







runtime是flink运行的状态,是flink的核心,在flink中扮演重要角色。
注:原理性的东西,对比记忆,JM,TM与hadoop的主从都是相识的,一般都是序列化,rpc,主从,资源申请,分配。
1.从源码看一下runtime有哪些东西


这是runtime的所有目录,runtime主要有client,JM,TM,RM以及dispather等
下面详细讲解一下runtime
1.1 概述
Flink RunTime是介于底层部署与DataSteamApi或DataSetApi之间的一层,以JobGraph形式接收程序,将任务task提交到集群上执行,RunTime层可以适用不同底层部署模式。Flink Runtime总体架构如下如所示:
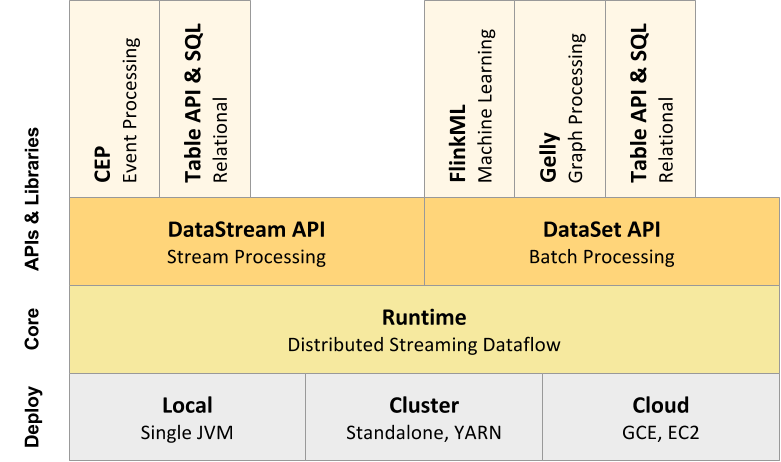
主要分为Client ,JobManager, TaskManager
Client : client并不是运行程序的一部分,用户将任务提交到JobManager, 提交之后可以断开连接或者是继续连接接收任务执行的进度等信息。
JobManager: 负责任务的分配,checkpoint的协调,以及任务失败后的故障恢复。JobManager可以有多个,但只有一个会是主节点,其他为备节点。
TaskManager 负责任务的执行和数据流的缓冲和交换,至少有一个TaskManager存在
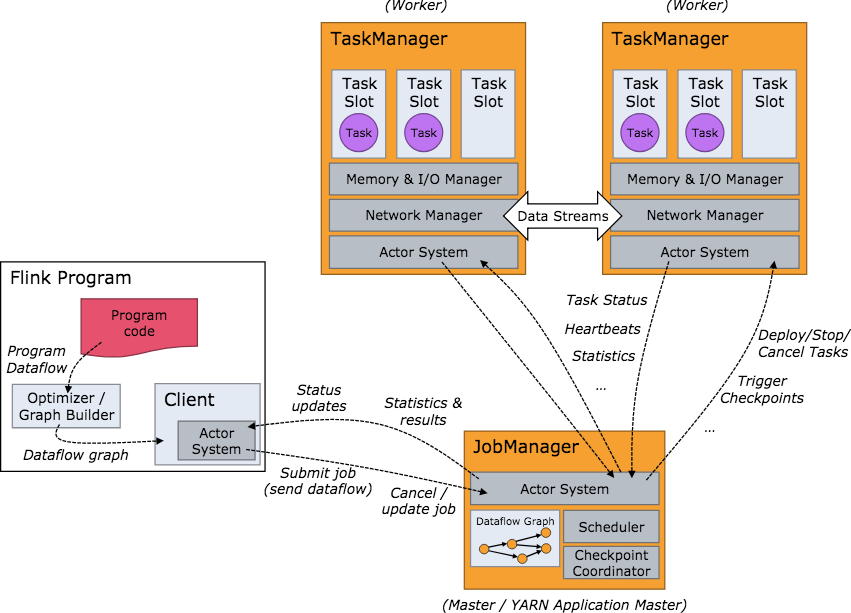
1.2 运行模式
JobManager和TaskManager可以通过多种方式启动,比如Stand-alone集群模式,容器docker,也可以是yarn, Mesos等资源调度框架。
2. 资源管理与作业调度
2.1 Task Slot管理
每个TaskManager都是一个独立的JVM进程,可以执行一个或者多个任务,为了更精细化Task的执行,引入了Task Slot的概念(注意每个TaskManager 至少有一个slot)。通过调整taskslot的个数,每个tm拥有多个slot意味着多个task可以共享一个jvm,共享tcp,心跳,数据结构,数据集等,减少每个任务的开销。
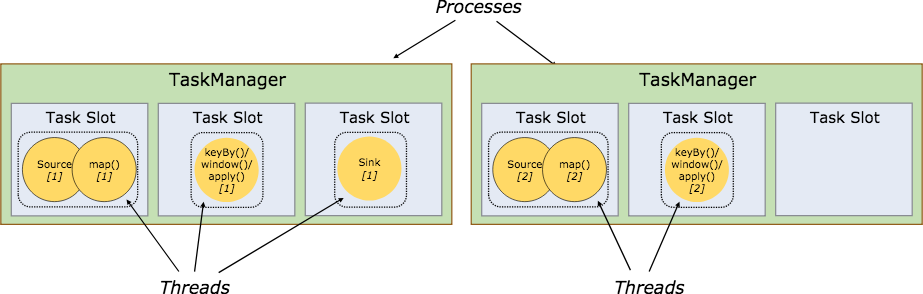
