







3D-R2N2
ECCV 2016《3D-R2N2: A Unified Approach for Single and Multi-view 3D Object Reconstruction》
Choy, Christopher B and Xu, Danfei and Gwak, JunYoung and Chen, Kevin and Savarese, Silvio
论文链接:https://arxiv.org/abs/1604.00449
个人理解,如有错误见谅
Introduction
之前3D重建的SOTA方法存在一系列的限制:
-
观察物体的视角要密集,也就是说相机的位置变化相对比较小。(objects must be observed from a dense number of views; or equivalently, views must have a relatively small baseline)
-
物体的表面是Lambertian的(即理想散射、完全漫反射)并且表面富有不均匀纹理。(objects’ appearances (or their reflectance functions) are expected to be Lambertian (i.e. non-reflective) and the albedos are supposed be non-uniform (i.e., rich of non-homogeneous textures)
此论文受到LSTM和CNN成功应用的启示,提出了一种新的结构:3D-R2N2,此网络以一张或多张图片作为输入,输出重建物体的3D occupancy grid.

上图中左图为希望重建的物体的图片,可以看出同一物体的不同视点的位置差异还是较大的,同时也可以看出这些物体的纹理都不是很强,正好对应了之前方法的限制。
右图是3D-R2N2的overview,在这个例子中,网络将包含3张图片的图片序列(不同viewpoint)作为输入,然后生成体素化的3D重建,从图中可以看出,随着网络接受的不同视角图片数量增加,生成的模型也在不断地精细化。
另外一点是3D-R2N2在训练和测试过程不需要任何分割、视点标签、相机校准等,仅需要bounding box*(Our approach requires minimal supervision in training and testing (just bounding boxes, but no segmentation, keypoints, viewpoint labels, camera calibration, or class labels are needed))*
论文使用的数据集:PASCAL 3D、ShapeNet 、Online Products、MVS CAD Models
