






运用Python 数据分析工具分析学生成绩(D:\成绩表.xlsx,工作簿中有两门课程,见图1),表中含:学号、姓名、平时成绩、期末成绩、总评,请按“总评”进行分段统计,求平均值、均方差、成绩分段分布,单样本KS正态分布检验(置信度5%,双侧)。统计结果插入原文档,实现学生成绩的自动分析。
成绩分段:0~59为“不及格”,60~69为“及格,70~79为“中等”,80~89为“良好”,90~100为“优秀”。统计各段成绩人数和占比。
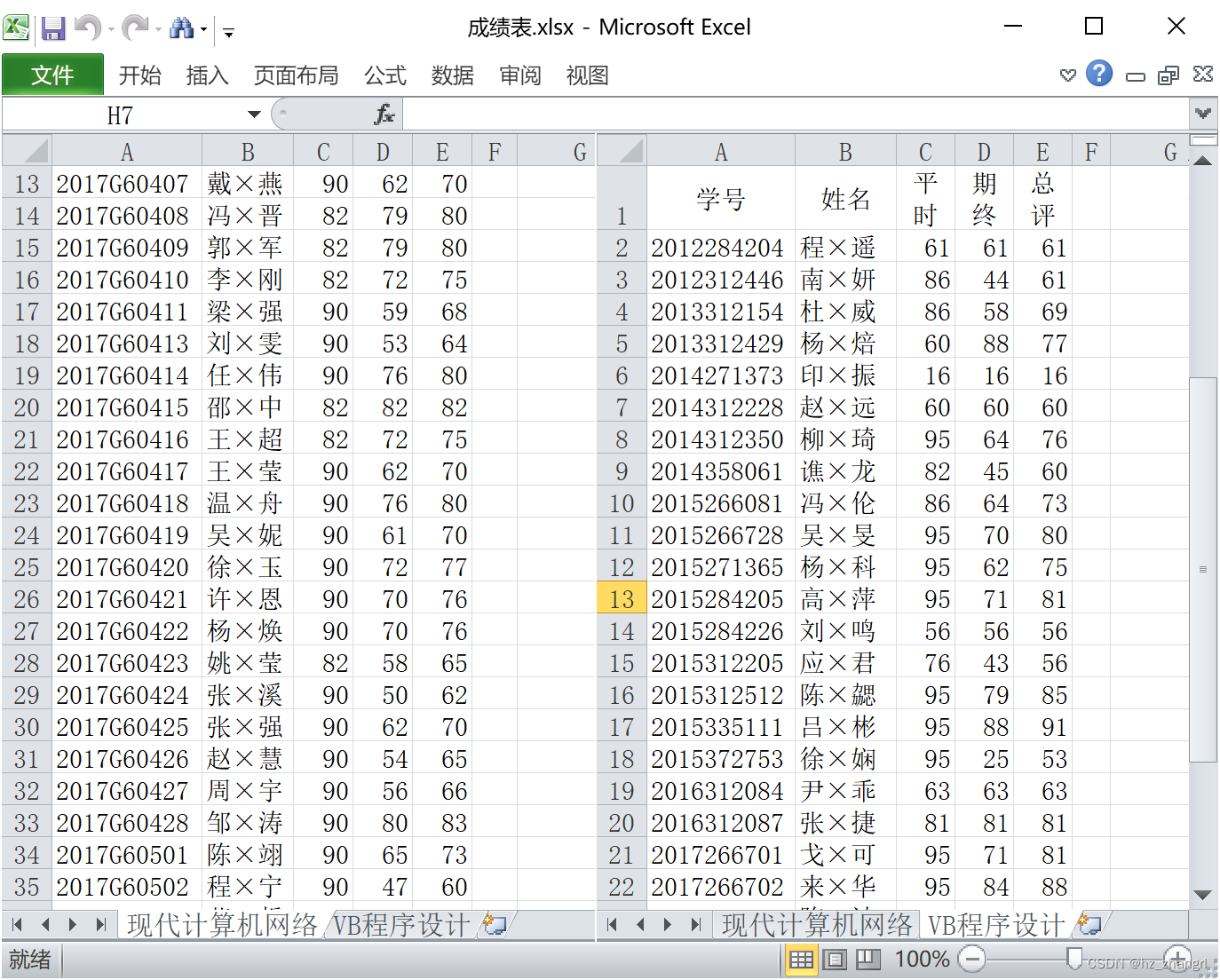
图1 D:\成绩表.xlsx结构,有《现代计算机网络》、《VB程序设计》两门课
一、处理Excel表和数据分析工具
要用Python对Excel表进行编辑要用到第三方库,常用的库有:
2010版本以下的Excel(*.xls):一般用xlrd读取,xlwt编辑,xlutils复制,三库联用。
2010版本及以上版本Excel(*.xlsx),可用openpyxl 读取及编辑。
PanDas、SciPy、NumPy等一般用于数据分析。
二、openpyxl模块的基本应用
1.安装
(1) 在Windows命令行提示下执行:
pip install openpyxl
(2) 在PyCharm中找到interpreter点击右上角的“+”,输入openpyxl,然后点击install package按钮即可。
2.openpyxl模块
openpyxl模块的三大组件:1)工作簿,2)工作表,3)单元格。
(1) 加载本地已存在的工作簿
exl = openpyxl.load_workbook(filename)
exl为workbook对象
(2) 获取工作表
exl_sht = exl[工作表名]
exl_sht为worksheet对象,从workbook对象exl中获取由工作表名指定的工作表。
(3) 获取单元格
escel = exl_sht.cell(row, column)
escel为cell对象,exl_sht为worksheet对象,row为行号,column为列号。
三、Python的NumPy、PanDas、SciPy
NumPy:N维数组容器,基础的数学计算模块,以矩阵为主,纯数学。
PanDas:表格容器,提供了名为Series的一维数据结构和名为DataFrame的二维数据结构,适合统计分析的表结构,可做数据分析。
SciPy:科学计算函数库,它基于NumPy,提供方法直接计算结构,封装了一些高阶抽象和物理模型。
四、PanDas简介
PanDas的名称来自于面板数据(panel data)和Python数据分析(data analysis)。PanDas 是一个开源的第三方Python库,从NumPy和Matplotlib的基础上构建而来,享有数据分析“三剑客之一”的盛名(NumPy、Matplotlib、PanDas)。PanDas已经成为Python数据分析的必备高级工具,它的目标是成为强大、灵活、可以支持任何编程语言的数据分析工具。
一般情况下,用下面语句导pandas模块:
import pandas as pd
将pandas简写成pd几乎成了一种不成文的规定。因此,只要读者看到pd就应该联想到这是pandas。
pandas中的两个主要数据结构:Series和DataFrame。
(1) Series
Series用于处理一维数据,是一维列数据。
(2) DataFrame
DataFrame 用于处理二维数据,每一列都是一个Series。
这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数典型用例。首先,来看一下 Series。
l Series
Series是一种类似于NumPy中一维数组的对象,它由一组任意类型的数据以及一组与之相关的数据标签(即索引)组成。举个最简单的例子:
import pandas as pd
print(pd.Series([1,3,5,7,9]))
上面的代码将打印出如图2所示的内容:

