







概述
摩尔定律
当价格不变时,集成电路上课容纳的晶体管数目,约每隔18个月便会增加一倍。
第一章
并行与并发
- 并行(Concurrency):two or more progress are in progress at the same time. 当系统有一个以上CPU时,则线程的操作有可能非并发,当一个CPU执行一个线程时,另一个CPU可以执行另一个线程,两个线程互不抢占CPU资源,可以同时进行,这种烦那个是我们称之为并行。
- 并发(Parallelism):two or more progress are executing at the same time. 当有多个线程在操作时,如果系统只有一个CPU,则它根本不可能真正同时进行一个以上的线程,它只能把CPU运行时间划分成若干个时间段,再将时间段分配给各个线程执行,在一个时间段的线程代码运行时,其它线程处于挂起状态。这种方式我们称之为并发。
- 联系:二者都是用来运行多个线程,提高系统响应性能与程序友好性,充分利用CPU资源的方式。
- 区别:并发是一个处理器以“挂起->执行->挂起”的方式同时处理多个任务,而并行是多核的处理器同时处理多个任务。


扩展性(Scalability)
- A computer system, including all its hardware and software resources, is called scalable if it can scale up (i.e. improve its resources) to accommodate ever-increasing performance and functionality demand and/or scale down (i.e. decrease its resources) to reduce cost.
- More specifically, saying a system is scalable implies the following:
– Functionality and performance
– Scaling in cost
– Compatibility
维度
- Resource Scalability
Resource scalability refers to gaining higher performance or functionality by increasing the machine size (i.e. the number of processors), investing in more storage (cache, main memory, disks), improving the software, etc. - Application Scalability