(这篇论文网络结构的思路是:利用LSTM(RNN)可接受任意长度输入序列的性质来统一单视图或者多视图输入,同时结合CNN在单视图3D重建的成功应用。同时LSTM这样的网络可以有效处理物体遮挡的情况,因为网络仅更新对应于物体可见部分的单元*(a recurrence module that allows the network to retain what it has seen and to update the memory when it sees a new image)*,如果后续视图显示先前被遮挡的部分,且这部分与网络预测不匹配,则网络将更新先前被遮挡的部分的 LSTM 状态,但保留其他部分的状态)
3D Recurrent Reconstruction Neural Network
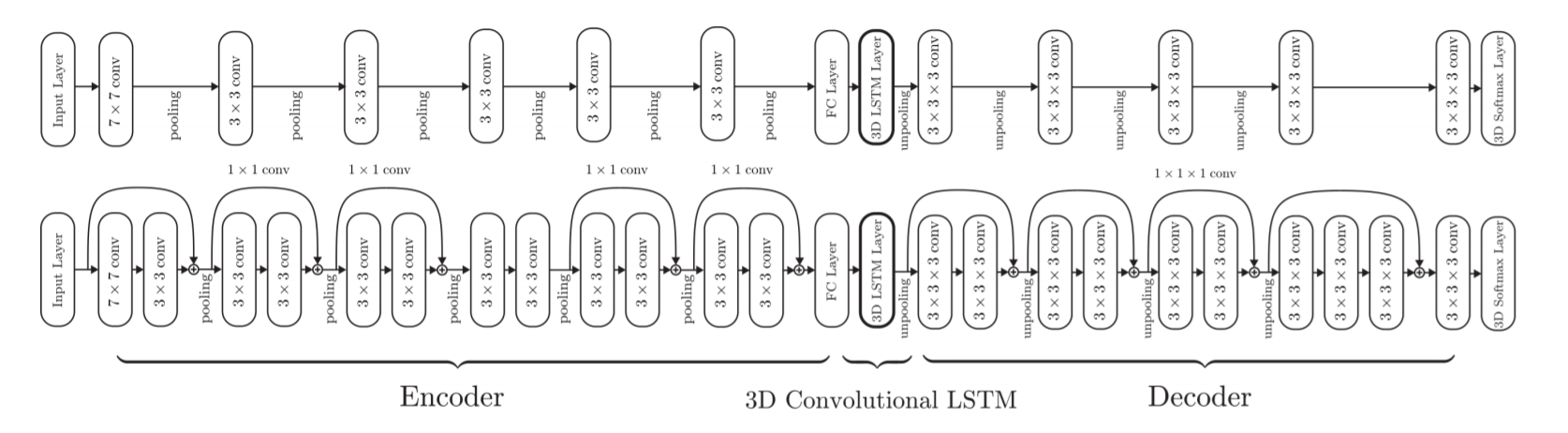
网络的结构如图所示分为三部分:2D-CNN、3D-LSTM、3D-DCNN
其中2D-CNN将127 ∗ \ast ∗ 127的RGB图片encode成低维(1024)的特征向量,输入到3D-LSTM当中。然后3D-LSTM输出4 ∗ \ast ∗ 4 ∗ \ast ∗ 4的voxels(4D-tensors), 其中每个位置上是排列成4 ∗ \ast ∗ 4 ∗ \ast ∗ 4的LSTM unit取hidden state。之后将其输入到3D-DCNN当中,得到32 ∗ \ast ∗ 32 ∗ \ast ∗ 32的3D occupancy grid
-
Encoder:2D-CNN
论文作者设计了两种不同的2D-CNN encoder,如上图所示,上边的是一般的前馈CNN,包含标准的卷积层、池化层,在最后的全连接层之前有leaky relu units.
下边的是使用残差结构的CNN,实验表明残差结构的网络效果更好。
-
Recurrence: 3D Convolutional LSTM
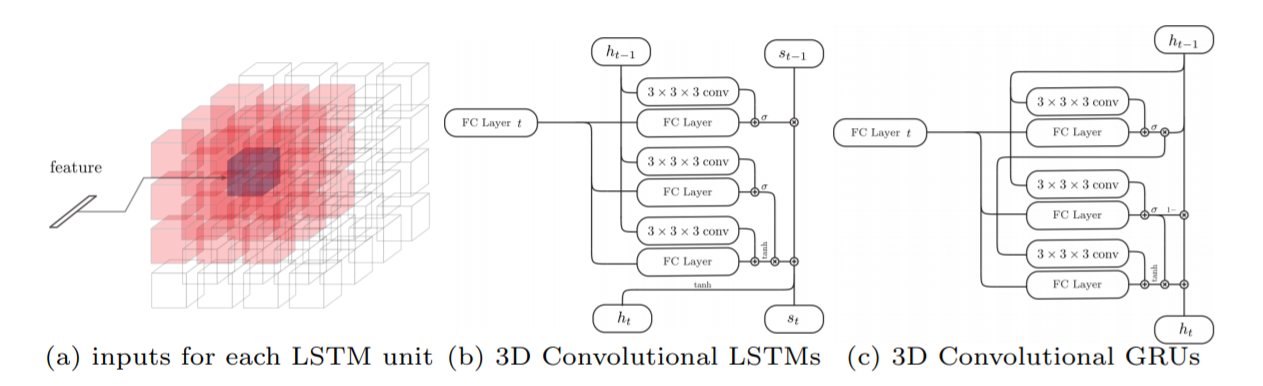
在实现过程中,64个LSTM units按照4 ∗ \ast ∗ 4 ∗ \ast ∗ 4的方式排列,经过下图所示的计算之后,取每个unit的 N h N_h Nh维的hidden state作为输出。也就是之前所说的4 ∗ \ast ∗ 4 ∗ \ast ∗ 4的voxels(4D-tensors)
计算过程的符号含义如下:
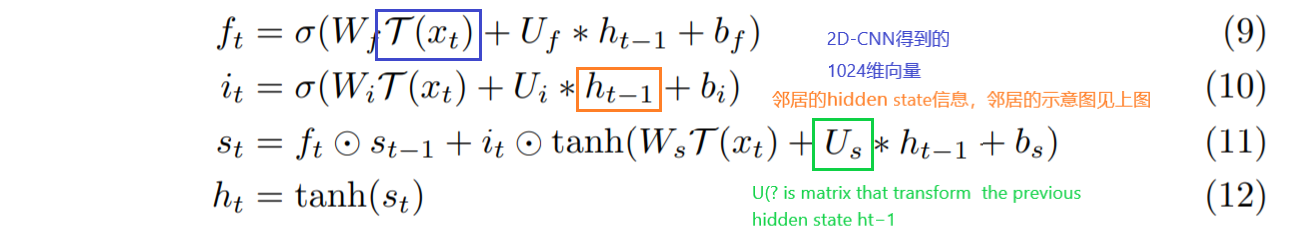
上述等式左边的符号含义分别为forget gate、input gate、memory cell、hidden state
与标准的LSTM不同的是,仅在最后的时候使用output gate,减少了参数数量(LSTM理解的不是很深入,留个坑)
-
Decoder: 3D Deconvolutional Neural Network
这一部分同样分为残差版本和普通版本,最后将32 ∗ \ast ∗ 32 ∗ \ast ∗ 32 ∗ \ast ∗ 2的输出使用voxel-wise softmax得到概率值(32 ∗ \ast ∗ 32 ∗ \ast ∗ 32)
-
Loss: 3D Voxel-wise Softmax
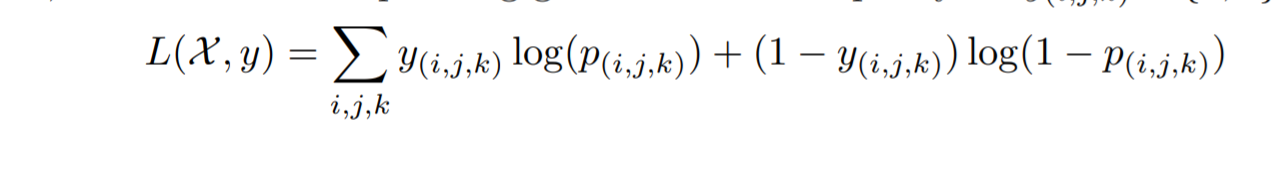

















 6436
6436

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