图2 Series结构
图2中,左边的是数据的索引,默认从 0 开始依次递增。右边是对应的数据,最后一行表明了数据类型。
可以用字典同时创建带有自定义数据索引的数据,pandas会自动把字典的键作为数据索引,字典的值作为相对应的数据。
import pandas as pd
print(pd.Series({'a':1,'b':3,'c':5,'d':7,'e':9}))
运行结果如3所示:

图3 Series结构自定义索引
访问Series中的数据的方式,和Python中访问列表和字典元素的方式类似,也是使用中括号加索引(键)的方式来获取数据。
l DataFrame
Series是一维数据,而DataFrame是二维数据。可以把DataFrame想象成一张二维表格,表格有行和列这两个维度,所以是二维数据。
DataFrame的每一列都是一个 Series。
创建DataFrame对象的语法格式:
df = pd.DataFrame(data, index, columns, dtype, copy)
其中:data为数据,支持列表,字典,numpy数组,Series对象等;index为行索引;columns为列索引;dtype为每一列数据的数据类型。
因为表格中有中文,中文占用的字符和英文、数字占用的字符宽度不同,因此需要调用pd.set_option()使表格对齐显示。如果你是使用Jupyter来运行代码的,Jupyter会自动渲染出一个表格,则无需这个设置。
构建DataFrame的办法有很多,最常用的一种是传入一个由等长列表组成的字典。即字典中每个值都是列表,且它们的长度必须相等。
这样就得到了一张表格,字典的键会作为表格的列名(列索引)。最左边的是行索引,如果没有指定,默认从0开始依次增加。当然,可以在构建 DataFrame 的时候指定index参数来自定义行索引。
例如:

短小的表格数据可直接写在函数中,比较大的表格数据先存放到变量data中,然后再将变量data放在函数中。可以通过index参数定义DataFrame行索引,用columns参数定义DataFrame列索引。上面代码的运行结果如图4所示(红色文字、箭头和矩形框是为帮助理解作者添加的):
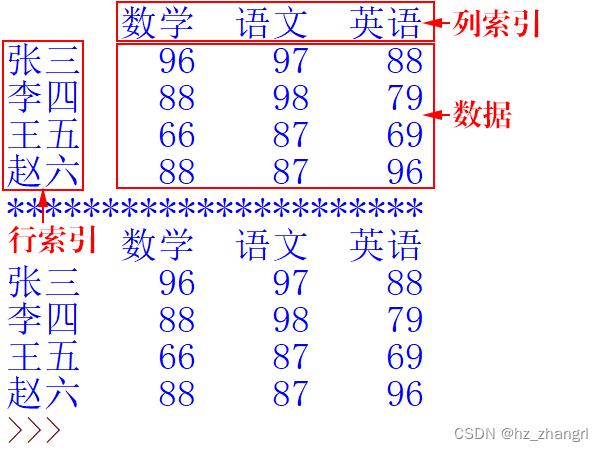
图4 DataFrame结构两种定义方式
其他操作详见程序中的注释,完整程序如下:

运行结果如图5、图6所示,实现了对成绩数据的自动分析。

图5 《现代计算机网络》成绩单中添加柱状图及分布信息效果(可对照图1)

图6 《VB程序设计》成绩单中添加柱状图及分布信息效果(可对照图1)















 1416
1416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