To fully exploit the power of scalable parallel computers, the application programs must also be scalable. This means the same program should run with proportionally better performance on a scaled-up system.
– e.g. A database server. - Technology Scalability
Technology scalability applies to a scalable system that can adapt to changes in technology.
– Generation (time) scalability. e.g. PC.
– Space scalability. e.g. SMP & MPP vs. Internet
– Heterogeneity scalability. e.g. PVM
加速比(重点)
- 定义:描述对程序并行化之后获得的性能收益
- 公式:加速比(nt)=最优串行算法执行时间/并行程序执行时间(nt)
Amdahl定律
- 定义:固定问题规模(工作负载),减少响应时间
- 公式:加速比 = 1/[S + (1-S)/n]
S: 程序中串行部分的比例,n: 机器规模(或处理器核的数目)
Gustafson定律
- 定义:固定计算时间,扩大问题规模,提高计算精度
- 扩展加速比=(1-S)*n + S
第二章
Flynn分类法
Flynn proposed a classification of computer systems based on a number of instruction and data streams that can be processed simultaneously.
- SISD (Single Instruction, Single Data stream)
- SIMD (Single Instruction, Multiple Data Streams)
- MISD (Multiple Instructions, Single Data Stream)
Heterogeneous systems operate on the same data stream and must agree on the result(只有理论模型) - MIMD (Multiple Instructions, Multiple Data Streams)
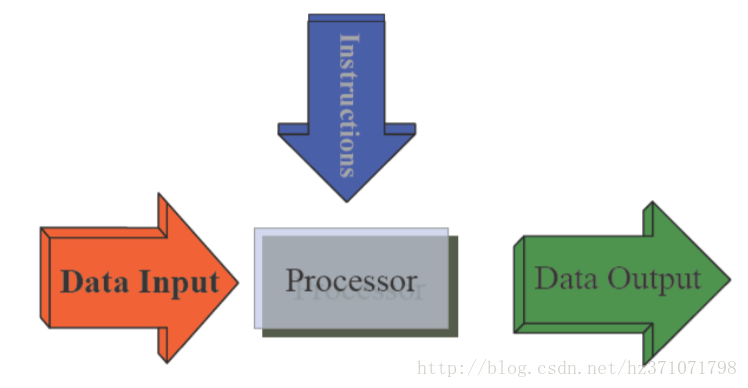

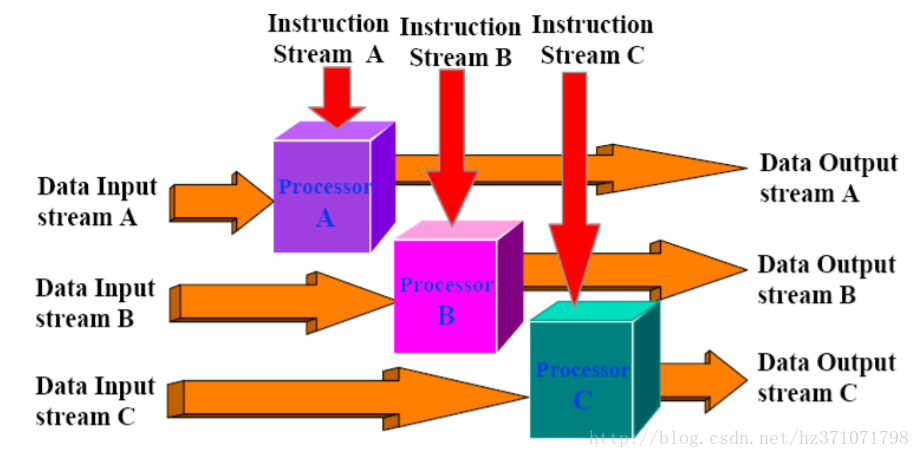
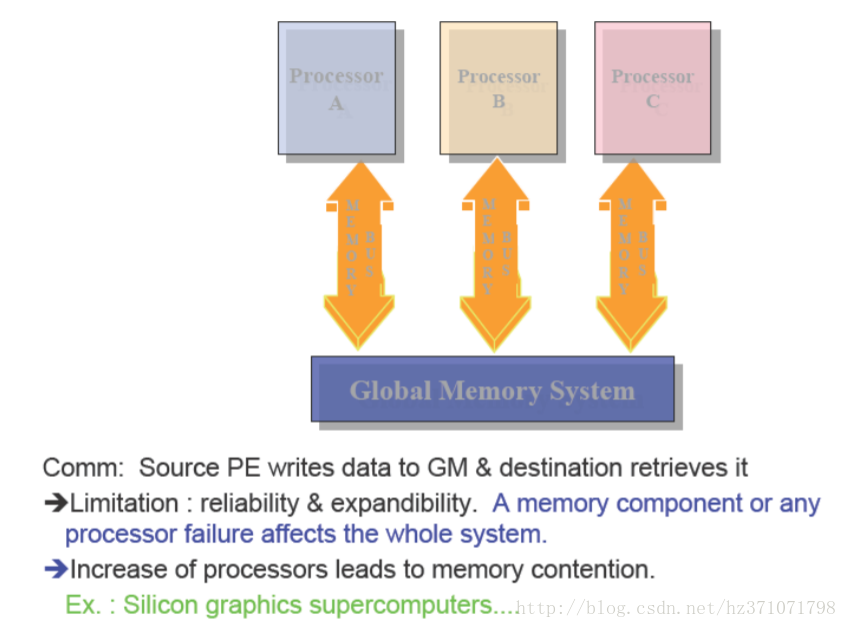
Shared Memory MIMD Machine(共享存储)
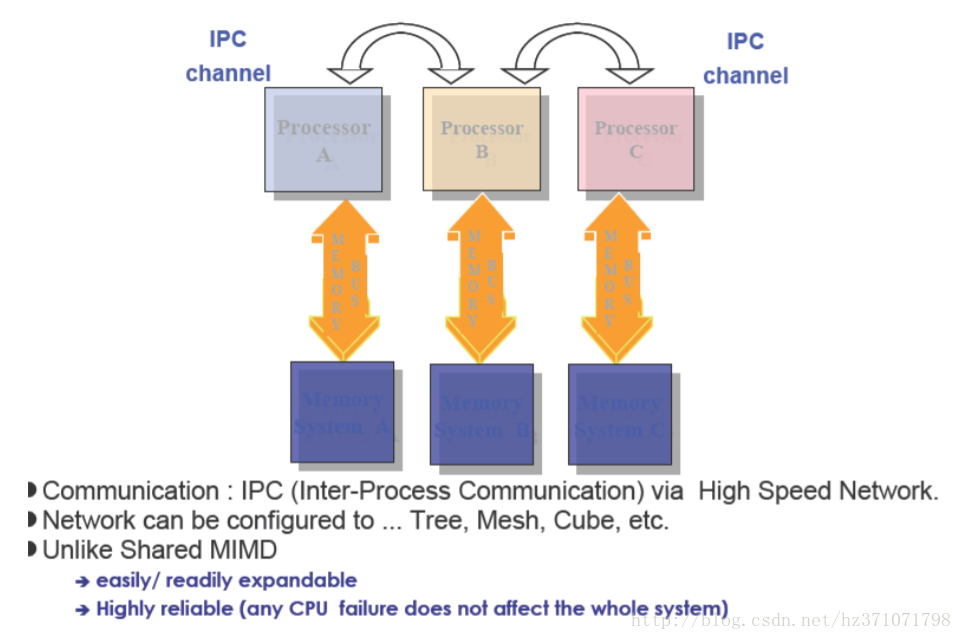
Distributed Memory MIMD(分布式存储)
存储分级
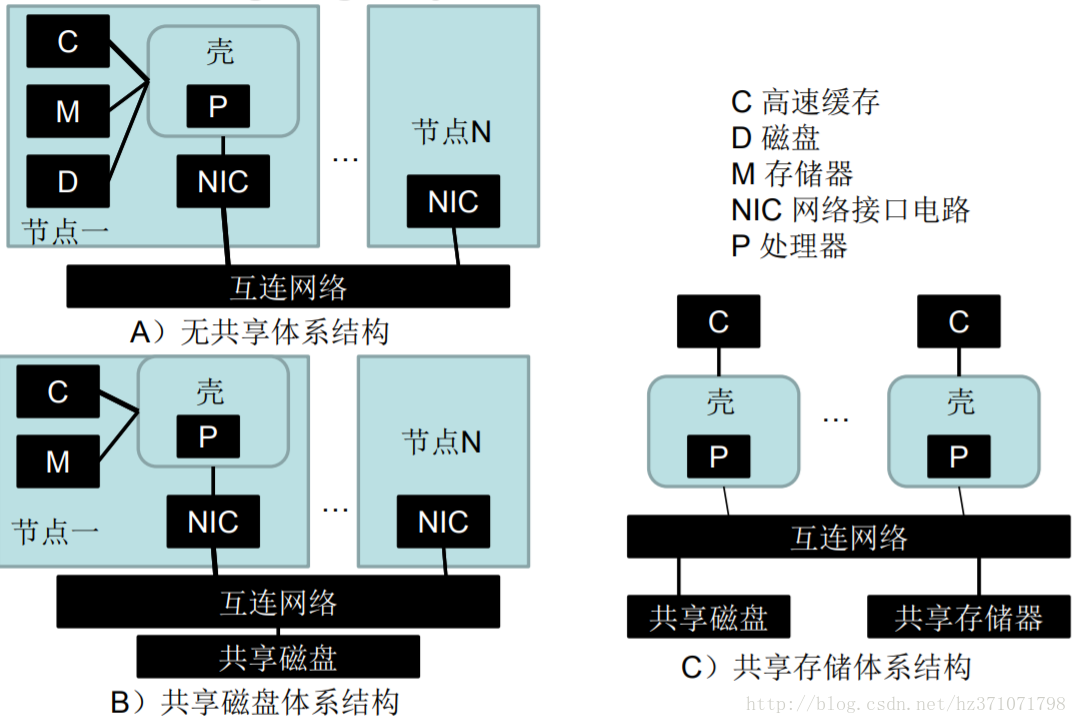
地址空间
地址空间(address space)表示任何一个计算机实体所占用的内存大小。比如外设、文件、服务器或者一个网络计算机;进程或线程可访问的地址空间。
三个操作&四个开销
三个操作
- Computation operations
Including arithmetic/logic, data transfer, control flow operations that can be found in a traditional sequential program. - Parallel operations
To manage processes/threads, such as creation and termination, context switching, and grouping. - Interaction operations
To communicate and to synchronize processes/threads.
四个开销
- Parallelism overhead caused by process/thread management.
- Communication overhead caused by processors exchanging information.
- Synchronization overhead in executing synchronization operations.
- Load imbalance overhead incurred, when some processors are idle while the others are busy.
