






一:哈夫曼编码
当我们在传输或存储数据时,经常会遇到大量的文本或数据。而有些字符可能出现的频率比较高,有些则比较低。传统的ASCII编码或其他编码方式对每个字符都分配固定长度
字符 'A' : ASCII 编码为 01000001
字符 'B' : ASCII 编码为 01000010
字符 'C' : ASCII 编码为 01000011
字符 'D' : ASCII 编码为 01000100
在ASCII编码中,每个字符都用相同长度的8位编码,因此无法根据字符的频率来进行压缩。在英文中,各个字母在文本材料中出现的频率不同。在英文中,e的出现概率最高,而z的出现概率则最低。
若将每个字符都用同样位数的二进制数来表示的话会产生浪费。但如果将编码设计为长度不等的二进制编码,即让待传字符串中出现次数较多的字符采用尽可能短的编码,则转换的二进制字符串便可能减少。如下图所示:
字符 'A' : 编码为 0
字符 'B' : 编码为 00
字符 'C' : 编码为 1
字符 'D' : 编码为 01
如果要传送的信息是“ABACCDA”,它的编码是多少呢
答案:000011010
要设计长度不等的编码,则必须使任一字符的编码 都 不是 另一个字符的编码的前缀。这种编码叫做前缀编码。而哈夫曼编码就是一种前缀编码。它的特点是:
(1)出现频率高的字符使用较短的编码,而出现频率低的字符使用较长的编码。
(2)哈夫曼树是一棵前缀编码树,因此每个字符的编码不会是另一个字符编码的前缀,使用哈夫曼编码可以达到数据压缩的目的。
二:构建哈夫曼树:
哈夫曼树的构建可以使用“贪心算法”来实现。假设有如下8个字符及对应的权值:
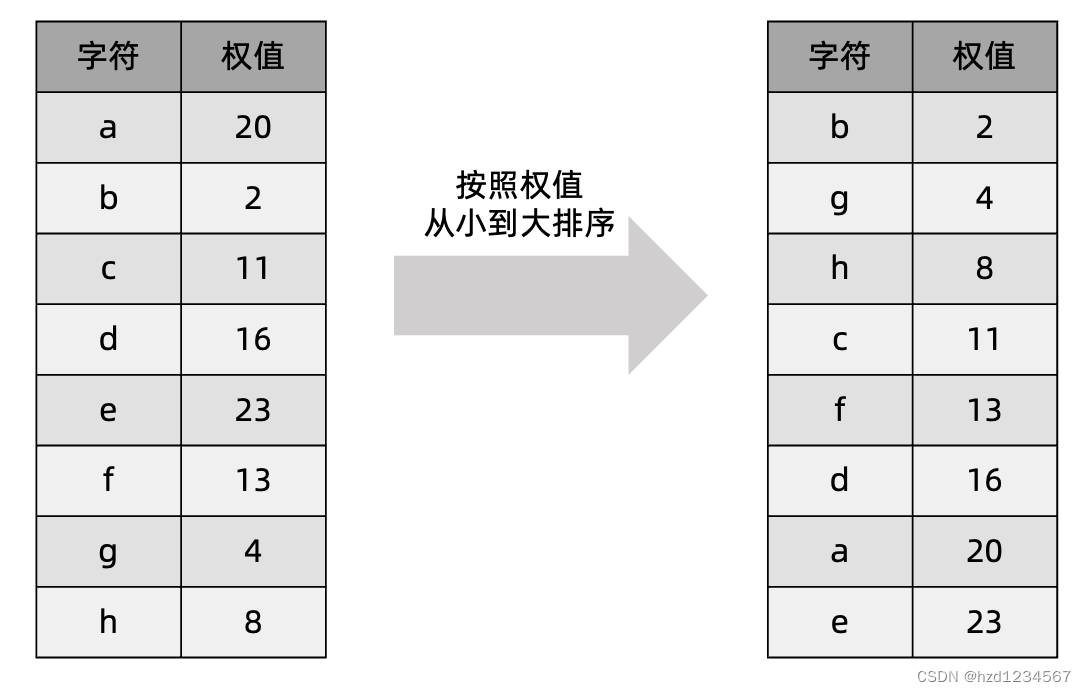
我们可以按照以下步骤构造哈夫曼树:

下面是“哈夫曼树”的建树过程:

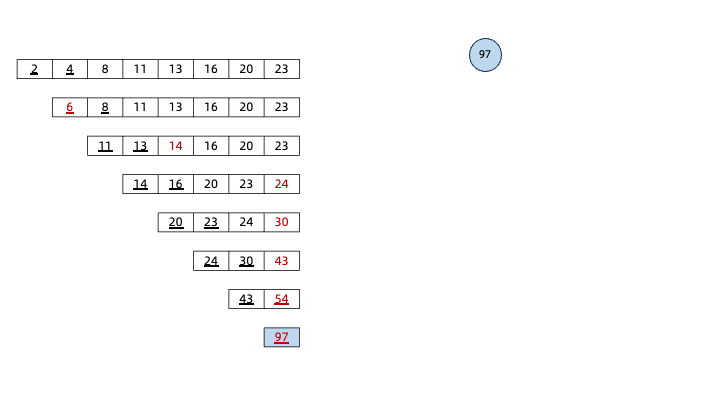
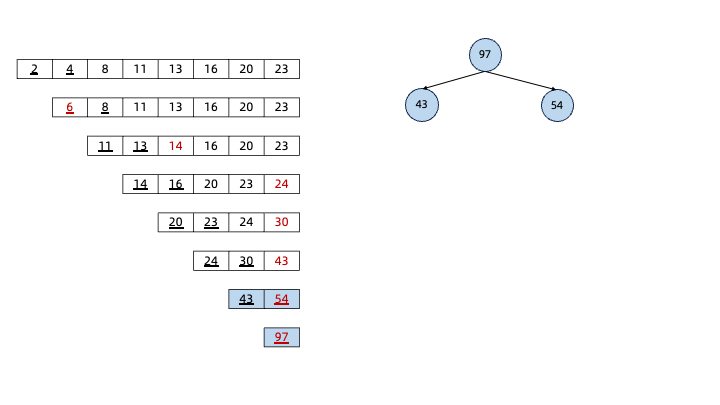