默认情况下,Flink允许自任务共享slot,即使他们不属于同一个task,只要是属于同一个job即可。这样的话一个slot可以执行一整个job的pipline。这么做的好处有2个:
Flink在执行任务时需要和并行度一样多的slot,这样就不用再去计算总共有多少的task了
可以更好的利用资源,假设没有slot共享,那么对于非密集型source/map任务需要耗费和密集型任务keyBy/widdow一样多的资源,通过slot共享将上述图中的例子可以转化为下述图,充分利用了资源(并行度从2到6),而且保证了任务的负载均衡。
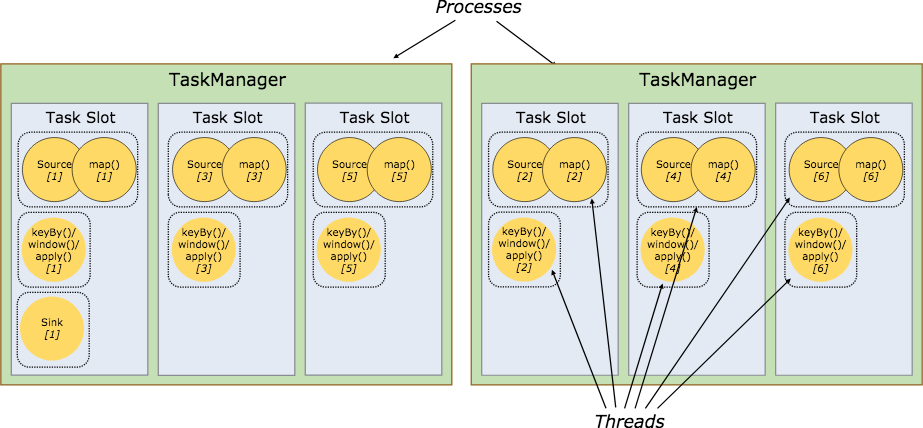
那么slot是如何保存和分配的呢?
1.在Tm启动时,tm会将自己所拥有的slot用心跳的方式汇报给jm中的Resourcemanager组件,由SlotManager进行管理。
2.当有任务提交过来到Jm后JobManager会向ResourceManager request slot,这时候ResourceManager就会分配一个Slot并向对应的Tm发送消息说,你拥有的这个slot我要分配给别人了。
3.Tm收到请求后,会回复消息给Jm说,我的这个slot分配给你了
4.Jm收到消息后,会将这个slot先缓存到slotPool中。
5.JM会将task 提交到对应的Slot
6.当task执行结束,tm会告诉resourcemanager任务结束了,这个slot被释放掉了
7.resourcemanager会更新slot状态为free,可以供后续任务申请。(tm会定时发送slot的状态过来,避免free丢失导致的slot丢失)
2.2 作业提交
Flink作业由Client提交上来的JobGraph会在执行时进行展开,称为ExecutionGraph,ExecutionGraph和具体的物理执行是一致的(这些内容我们后续源码分析再细讲)。
Flink作业提交有2种方式,一种是PerJob模式,一种是Session模式
PerJob模式
TM和AM没有提前启动
独享Dispatcher和ResourceManager组件
按需申请资源
适合执行时间长,规模较大的任务
Session模式
TM 和 AM是提前启动的
共享 Dispatcher和ResourceManager组件
资源是共享的,可以跑多个任务
适用于规模小,执行时间短的任务
我们以On-Yarn为例,描述一下任务的提交过程。主流程看下图:

