









我们想要的是,在docker中挂载一个QNAP上的自定义目录,或者卷,而不是使用docker中默认的存储位置。但找不到在哪里设置。
原因分析
主要是QNAP的文档写的不够详细,没有对卷的功能做详细的描述,还有就是这个设置隐藏太深,很难发现,导致很多人不知道如何映射QNAP的本地路径。

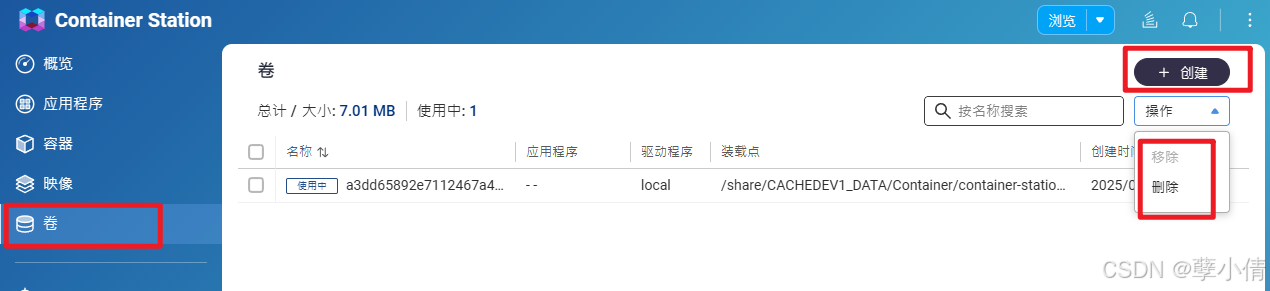
Container Station中对卷的设置非常容易引起歧义,这个地方的设置也简单粗暴,只有创建,操作中也只有移除,删除这两个简单操作。
解决方法
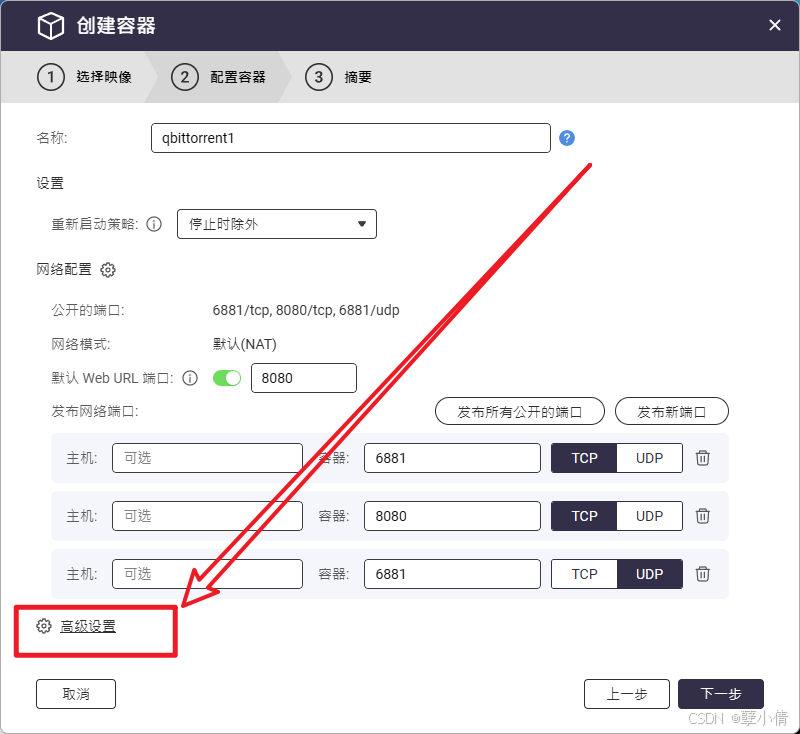
实际上设置并不在“卷”这里,而在创建容器的时候,需要点这里的高级设置
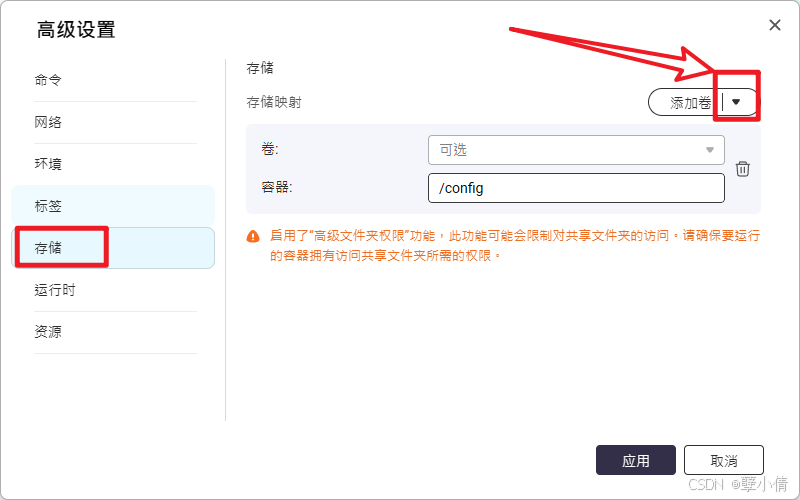
在高级设置中点击存储,然后点击添加卷右侧的下拉三角。
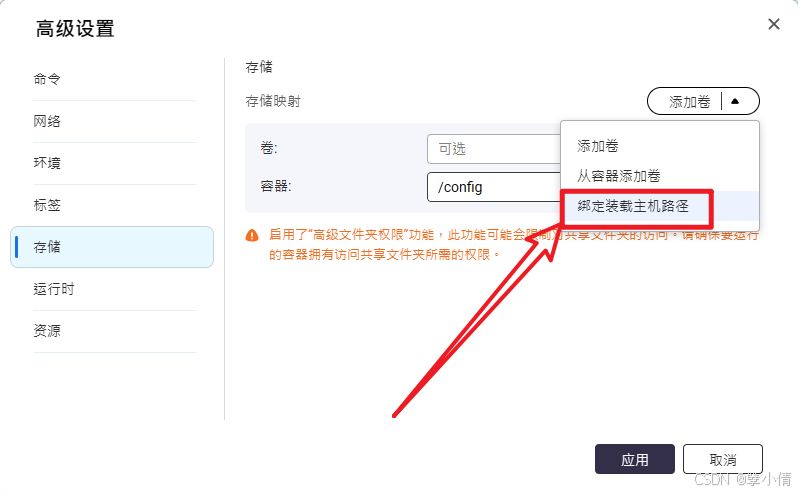
选择绑定装载机主机路径。即可建立主机与容器的目录映射。
 总结
总结
这是一个非常非常常用的功能,为什么要隐藏这么深? QNAP的产品不该反思下吗,这么多年市场占有率上不去是有原因的。



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











