







写在前边:查看编码前的原始数据,可以用inverse_transform()方法
sklearn.preprocessing.OneHotEncoder
- 方法
| fit(self, X[, y]) | Fit OneHotEncoder to X. |
|---|---|
| fit_transform(self, X[, y]) | Fit OneHotEncoder to X, then transform X. |
| get_feature_names(self[, input_features]) | Return feature names for output features. |
| get_params(self[, deep]) | Get parameters for this estimator. |
| inverse_transform(self, X) | Convert the back data to the original representation. |
| set_params(self, **params) | Set the parameters of this estimator. |
| transform(self, X) | Transform X using one-hot encoding. |
- 例子
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder(handle_unknown='ignore')
X = [['Male', 1], ['Female', 3], ['Female', 2]]
enc.fit(X)
enc.categories_
enc.transform([['Female', 1], ['Male', 4]]).toarray()
array([[1., 0., 1., 0., 0.],
[0., 1., 0., 0., 0.]])
#第一位对性别进行编码,后四位对1或4进行编码
enc.inverse_transform([[0, 1, 1, 0, 0], [0, 0, 0, 1, 0]])
array([['Male', 1],
[None, 2]], dtype=object)
enc.get_feature_names()
drop_enc = OneHotEncoder(drop='first').fit(X)
drop_enc.categories_
drop_enc.transform([['Female', 1], ['Male', 2]]).toarray()
array([[0., 0., 0.],
[1., 1., 0.]])
作者:JeremyL
链接:https://www.jianshu.com/p/cf7f4efa1382
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
==============================================
踩坑系列-字符编码OneHotEncoder
OneHotEncoder
今天想起来,之前应用OneHotEncoder存在的问题,这里和大家分享一下。
OneHotEncoder又被称为独热编码,什么意思呢,就是
1、每一列特征需要构建的状态寄存器的位数等于该列特征独立取值的个数;
2、使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。
到底在说什么呢?请看下面的代码演示就明白了(以下代码在jupyter notebook里执行)
import numpy as np
import pandas as pd
from sklearn import preprocessing
enc = preprocessing.OneHotEncoder()
X=np.array([[0, 0, 3], [1, 1, 0], [0, 2, 1], [1, 0, 2]])
print(X)
enc.fit_transform(X).toarray()
#第一列有两个状态:0、1,需要2位状态寄存器来进行编码,[1,0]表示0,[0,1]表示1
#第二列有三个状态:0、1、2,需要3位状态寄存器来进行编码,[1,0,0]表示0,[0,1,0]表示1,[0,0,1]表示2
#第三列有四个状态:0、1、2、3,需要4位状态寄存器来进行编码,[1,0,0,0]表示0,[0,1,0,0]表示1,[0,0,1,0]表示2,[0,0,0,1]表示3

如果这时候来一个数据:
大家对着编码一下也可以得出这个结果;
但是如果来个(4是训练时没出现的数据):

会报错,因为4在训练时不曾出现,现在也不知道怎么编码它
解决办法:
enc = preprocessing.OneHotEncoder( handle_unknown='ignore')
#默认的是 handle_unknown='error',即不认识的数据报错,改成ignore代表忽略
enc.fit_transform(X)
enc.transform([[0, 1, 4]]).toarray()

可以看到,这时候4,被编码成[0,0,0,0],这样虽然不会报错,但是会造成一定的信息损失,因此,如果需要构建模型,
OneHotEncoder编码慎用。
之前踩坑场景:GBDT+LR复合模型,对数据落在GBDT中每颗树的叶子结点下标进行独热编码,再放入LR中构建模型;
测试数据中,也是存在编码时没见过的数值,出现报错。
pandas.get_dummies构造哑变量
这个方法其实和OneHotEncoder差不多,但是不能训练数据,因此无法入模使用,只能用于数据分析。
pandas.get_dummies(data, prefix=None, prefixsep=’’, dummy_na=False, columns=None, sparse=False, drop_first=False)

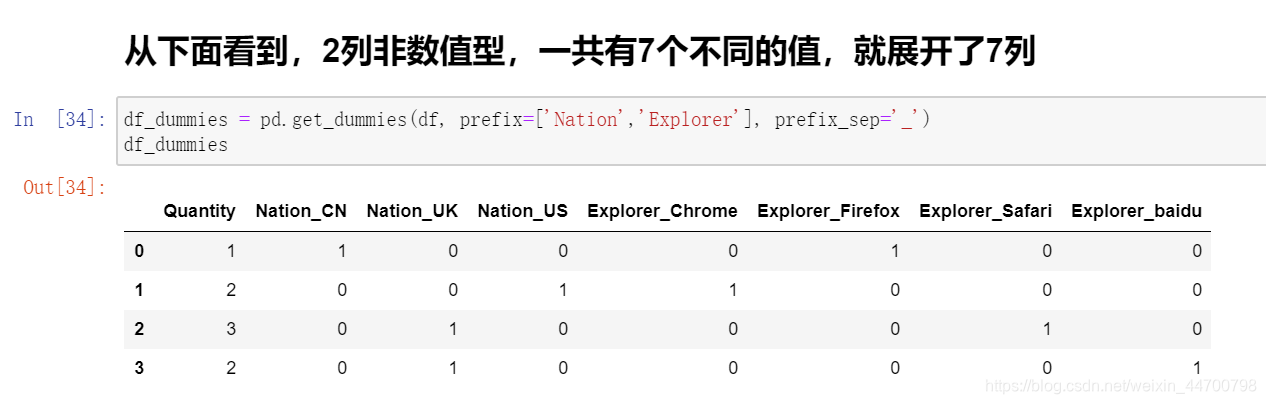
注意:Quantity列为数值型,并没有编码,编码的都是字符串型。















 440
440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









