






1.htmlunit
动态页面问题:最开始遇到的是获取不到完整的页面代码,然后就知道用htmlunit,他可以支持在你获取页面代码前先执行js,但我试过了编程很不友好,就是没有效果
WebClient webClient= newWebClient(BrowserVersion.CHROME);//设置浏览器
LogFactory.getFactory().setAttribute("org.apache.commons.logging.Log","org.apache.commons.logging.impl.NoOpLog");
java.util.logging.Logger.getLogger("com.gargoylesoftware.htmlunit").setLevel(Level.OFF);
java.util.logging.Logger.getLogger("org.apache.commons.httpclient").setLevel(Level.OFF);//这三行是用来去掉警告
webClient.getOptions().setUseInsecureSSL(true);//支持https
webClient.getOptions().setCssEnabled(false);//设置css是否生效
webClient.getOptions().setJavaScriptEnabled(true);//设置js是否生效
webClient.getOptions().setRedirectEnabled(true);
webClient.getOptions().setThrowExceptionOnScriptError(false);//当JS执行出错的时候是否抛出异常, 这里选择不需要
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);//当HTTP的状态非200时是否抛出异常, 这里选择不需要
webClient.setAjaxController(newNicelyResynchronizingAjaxController());//设置ajax请求
webClient.getOptions().setTimeout(10000);//设置连接超时时间 ,这里是10S。如果为0,则无限期等待
HtmlPagehtmlPage=webClient.getPage(httpUrl);//访问路径设置
webClient.setJavaScriptTimeout(10000);//设置js运行超时时间
webClient.waitForBackgroundJavaScript(10000);//设置页面等待js响应时间,设置一个运行JavaScript的时间,异步JS执行需要耗时,所以这里线程要阻塞30秒,等待异步JS执行结束
content=htmlPage.asXml();
webClient.close();2.selenium简单版 (ChormeDriver,FireFoxDriver)
selenium下载: selenium Mirror
滚动加载页面问题:我们很常见的一些网站如百度新闻、淘宝页面内容很多,如果一次性加载会很费时间,所以网站会做成当你滚动条下滑时动态加载,当然我用htmlunit试过了不管用,所以我找到了selenium,每次让滚动条滚动底部,等待2s后新的内容加载出来,继续滚动到底部,知道页面全部加载完成。
火狐浏览器
System.setProperty("webdriver.firefox.bin", "D:/Firefox/firefox.exe");//selenium下载的jar包中自己继承了火狐驱动所以可以直接用
WebDriver driver = new FirefoxDriver();谷歌浏览器
谷歌驱动下载:http://chromedriver.storage.googleapis.com/index.html
System.setProperty("webdriver.chrome.driver", "chromedriver.exe");//需要自己去下载谷歌驱动,注意你的驱动版本、selenium版本、浏览器版本最好都是最新,不然会出各种不知道为什么的错误
ChromeOptions chromeOptions=new ChromeOptions();
chromeOptions.setBinary("Chrome/Application/chrome.exe");//你的谷歌浏览器的位置
WebDriver driver = new ChromeDriver(chromeOptions);滚动条下滑
WebElement body=driver.findElement(By.tagName("body"));
int height_old=body.getSize().height;
while(true){
((JavascriptExecutor)driver).executeScript("window.scrollTo(0,document.body.scrollHeight)");
Thread.sleep(2000);
int height_new=driver.findElement(By.tagName("body")).getSize().height;
System.out.println(height_new+"||"+height_old);
if(height_new==height_old){
break;
}
height_old=height_new;
}3.HtmlUnitDriver,PhantomJsDriver,ChormeDriver无头模式
不显示浏览器窗口问题:selenium是用来做测试工具用的,换句话说在你运行时会有浏览器界面在屏幕上自动操作,但最终为了节省时间我们希望他不显示界面,于是我发现selenium里有一些无界面的驱动如HtmlUnitDriver,PhantomJsDriver
HtmlUnitDriver driver=new HtmlUnitDriver(BrowserVersion.CHROME);
driver.setJavascriptEnabled(true);String browserPath = "D:/jarbao/phantomjs/phantomjs-1.9.8-windows/phantomjs.exe";//phantomjs需要你取下载
System.setProperty("phantomjs.binary.path", browserPath);
WebDriver driver = new PhantomJSDriver();可是当我使用他们后我之前写的滚动条下滑的代码不起作用了,几番寻找后我发现了谷歌的无头模式:
System.setProperty("webdriver.chrome.driver", "chromedriver.exe");
ChromeOptions chromeOptions=new ChromeOptions();
chromeOptions.setBinary("Chrome/Application/chrome.exe");
chromeOptions.addArguments("--headless");//关键的这句话
WebDriver driver = new ChromeDriver(chromeOptions);火狐无头模式:
File pathToFirefoxBinary =new File("D:/Firefox/firefox.exe");
FirefoxBinary firefoxBinary = new FirefoxBinary(pathToFirefoxBinary);
firefoxBinary.addCommandLineOptions("--headless");
System.setProperty("webdriver.gecko.driver", "browser/FireFox/geckodriver.exe");
FirefoxOptions firefoxOptions = new FirefoxOptions();
firefoxOptions.setBinary(firefoxBinary);
WebDriver driver = new FirefoxDriver(firefoxOptions);4.模拟登陆
(1)无法根据id获取元素问题(iframe切换):
当获取input元素时提示 :
no such element: Unable to locate element: {"method":"id","selector":"inputId"}
这是因为此内容时放在iframe里面的故查不到,需要先进入到iframe里面
driver.switchTo().frame("iframe名称");
driver.findElement(By.id("inputId")).click();
(2)页面跳转:
String currentWindow=driver.getWindowHandle();//得到当前窗口
Set<String> handler=driver.getWindowHandles();//获取所有窗口
Iterator<String> lt=handler.iterator();
while(lt.hasNext()){
if(currentWindow==lt.next()){
continue;
}
driver.switchTo().window(lt.next());//跳转到新窗口
}(3) 识别验证码问题
方法一:最开始我使用了Tesseract取做二维码识别(只能识别最简单的二维码)
下载:http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe
配置环境变量:
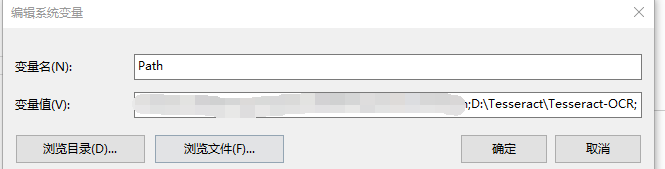
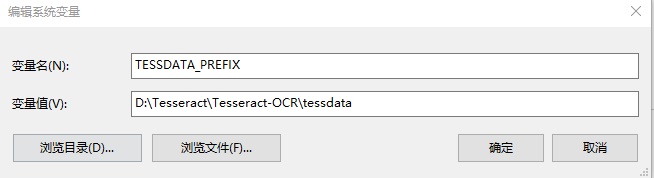
测试是否配置成功:

之后你就可以在cmd任意目录下执行tesseract指令了,然后在java中去调用它,但精度很不好:(有的文章说精度不准可以通过一个工具jTessBoxEditor学习机制,去创建自己的识别库,我试了很难很机械!)
Runtime.getRuntime().exec("cmd /C tesseract D://yzm.png D://tmp")//去D盘下识别yzm.png并把结果保存到D盘下tmp.txt文件中
StringBuffer result=new StringBuffer();
BufferedReader br=new BufferedReader(new InputStreamReader(new FileInputStream(new File("D://tmp.txt")),"utf-8"));
String line="";
while((line=br.readLine())!=null){
result.append(line);
}方法二:然后准备自己做验证,网上查了很多最后得到一个理论:








------与标准库比较------>RTN6
(以下理论均来自于互联网)
灰度化有俩种方法
1 :取平均数作为灰度值
灰度化后的R=(处理前的R+ 处理前的G +处理前的B)/ 3
灰度化后的G=(处理前的R + 处理前的G +处理前的B)/ 3
灰度化后的B=(处理前的R + 处理前的G +处理前的B)/ 3
2 : 按一定的比例来作为灰度值(经对比推荐第二种)
灰度化后的R= 处理前的R * 0.3+ 处理前的G *0.59 +处理前的B * 0.11
灰度化后的G= 处理前的R * 0.3+ 处理前的G *0.59 +处理前的B * 0.11
灰度化后的B= 处理前的R * 0.3+ 处理前的G *0.59 +处理前的B * 0.11
灰度化原理(彩色有255*255*255中,使用灰度话公式可以让RGB三种颜色相同从而范围减少为255种,方便后续的操作)
二值化方法:
1:取阀值为127(相当于0~255的中数,(0+255)/2=127),让灰度值小于等于127的变为0(黑色),灰度值大于127的变为255(白色),这样做的好处是计算量小速度快,但是缺点也是很明显的,因为这个阀值在不同的图片中均为127,但是不同的图片,他们的颜色分布差别很大,所以用127做阀值,白菜萝卜一刀切,效果肯定是不好的。
2:计算像素点矩阵中的所有像素点的灰度值的平均值avg,(像素点1灰度值+...+像素点n灰度值)/ n = 像素点平均值avg,然后让每一个像素点与avg一 一比较,小于等于avg的像素点就为0(黑色),大于avg的 像 素点为255(白色),这样做比方法1好一些。
去杂点方法:
8邻域算法降噪法(简单的说就是:除了最外围的一圈像素点,以每个像素点为中心,如果其外围临近8个像素点中为黑的个数>阀值1(如7个)并且此点为白色我就把它换成黑色;同理如果是其外围临近8个像素点中为黑的个数<阀值2(如3个),并且此点为黑色我就把它换成白色)
public BufferedImage removeWastePoint(int rNum,int fNum,BufferedImage image) throws Exception{ //rNum,fNum为阀值
int width = image.getWidth();
int height = image.getHeight();
for(int x=0;x<width;x++){
image.setRGB(x, 0, Color.WHITE.getRGB());
image.setRGB(x, height-1, Color.WHITE.getRGB());
}
for(int y=0;y<height;y++){
image.setRGB(0, y, Color.WHITE.getRGB());
image.setRGB(width-1, y, Color.WHITE.getRGB());
}
for (int x = 1; x < width-1; ++x) {
for (int y = 1; y < height-1; ++y) {
if(getColorBright(image.getRGB(x, y))==0){
count=0;
for(int a=x-1;a<=x+1;a++){
for(int b=y-1;b<=y+1;b++){
if(getColor(image.getRGB(a, b))==0){
count++;
}
}
}
if(count<rNum){
image.setRGB(x, y, Color.WHITE.getRGB());
}
}else{
count=0;
for(int a=x-1;a<=x+1;a++){
for(int b=y-1;b<=y+1;b++){
if(getColor(image.getRGB(a, b))==0){
count++;
}
}
}
if(count>=fNum){
image.setRGB(x, y, Color.BLACK.getRGB());
}
}
}
}
return image;
}public static int getColor(int colorInt) {
Color color = new Color(colorInt);
return color.getRed() + color.getGreen() + color.getBlue();
} 字符串拆分:把经过处理的二维码图片截成单个字符的图片
与标准库做比较:标准库就是已经准备好的0-9 A-Z的单个数字字符的图片集,比如(用ps做的花了半天功夫,真的累)
















 2111
2111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