不可并行
- Certain cryptographic hash functions一些加密Hash函数
- Newton’s method: you need each approximation in order to calculate the
next, better approximation当下一轮的运算紧密依赖于之前的运算结果时 - 当运算不可以被拆分为独立模块时
举例:递推
PRAM模型(Parallel Random Access Machine)
规模为n的PRAM模型定义:n个处理器,1个共享空间,一个公共时钟。
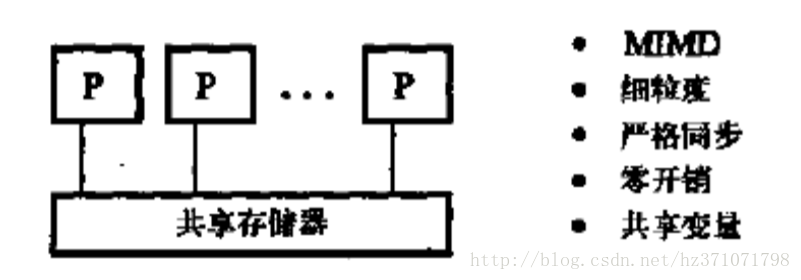
特点
- n可以无限大
- 在一个周期内,每个处理器只执行一条指令
- 只计算负载不平衡开销
- 一条指令可以是任何随机访问指令
- 地址空间:单地址空间、均匀存储器访问
- 存储器模型:EREW
APRAM模型
特点
- 每个处理器都有其本地存储器、局部时钟和局部程序
- 处理器间的通信经过共享全局存储器
- 无全局时钟,各处理器异步地独立执行各自的指令
- 处理器任何时间依赖关系需明确地在各处理器的程序中加入同步路障
- 一条指令可在非确定但有限的时间内完成。
与PRAM对比
- 每个处理器有本地存储器,处理器中的运算基于本地存储器的数据
- 各处理器在局部时钟下异步独立地执行各自的指令
- 需要在各处理器的程序中加入同步路障,在该点的处理器均需要等待别的处理器到达后才能继续执行其局部程序
BSP模型
特点
- 克服PRAM模型的缺点,保留其简单性
- 一个BSP计算机由n个处理器-存储器对(节点)组成,它们之间借助通信网络进行互连
- 分布式存储的MIMD模型
- BSP模型中,计算由一系列由同步路障分开的超步级(superstep)组成
执行超步最大时间:
T=W+gh+l
- W:每个超步内的最大计算时间
- l:路障同步开销
- G:发送每条消息的开销
- h:一个处理器在一个超步中最多发送消息数
多级存储体系结构

映射策略
- 直接映射策略(direct mapping strategy):每个内存块只能被唯一地映射到指定的一条cache line中
- n路组关联映射策略(n-way set association mapping strategy):Cache被分解为V个组,每个组由n条cache line组成,内存块按直接映射策略映射到某个组,但在该组中,内存块可以被映射到任意一条cache线
- 全关联映射策略 (full association mapping strategy):内存块可以被映射到cache中的任意一条cache line
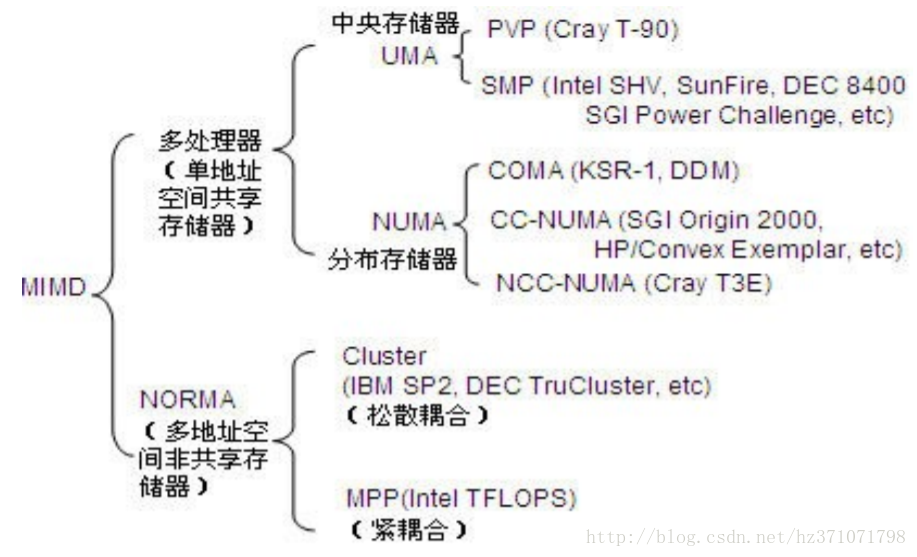
并行计算机访存模型
UMA(Uniform Memory Access)模型
- 物理存储器被所有节点共享