PerJob模式提交任务流程:
1.Client向yarn的Resourcemanager提交一个任务
2.Resourcemanager接收到请求,启动AppMaster进程
3.Client提交JobGraph给Jm中的DisPatcher组件
4.DisPatcher将JobGraph给JobManger
5.JobManager向ResourceManager申请slot
6.ResourceManager向yarn申请container启动tm进程
7.tm进程汇报slot给ResourceManager
8.ResourceManager告诉tm分配了哪个slot给任务了
9.tm向Jm回复自己个一个slot属于你这个任务了,jm会将slot缓存到slotpool
10.jm提交task
11.task执行结束,tm告诉resourcemanager slot释放
Session模式提交任务流程:
session模式因为jm和tm是提前启动的,上述步骤的 1,2,6,7 没有,其他是一样的。
Flink作业有2中调度策略:
Eager调度 适用与流作业,一次性调度所有作业
Lazy_FROM_SOURCE 适用于批作业,上游作业完成后,调度下游作业,资源会比较省
3.错误恢复
Flink任务的错误有2大类,一种是tm执行失败(逻辑错误,tm挂了等),一种是Jm失败即Master失败,接下来看下这两种失败各自恢复的机制。
3.1 Task Failover
Restart All 重启所有Task
Restart-individual 只重启单个出错的Task
这种方式适用有限,适用与task间无连接的情况。
Restart Region
Blocking数据落盘,可以直接读取,逻辑上仅重启通过pipeline边关联的Task
(Blocking依赖是结果存储在磁盘或其他,可以重新读取。pipeline依赖一般是只数据走网络的情况)
下图中B1执行完落盘,即blocking边。
A1->B1,A2-B2到B1即Pipeline边。
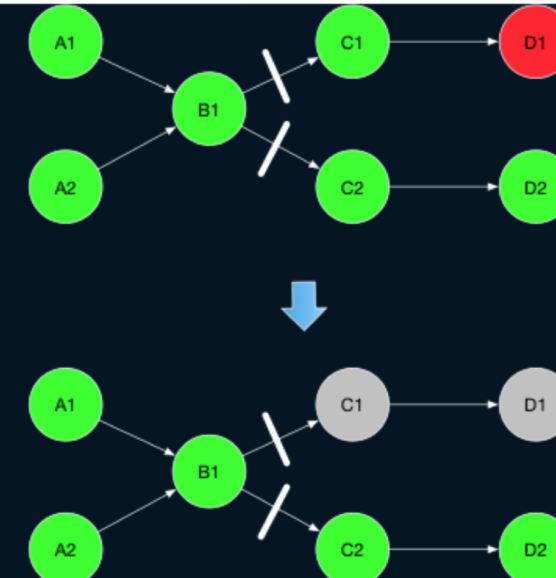
3.2 Master Failover
如果Master开启了Ha,会通过zk进行选主,备用节点会转为主节点。目前master failover会将全图重启。
在参考2篇blog是写tuntime的设计文档,主要就是讲解JM,TM,RM的功用的详细讲解。
https://www.jianshu.com/p/41a3884eefd0
https://www.jianshu.com/p/dc3d41ffcab6















 4573
4573











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









