







概率论相关总结
1. 概率分布与随机变量
1.1 机器学习为什么要使⽤概率
- 事件的概率是衡量该事件发⽣的可能性的量度。虽然在⼀次随机试验中某个事件的发⽣是带有偶然性的,但那些可在相同条件下⼤量重复的随机试验却往往呈现出明显的数量规律。机器学习除了处理不确定量,也需处理随机量。不确定性和随机性可能来⾃多个⽅⾯,使⽤概率论来量化不确定性。
- 概率论在机器学习中扮演着⼀个核⼼⾓⾊,因为机器学习算法的设计通常依赖于对数据的概率假设。
例如:在机器学习中,朴素贝叶斯假设就是条件独⽴的⼀个例⼦。该学习算法对内容做出假设,⽤来分辨电⼦邮件是否为垃圾邮件。假设⽆论邮件是否为垃圾邮件,单词x出现在邮件中的概率条件独⽴于单词y。最终的结果是,这个简单假设对结果的影响并不大,且无论如何都可以让我们快速辨别垃圾邮件。
1.2 变量与随机变量的区别
随机变量
- 表⽰随机现象(在⼀定条件下,并不总是出现相同结果的现象称为随机现象)中各种结果的实值函数(⼀切可能的样本点)。例如某⼀时间内公共汽⻋站等⻋乘客⼈数,电话交换台在⼀定时间内收到的呼叫次数等,都是随机变量的实例。
随机变量与模糊变量的不确定性的本质差别在于,后者的测定结果仍具有不确定性,即模糊性。
变量与随机变量的区别
- 当变量的取值的概率不是1时,变量就变成了随机变量;当随机变量取值的概率为1时,随机变量就变
成了变量。
例如:当x=100的概率为1时就是变量,当x为100的概率为0.5,x为50的概率为0.5就是随机变量。
1.3 随机变量与概率分布的联系
- 一个随机变量仅仅表示一个可能取得的状态,还必须给定与子相伴的概率分布来制定每个状态的可能性。⽤来描述随机变量或⼀簇随机变量的每⼀个可能的状态的可能性⼤⼩的⽅法,就是 概率
分布(probability distribution) - 随机变量可以分为离散型随机变量和连续型随机变量。相应的描述其概率分布的函数是:
- 概率质量函数(Probability Mass Function, PMF):描述离散型随机变量的概率分布,通常⽤⼤写字⺟
P表⽰。 - 概率密度函数(Probability Density Function, PDF):描述连续型随机变量的概率分布,通常⽤⼩写字
⺟p 表⽰。
1.4 离散型随机变量和概率质量函数
- PMF 将随机变量能够取得的每个状态映射到随机变量取得该状态的概率。

- PMF 可以同时作⽤于多个随机变量,即联合概率分布(joint probability distribution),P(X =
x, Y = y) 表示X = x Y = y 同时发生的概率,也可以简写成P(x, y)。 - 如果一个函数P 是随机变量 的 PMF, 那么它必须满⾜如下三个条件:
- P的定义域必须是的所有可能状态的集合
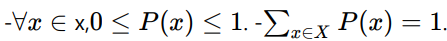
我们把这⼀条性质称之为 归⼀化(normalized)
1.5 连续型随机变量与概率密度函数
- 如果⼀个函数 是x的PDF,那么它必须满⾜如下⼏个条件:

简而言之:如果我们针对的时连续型随机变量,我们可以通过积分求得在某一区间内的变量的概率。
1.6 简单理解条件概率
条件概率公式如下:
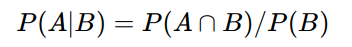
文氏图如下:

1.7联合概率与边缘概率的区别与连续:
区别
- 联合概率:联合概率指类似于P(X=a,Y=b) 这样,包含多个条件,且所有条件同时成⽴的
概率。联合概率是指在多元的概率分布中多个随机变量分别满⾜各⾃条件的概率。 - 边缘概率:边缘概率是某个事件发⽣的概率,⽽与其它事件⽆关。边缘概率指类似于P(
X=a),P(Y=b), 这样,仅与单个随机变量有关的概率。
联系
- 联合分布可求边缘分布,但若只知道边缘分布,⽆法求得联合分布。
1.8 条件概率链式法则
- 乘法公式,设 A,B 是两个事件,并且P(A)>0 , 则有:

- 任何多维随机变量联合概率分布,都可以分解成只有⼀个变量的条件概率相乘形式。
1.9 独立性和条件独立性
独立性
- 定义:两个随机变量x,y,概率分布表示成两个因子的乘积形式,一个因子只包含x,一个因子只包含y,两个随机变量相互独立。
注:
1、条件有时候会为不独立的事件带来独立,有时候也可以为独立的事件带来不独立。
2、事件独⽴时,联合概率等于概率的乘积。
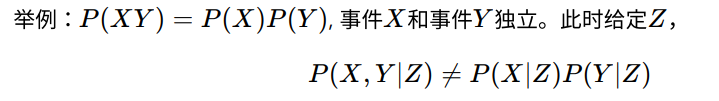
这个例子说明条件的存在,给两个独立的事件带来了不独立。
条件独立性

也就是说x与y的独立是有条件的(因为Z的存在)。这个就叫做条件独立性。
2. 常见的概率分布
2.1 Bernoulli(伯努利)分布
-
简介:伯努利试验是单次随机试验,只有"成功(值为1)"或"失败(值为0)"这两种结果 ,是由瑞士科学家雅各布·伯努利(1654 - 1705)提出来的。其概率分布称为伯努利分布(Bernoulli distribution),也称为两点分布或者0-1分布,是最简单的离散型概率分布。
-
主要性质有:
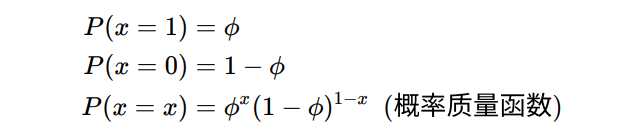
期望和方差为:
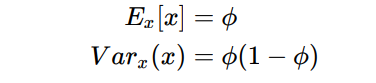
伯努利分布适合对离散型随机变量建模. -
二项分布定义:
假设某个试验是伯努利试验,其成功概率用p表示,那么失败的概率为q=1-p。进行n次这样的试验,成功了x次,则失败次数为n-x,发生这种情况的概率可用下面公式来计算:
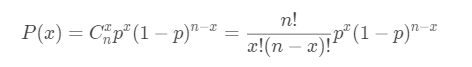
我们称上面的公式为二项分布(Binomial distribution)的概率质量函数, 其中:
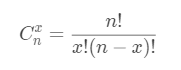
从二项分布公式可知,概率分布由试验次数n和"成功"概率p决定,因此二项分布的概率质量函数可以简写为X~B(n, p)。
2.2 高斯分布
- ⾼斯也叫正态分布(Normal Distribution), 概率度函数如下:
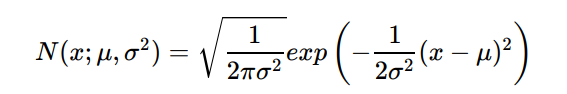
纠错:δ是标准差

何时采用正态分布?
缺乏实数上分布的先验知识, 不知选择何种形式时, 默认选择正态分布总是不会错的.
- 中⼼极限定理告诉我们, 很多独⽴随机变量均近似服从正态分布, 现实中很多复杂系统都可
以被建模成正态分布的噪声, 即使该系统可以被结构化分解. - 正态分布是具有相同⽅差的所有概率分布中, 不确定性最⼤的分布, 换句话说, 正态分布是对
模型加⼊先验知识最少的分布.
2.4 指数分布
- 在概率理论和统计学中,指数分布(也称为负指数分布)是描述泊松过程中的事件之间的时间的概率分布,即事件以恒定平均速率连续且独立地发生的过程。 这是伽马分布的一个特殊情况。 它是几何分布的连续模拟,它具有无记忆的关键性质。 除了用于分析泊松过程外,还可以在其他各种环境中找到。
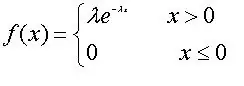
其中λ > 0是分布的一个参数,常被称为率参数(rate parameter)。即每单位时间内发生某事件的次数。指数分布的区间是[0,∞)。 如果一个随机变量X呈指数分布,则可以写作:X~ E(λ)。
- 深度学习中, 指数分布⽤来描述在 点处取得边界点的分布, 指数分布定义如下:
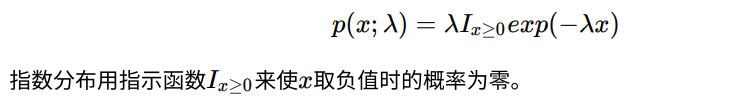















 5515
5515











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