- 所有节点访问任意存储单元的时间相同
- 发生访存竞争时,仲裁策略平等对待每个节点,即每个节点机会均等
- 各节点的CPU可带有局部私有高速缓存
- 外围I/O设备也可以共享,且每个节点有平等的访问权利
NUMA(Non-Uniform Memory Access)模型
- 物理存储器被所有节点共享,任意节点可以直接访问任意内存模块
- 节点访问内存模块的速度不同,访问本地存储模块的速度一般是访问其他节点内存模块的3倍以上
- 发生访存竞争时,仲裁策略对节点可能是不等价的
- 各节点的CPU可带有局部私有高速缓存 (cache)
- 外围I/O设备也可以共享,但对各节点是不等价的
CC-NUMA的协议
- 写无效协议:在本地高速缓存被修改后,使得所有其它位置的数据拷贝失效
- 写更新协议:在本地高速缓存被修改时,广播修改的数据,使得其它位置的数据拷贝得以及时更新
内存访问模型分类
SMP(Symmetric Multi-Processor)

优点
- 结构对称,采用单一操作系统
- 所有处理器通过高速总线或交叉开关与共享存储器相连,具有单一的地址空间
- 通过写/读共享变量完成通信,快捷且编程比较容易
缺点
- 存储器和I/O负载大,易称为系统瓶颈,限制了系统中处理器的数量
- 单点实效就会导致整个系统的崩溃
- 一次成型,扩展性差
PVP (Parallel Vector Processors)
这些系统含有为数不多,功能很强的定制向量处理器(单个处理器性能至少为1Gflop/s),它们通常不使用高速缓存,而是采用大量向量处理器和指令缓存
MPP与Cluster的区别
MPP
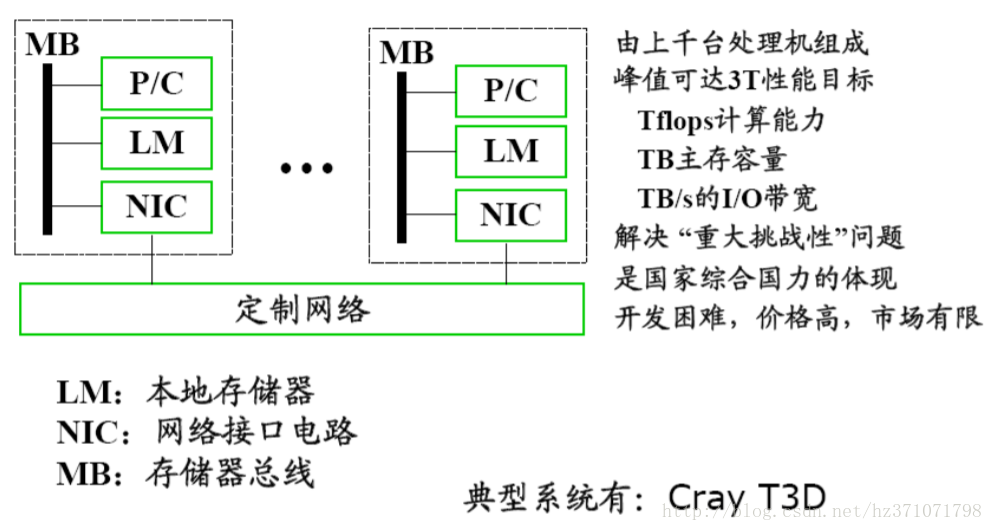
Cluster
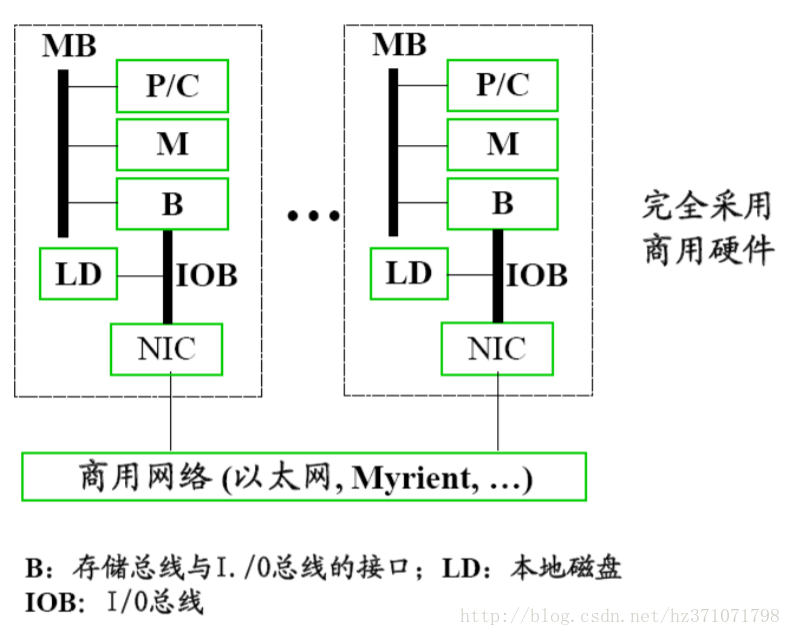
对比
- MPP使用定制网络,而Cluster使用价格便宜的商用网络
- MPP的网络接口是连接到节点的存储总线上(紧耦合),而Cluster的网络接口是连接到I/O总线上(松耦合)
- Cluster每一个节点都是完整的计算机
第三章
三种并行编程模型
特点

区别
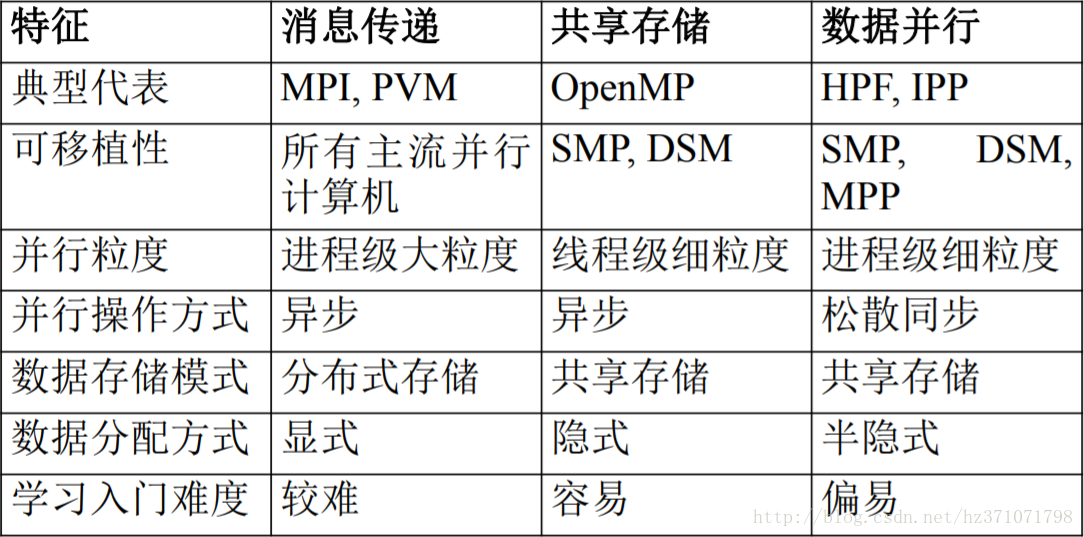
显式并行与隐式并行
显式并行
- 在源程序中由程序员使用专用语言构造、编译器命令或库函数对并行性加以显式说明
- 共享变量模型、消息传递模型、数据并行模型
隐式并行
- 程序员不显式地说明并行性,而是让编译器或运行支持系统自动加以开发
- 并行化编译器、运行时间并行化
并行程序设计模型
- 任务并行模式(任务分解或数据分解)
- 分治模式(任务分解或数据分解):如快排算法
- 几何分解(数据分解):将所要解决问题中使用的数据结构并行化,每个线程只负责一些数据块上的操作
- 流水线模式(数据流分解)
第四章
进程和线程