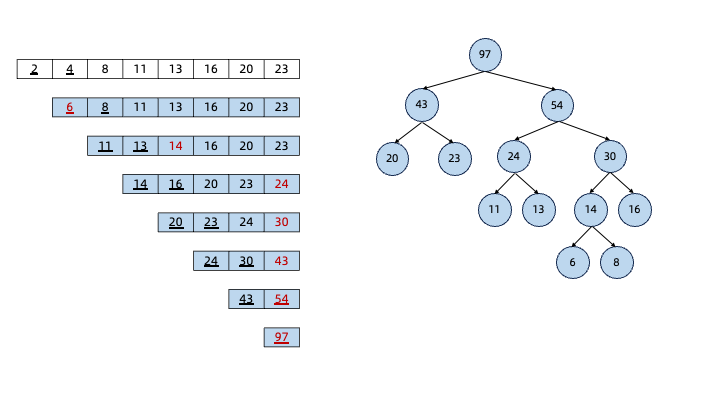
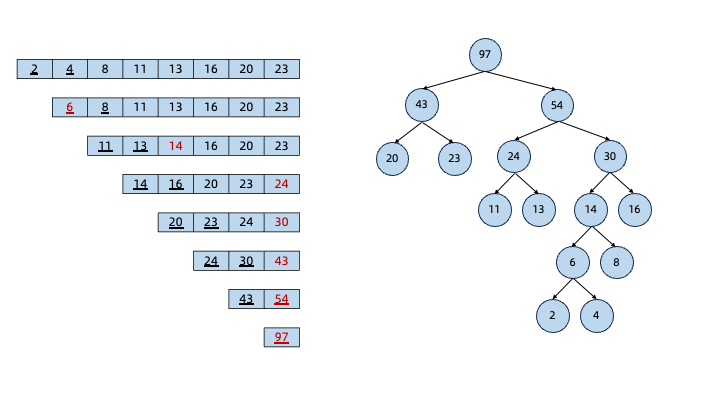
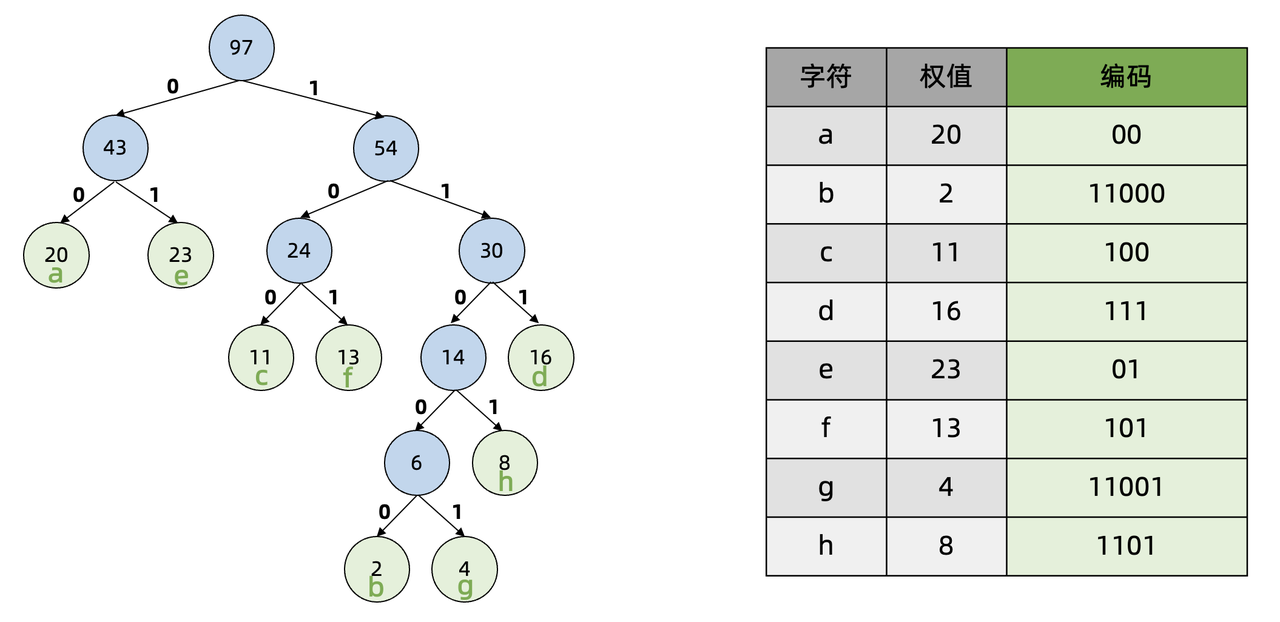
构建完哈夫曼树后,从哈夫曼树的根节点开始,遍历左子树的路径为0,遍历右子树的路径为1:

则每个叶子节点对应的字符编码为:从根节点到该叶子节点经过的路径上的0和1序列。















 3150
3150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









