









3D-R2N2: A unified approach for single and multi-view 3D object reconstruction (softmax CE)
输入:1或多张单个物体任意视角的图片 (encode成一个latent code)
输出:3D occupancy grid (323232)
loss: sum of voxel-wise 交叉熵。(虽然代码和这个有差别)

官方代码:
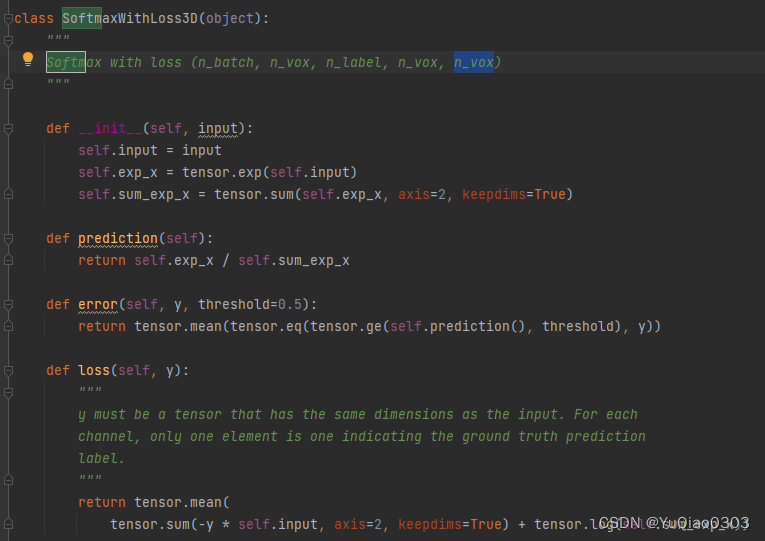
非官方torch代码:
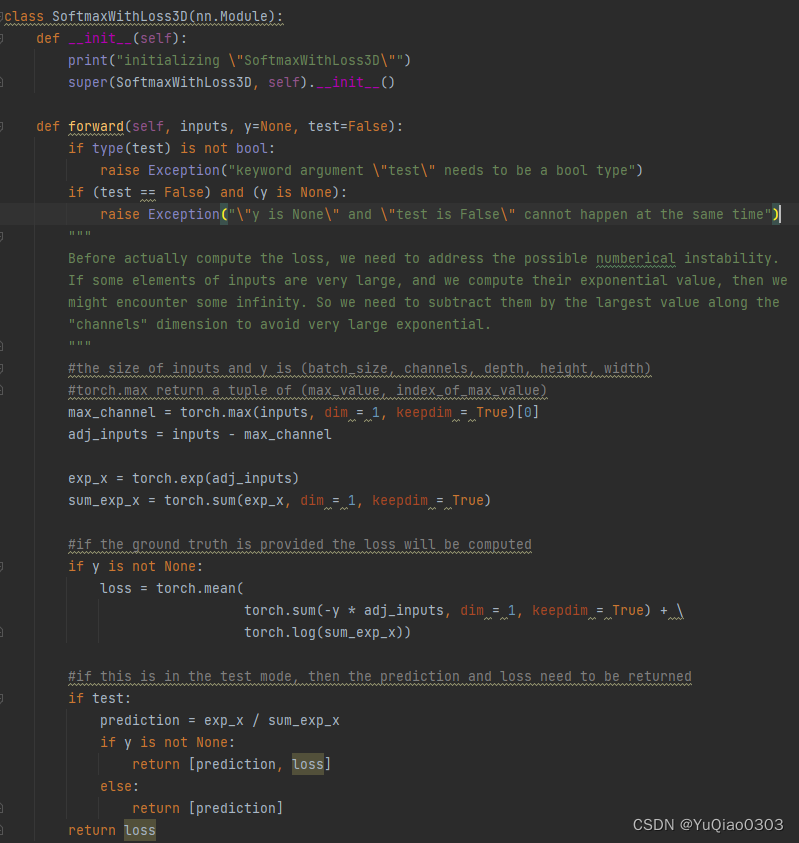
Learning a predictable and generative vector representation for objects (sigmoid CE + embedding)