- 线程:是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中的一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。同一进程中的多条线程将共享该进程中的全部系统资源,如虚拟地址空间,文件描述符和信号处理等等,但同一进程中的多个线程有各自的调用栈(call stack),自己的寄存器上下文(register context),自己的线程本地存储(thread-local storage)。
- 进程:是一个可并发执行的具有独立功能的程序关于某个数据集的一次执行过程,也是操作系统进行资源分配和保护的基本单位
- 线程支持/实现方法:
在单核CPU机器上,操作系统以循环的方式为依次每个独立线程提供量子(quantum),得到quantum的线程开始执行;
可以通过操作系统层(如Win32 API)实现;
可以通过库或运行时环境(MFC,.net框架)实现;
可以通过专门的多线程库(pthread)实现。
互锁函数
- 以原子操作的方式修改一个值
- 相比其他同步(互斥)方式,速度极快
特点
- 许多现代计算机体系结构都会支持一些特殊指令,这些指令可以快速执行普通的原子操作,而不需要获取同步对象。Windows通过互锁函数利用这样的特性。
- 对x86家族的CPU来说,互锁函数会对总线发出一个硬件信号,防止另一个CPU访问同一内存地址
Spin Lock(自旋锁/循环锁)
非阻塞锁。由某个线程独占。采用循环锁时,等待线程并不静态地阻塞在同步点,而是必须“旋转”,不断尝试直到获得该锁。
应用场景
- 锁持有时间较短
- 避免在单CPU或单核计算机中使用循环锁
用户态同步和内核态同步
用户态同步
允许线程保留在用户方式下实现同步。如互锁函数,CRITICAL_SECTION
- 优点:速度快
- 局限:互锁函数只能在单值上运行;CRITICAL_SECTION只能对单个进程中的线程同步
内核态同步
使用内核对象进行同步
- 优点:适应性广泛
- 缺点:速度慢
可用于同步的内核对象
- Processes, Threads, Jobs, Files
- Events
- Semaphores, Mutexes
- File change notifications
- Waitable timers
- Console input
For thread synchronization, each of these kernel objects is said to be in a signaled or nonsignaled state.
操作
- Wait Functions(原子操作)
- Event Kernel Objects
- 信号量对象
- 互斥量对象
- 线程池
- 线程优先级
- 处理器亲和
线程局部存储(Thread Local Storage)
