚拟机上开启 CliFrontend 进程,然后开始执行main 方法
说明:java -cp 和 -classpath 一样,是指定类运行所依赖其他类的路径。
3)运行入口类 CliFrontend
shift + shift:org.apache.flink.client.cli.CliFrontend
ctrl + F12:main
/**
* Submits the job based on the arguments.
*/
public static void main(final String[] args) {
...
}
}
















 1472
1472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