https://rohitgirdhar.github.io/GenerativePredictableVoxels/
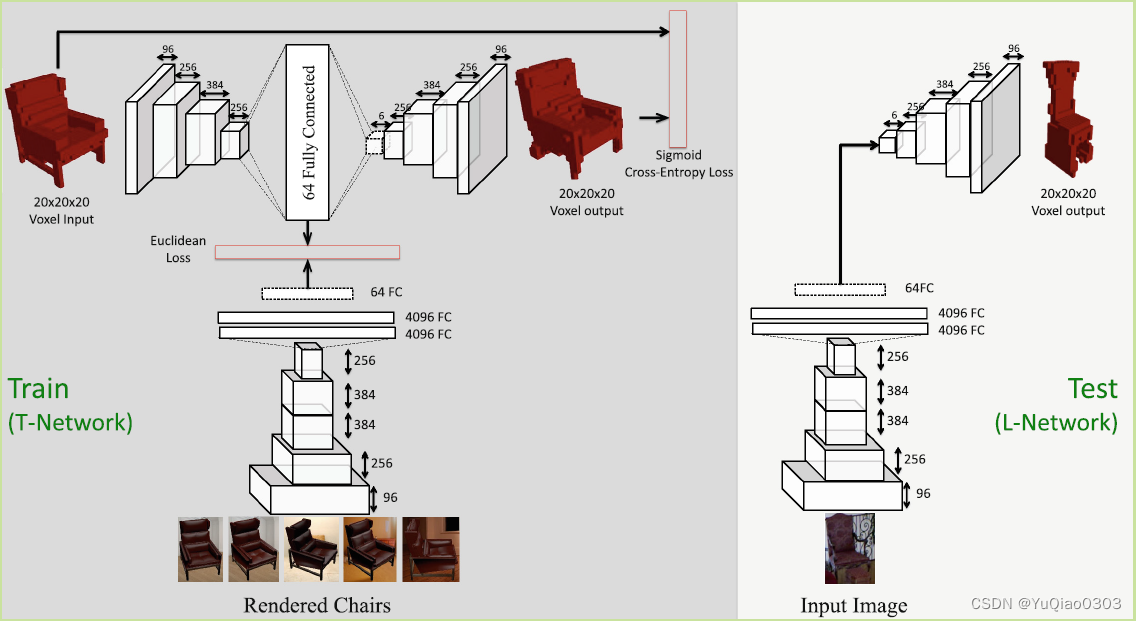
- 输入二维图像,输出体素。
- train的时候,用两个loss监督:
- 体素结果的sigmoid cross entropy loss
- 中间用一个auto encoder 来监督enbedding。(test的时候不用这个)
- 分辨率:202020
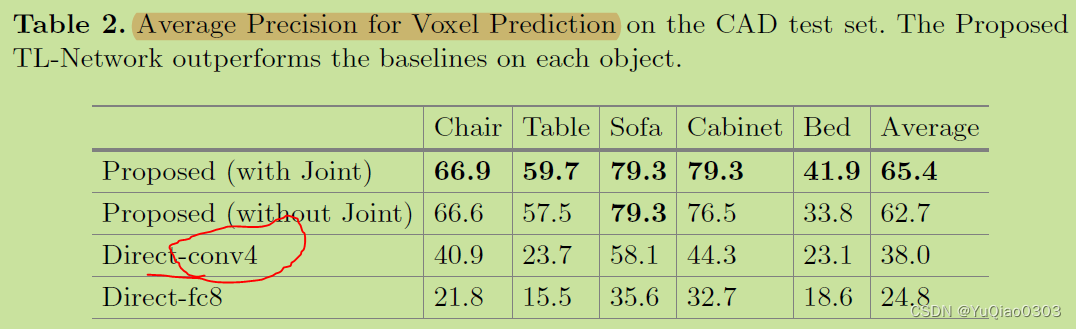
关于autoencoder的ablation study:
第16页, table 2 (FIg.7 里面其实没有消融实验, supllementary 里面也没有图)
网络结构:

Perspective transformer nets: Learning single-view 3D object reconstruction without 3D supervision
Hierarchical Surface Prediction
DLGAN:

输入单目深度图,输出体素。
方法:
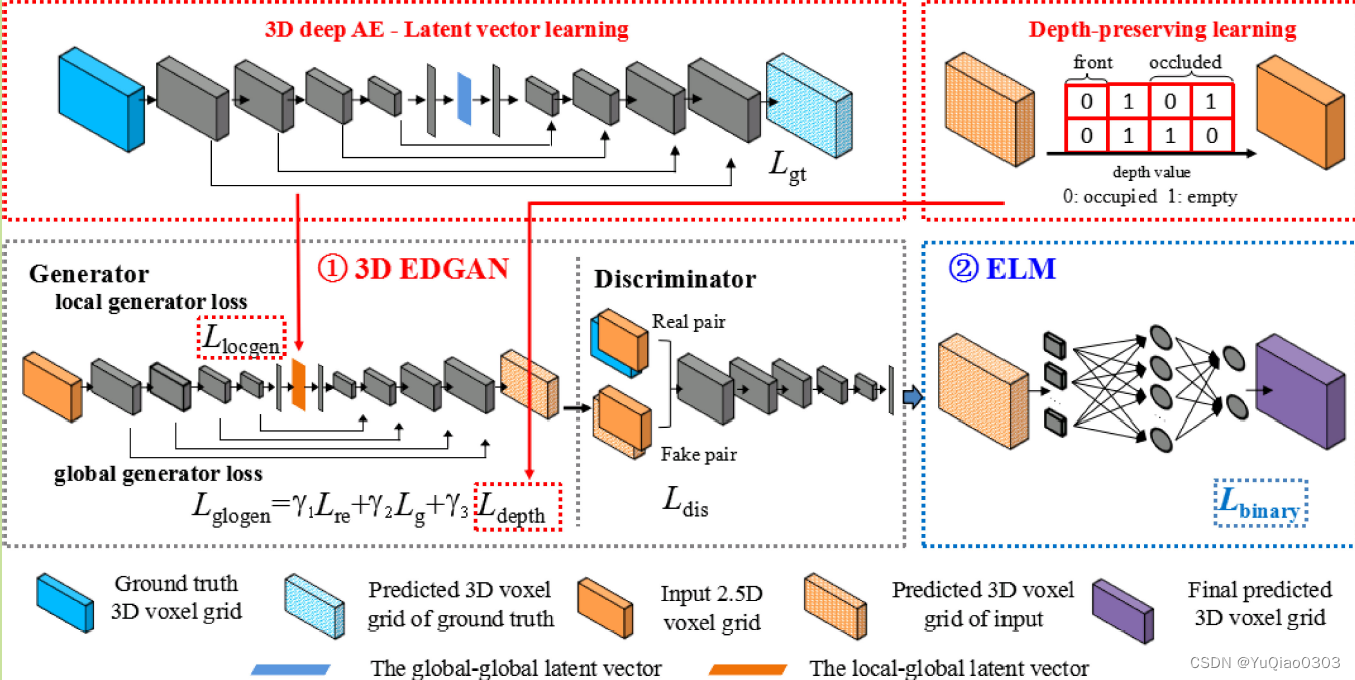
左上:用AE来学习GT 3d voxel grid 的 latent code。
左中:3D EDGAN对输入的2.5D voxel grid 学习latent code,然后decode出3D grid。 其中监督用到latent code loss (用上一步的Gt latent code监督), depth loss:希望生成的结果和input的deapth相符(右上), GAN loss:生成的结果和GT 一起投入GAN。
右中:ELM:将结果二值化。传统方法是用阈值来二值化,但这样不太好,难以联系邻居的情况,做不到local continuity。这一部的loss是L1距离。
- EDGAN: 从2.5D voxel grid 得到latent vector
- GAN loss
- latent vector loss:用AE从GT学到latent vector来监督我们从输入数据学到的latent vector
- depth loss: 用输入的2.5D数据监督这一步生成的3D voxel网格
- ELM (Extreame learning machine)将float的3D voxel二值化。有一个binary reconstruction loss。(一范数)
3D GAN: learning a probabilistic latent space of object shapes via 3D generative-advesarial modeling
就只有GAN loss。
generator是 kernal size是4,stride2,batch norm and ReLU
discrininator几乎一样,但用Leaky ReLU。

这是generator。z是长度为z_size的latent code。
以下顺序都是B,C,XYZ,
先reshape一下,变成 B, z_size, 1,1,1
然后第一个反卷积,得到B, 512,4,4,4
最后就变成了B,1,64,64,64,64

显然我需要加一层。
100,64,32,32
100,32,64,64,64
100,1,128,128,128
这样就可以了。















 4936
4936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