– 线程局部存储(thread-local storage,TLS)是一个很方便的存储线程局部数据的系统
– 可以使用TLS将数据与一个特定的线程相关联
– 利用TLS机制可以为进程中的所有线程关联若干个数据,各个线程通过TLS分配的全局索引来访问自己关联的数据
用法
- TlsAlloc函数:系统为每一个进程都维护一个长度为TLS_MINIMUM_AVAILABLE的位数组,TlsAlloc的返回值就是数组中值为FREE的一个成员的下标(索引),如果找不到一个值为FREE的成员,TlsAlloc返回TLS_OUT_OF_INDEXES,意味着失败
- TlsSetValue函数:该函数将lpTlsValue参数所确定的值放进线程的数组中,而放置位置的索引则是由dwTlsIndex确定的lpTlsValue的值关联到调用TlsSetValue的线程,如果调用成功则返回TRUE; 当一个线程调用TlsSetValue时,可以改变其自身的
数组,但是它不能为另外的线程设置TLS的值 - TlsGetValue函数
- TlsFree函数
第五章
exec和fork
- exec:系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,唯一留下的,就是进程号以及一些环境变量的信息;
- fork:启动一个新的进程,这个进程几乎是当前进程的一个拷贝:子进程和父进程使用相同的代码段;子进程复制父进程的堆栈段和数据段。这样,父进程的所有数据都可以留给子进程,但是,子进程一旦开始运行,虽然它继承了父进程的一切数据,但实际上数据却已经分开,相互之间不再有影响了,也就是说,它们之间不再共享任何数据了
Signal(信号量)


不可靠信号
在早期的UNIX中信号是不可靠的,不可靠在这里指的是:信号可能丢失,一个信号发生了,但进程却可能一直不知道这一点。
现在Linux在SIGRTMIN实时信号之前的都叫不可靠信号,这里的不可靠主要是不支持信号队列,就是当多个信号发生在进程中的时候(收到信号的速度超过进程处理的速度的时候),这些没来的及处理的信号就会被丢掉,仅仅留下一个信号。
可靠信号是多个信号发送到进程的时候(收到信号的速度超过进程处理信号的速度的时候),这些没来的及处理的信号就会排入进程的队列。等进程有机会来处理的时候,依次再处理,信号不丢失。
可重入函数
可以被中断的函数
不可重入函数
- 系统资源
- 全局变量
- 使用静态数据结构
- 调用malloc或者free
- 标准IO函数
- 例子:getpwname(),errno,reenter.c
共享内存
- 共享内存是内核为进程创建的一个特殊内存段,它可连接(attach)到自己的地址空间,也可以连接到其它进程的地址空间
- 最快的进程间通信方式
- 不提供任何同步功能















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









