










2.1 二分类问题
1. 两个问题
- 实现神经网络如果遍历训练集,不需要用for循环;
- 为什么神经网络的计算过程可以分为前向传播和后向传播;
2. 给出几个符号及含义
- 样本 ( x , y ) (x,y) (x,y),训练样本包括m个;
- x ∈ R n x x∈R^{n_{x}} x∈Rnx,表示样本x包含 n x n_{x} nx个特征(hight * width * channel);
- y ∈ ( 0 , 1 ) y∈(0,1) y∈(0,1),目标值属于0,1分类;
- 训练数据: ( x ( 1 ) , y ( 1 ) ) , ( x ( 2 ) , y ( 2 ) ) , . . . , ( x ( m ) , y ( m ) ) {(x^{(1)}, y^{(1)}), (x^{(2)}, y^{(2)}), ... , (x^{(m)}, y^{(m)})} (x(1),y(1)),(x(2),y(2)),...,(x(m),y(m));
- X = [ x ( 1 ) , x ( 2 ) , . . . , x ( m ) ] , X . s h a p e = ( n x , m ) X = [ x^{(1)}, x^{(2)} , ... , x^{(m)}],X.shape = (n_{x}, m) X=[x(1),x(2),...,x(m)],X.shape=(nx,m);
- Y = [ y ( 1 ) , y ( 2 ) , . . . , y ( m ) ] , Y . s h a p e = ( 1 , m ) Y = [ y^{(1)}, y^{(2)}, ... , y^{(m)} ],Y.shape = (1, m) Y=[y(1),y(2),...,y(m)],Y.shape=(1,m);
2.2 Logistic Regression
- l o g i s t i c r e g r e s s i o n logistic regression logisticregression用于二分类问题的监督学习;
- 分类任务中: G i v e n Given Given x x x, w a n t want want y ^ = P ( y = 1 ∣ x ) \widehat{y}=P(y=1|x) y =P(y=1∣x),其中 x ∈ R n x x \in R^{n_{x}} x∈Rnx, y ∈ { 0 , 1 } y \in \{0, 1\} y∈{0,1}, y ^ ∈ [ 0 , 1 ] \widehat{y}\in[0, 1] y ∈[0,1];
- Parameters: w ∈ R n x w \in R^{n_{x}} w∈Rnx, b ∈ R b\in R b∈R;
- 计算 y ^ = w T x + b \widehat{y}=w^{T}x+b y =wTx+b,引入sigmoid函数限制 y ^ \widehat{y} y 取值范围: y ^ = s i g m o i d ( w T x + b ) = σ ( w T x + b ) \widehat{y}=sigmoid(w^{T}x+b)=\sigma(w^{T}x+b) y =sigmoid(wTx+b)=σ(wTx+b);
- σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1 , σ ′ ( z ) = σ ( z ) ( 1 − σ ( z ) ) \sigma'(z)=\sigma(z)(1-\sigma(z)) σ′(z)=σ(z)(1−σ(z));
-
s
i
g
m
o
i
d
sigmoid
sigmoid函数图像:

- 梯度消失问题;
2.3 Logistic Regression cost function
为了训练 l o g i s t i c logistic logistic回归模型的参数 w w w以及 b b b,需要定义一个成本函数。
1. recap
- y ^ ( i ) = σ ( w T x ( i ) + b ) \widehat{y}^{(i)}=\sigma(w^{T}x^{(i)}+b) y (i)=σ(wTx(i)+b) w h e r e where where σ ( z ( i ) ) = 1 1 + e − z ( i ) \sigma(z^{(i)})=\frac{1}{1+e^{-z^{(i)}}} σ(z(i))=1+e−z(i)1, z ( i ) = w T x ( i ) + b z^{(i)}=w^{T}x^{(i)}+b z(i)=wTx(i)+b
- G i v e n Given Given X = { x ( 1 ) , x ( 2 ) , . . . , x ( m ) } X = \{x^{(1)}, x^{(2)} , ... , x^{(m)} \} X={x(1),x(2),...,x(m)}, w a n t want want y ^ ( i ) ≈ y ( i ) \widehat{y}^{(i)}\thickapprox y^{(i)} y (i)≈y(i)
2. loss (error) function
- 一般使用平方误差函数 ( s q u a r e d (squared (squared e r r o r ) error) error): L ( y ^ , y ) = 1 2 ( y ^ − y ) 2 L(\widehat{y}, y)= \frac{1}{2}(\widehat{y}-y)^{2} L(y ,y)=21(y −y)2,但在logistic regression里,一般不用平方误差作为loss function,因为平方误差损失函数一般是非凸函数,使用梯度下降时,容易得到局部最优解,而不是全局最优。
-
l
o
g
i
s
t
i
c
r
e
g
r
e
s
s
i
o
n
的
l
o
s
s
f
u
n
c
t
i
o
n
logistic regression 的 loss function
logisticregression的lossfunction:
L
(
y
^
,
y
)
=
−
(
y
l
o
g
y
^
+
(
1
−
y
)
l
o
g
(
1
−
y
^
)
)
L(\widehat{y}, y)= -(ylog\widehat{y}+(1-y)log(1-\widehat{y}))
L(y
,y)=−(ylogy
+(1−y)log(1−y
))
当 y = 1 y=1 y=1 时, L ( y ^ , y ) = − l o g y ^ L(\widehat{y}, y)= -log\widehat{y} L(y ,y)=−logy : y ^ → 1 \widehat{y}\rightarrow1 y →1时, L ( y ^ , y ) ≈ 0 L(\widehat{y}, y)\thickapprox0 L(y ,y)≈0,表示预测效果越好; y ^ → 0 \widehat{y}\rightarrow0 y →0时, L ( y ^ , y ) ≈ ∞ L(\widehat{y}, y)\thickapprox\infin L(y ,y)≈∞,表示预测效果越差;
当 y = 0 y=0 y=0 时, L ( y ^ , y ) = − l o g ( 1 − y ^ ) ) L(\widehat{y}, y)=-log(1-\widehat{y})) L(y ,y)=−log(1−y )) : y ^ → 0 \widehat{y}\rightarrow0 y →0时, L ( y ^ , y ) ≈ 0 L(\widehat{y}, y)\thickapprox0 L(y ,y)≈0,表示预测效果越好; y ^ → 1 \widehat{y}\rightarrow1 y →1时, L ( y ^ , y ) ≈ ∞ L(\widehat{y}, y)\thickapprox\infin L(y ,y)≈∞,表示预测效果越差; - l o s s f u n c t i o n loss function lossfunction是在单个训练样本中定义的,衡量了算法在单个训练样本上的表现。
3. Cost Function
- 衡量参数 w w w和 b b b在全体训练样本上的表现,是所有训练样本的 l o s s f u n c t i o n loss function lossfunction之和。
- J ( w , b ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) = − 1 m ∑ i = 1 m [ ( y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) ) ] J(w,b)=\frac{1}{m}\sum_{i=1}^mL(\widehat{y}^{(i)}, y^{(i)})=-\frac{1}{m}\sum_{i=1}^m[(ylog\widehat{y}+(1-y)log(1-\widehat{y}))] J(w,b)=m1∑i=1mL(y (i),y(i))=−m1∑i=1m[(ylogy +(1−y)log(1−y ))]
- C o s t F u n c t i o n Cost Function CostFunction是关于参数 w , b w,b w,b的函数,我们的目标是迭代计算出最佳的 w 和 b w和b w和b的值,最小化 C o s t F u n c t i o n Cost Function CostFunction,使其尽可能趋近于0。
2.4 梯度下降法
使用梯度下降法来训练或学习得到训练集上的参数 w w w和 b b b,使 c o s t cost cost f u n c t i o n function function最小。
-
r
e
p
e
a
t
:
{
repeat:\{
repeat:{
w = : w − α δ J ( w , b ) δ w w=:w-\alpha\frac{\delta J(w,b)}{\delta w} w=:w−αδwδJ(w,b)
b = : b − α δ J ( w , b ) δ b b=: b-\alpha\frac{\delta J(w,b)}{\delta b} b=:b−αδbδJ(w,b)
} \} }
在程序代码中通常使用 d w dw dw来表示 δ J ( w , b ) δ w \frac{\delta J(w,b)}{\delta w} δwδJ(w,b), d b db db来表示 δ J ( w , b ) δ b \frac{\delta J(w,b)}{\delta b} δbδJ(w,b)。 - 直观看梯度下降:

- 从低维解释梯度下降:

2.5 计算图
一个神经网络的计算都是按照前向或反向传播的过程来计算的。首先计算出神经网络的输出,接着进行反向传输操作(计算对应的梯度或导数)。
- 示例:

2.6 Logistc Regression中的梯度下降
-
L o g i s t i c Logistic Logistic R e g r e s s i o n Regression Regression中的 l o s s loss loss f u n c t i o n function function表达式:
z = w T x + b z=w^{T}x+b z=wTx+b
y ^ = a = σ ( z ) \widehat{y}=a=\sigma(z) y =a=σ(z)
L ( a , y ) = − ( y ∗ l o g ( a ) + ( 1 − y ) ∗ l o g ( 1 − a ) ) L(a, y)=-(y*log(a)+(1-y)*log(1-a)) L(a,y)=−(y∗log(a)+(1−y)∗log(1−a)) -
反向传播过程:
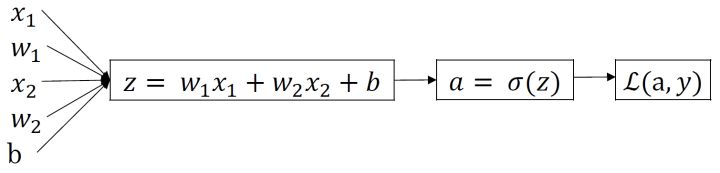
-
反向传播计算导数:
d a = δ L δ a = − y a + 1 − y 1 − a da=\frac{\delta L}{\delta a}=- \frac{y}{a}+\frac{1-y}{1-a} da=δaδL=−ay+1−a1−y
d z = δ L δ z = δ L δ a ⋅ δ a δ z = ( − y a + 1 − y 1 − a ) ⋅ a ( 1 − a ) = a − y dz=\frac{\delta L}{\delta z}=\frac{\delta L}{\delta a}·\frac{\delta a}{\delta z}=(-\frac{y}{a}+\frac{1-y}{1-a})·a(1-a)=a-y dz=δzδL=δaδL⋅δzδa=(−ay+1−a1−y)⋅a(1−a)=a−y
d w 1 = δ L δ w 1 = δ L δ z ⋅ δ z δ w 1 = ( a − y ) ⋅ x 1 dw_1=\frac{\delta L}{\delta w_1}=\frac{\delta L}{\delta z}·\frac{\delta z}{\delta w_1}=(a-y)·x_1 dw1=δw1δL=δzδL⋅δw1δz=(a−y)⋅x1
d b = δ L δ b = δ L δ z ⋅ δ z δ b = a − y d_b=\frac{\delta L}{\delta b}=\frac{\delta L}{\delta z}·\frac{\delta z}{\delta b}=a-y db=δbδL=δzδL⋅δbδz=a−y
-
参数更新:
w 1 = : w 1 − α d w 1 w_1=:w_1-\alpha dw_1 w1=:w1−αdw1
w 2 = : w 2 − α d w 2 w_2=:w_2-\alpha dw_2 w2=:w2−αdw2
b = : b − α d b b=:b-\alpha db b=:b−αdb
2.7 m个样本的梯度下降
-
l o g i s t i c logistic logistic r e g r e s s i o n regression regression 中 c o s t cost cost f u n c t i o n function function表达:
z ( i ) = w T x ( i ) + b z^{(i)}=w^{T}x^{(i)}+b z(i)=wTx(i)+b
y ^ ( i ) = a ( i ) = σ ( z ( i ) ) \widehat y^{(i)}=a^{(i)}=\sigma(z^{(i)}) y (i)=a(i)=σ(z(i))
J ( w , b ) = 1 m ∑ i = 1 m L ( y ^ ( i ) , y ( i ) ) = − 1 m ∑ i = 1 m [ ( y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) ) ] J(w,b)=\frac{1}{m}\sum_{i=1}^mL(\widehat{y}^{(i)}, y^{(i)})=-\frac{1}{m}\sum_{i=1}^m[(ylog\widehat{y}+(1-y)log(1-\widehat{y}))] J(w,b)=m1∑i=1mL(y (i),y(i))=−m1∑i=1m[(ylogy +(1−y)log(1−y ))]
-
全局成本函数实际上是 1 1 1 到 m m m项损失函数和的平均,因此全局成本函数对 w 1 w_1 w1的导数,同样是各项损失函数对 w 1 w_1 w1导数和的平均值。即:
d z ( i ) = a ( i ) − y ( i ) dz^{(i)}=a^{(i)}-y^{(i)} dz(i)=a(i)−y(i)
d w 1 = 1 m ∑ i = 1 m d z ( i ) ⋅ x 1 ( i ) dw_1=\frac{1}{m}\sum_{i=1}^{m}dz^{(i)}·x_1^{(i)} dw1=m1∑i=1mdz(i)⋅x1(i)
d w 2 = 1 m ∑ i = 1 m d z ( i ) ⋅ x 2 ( i ) dw_2=\frac{1}{m}\sum_{i=1}^{m}dz^{(i)}·x_2^{(i)} dw2=m1∑i=1mdz(i)⋅x2(i)
d b = 1 m ∑ i = 1 m ( a ( i ) − y ( i ) ) d_b =\frac{1}{m}\sum_{i=1}^{m}(a^{(i)}-y^{(i)}) db=m1∑i=1m(a(i)−y(i))
- 参数更新
2.8 向量化
深度学习的算法中,我们通常面临大数据集,程序编写过程中,尽可能减少loop循环语句,使用向量化提高程序运行速度。
-
逻辑回归向量化
输入矩阵 X : ( n x , m ) X:(n_x,m) X:(nx,m)
权重矩阵 w : ( n x , 1 ) w:(n_x,1) w:(nx,1)
偏置变量 b : 一 个 常 数 b:一个常数 b:一个常数
输出矩阵 Y : ( 1 , m ) Y:(1,m) Y:(1,m) -
单次迭代梯度下降算法流程:
#正向
Z = np.dot(w.T,X)+b
A = sigmoid(Z)
#反向
dZ = A - Y
dw = 1/m * np.dot(X,dZ.T)
db = 1/m * np.sum(dZ)
#参数更新
w = w - alpha * dw
b = b - alpha * db
2.9 logistic regression cost function 的解释
预测输出 y ^ = σ ( w T x + b ) , w h e r e \widehat{y}=\sigma(w^Tx+b),where y =σ(wTx+b),where σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1, y ^ \widehat{y} y 表示预测输出为正类(+1)的概率。
-
l
o
s
s
loss
loss
f
u
n
c
t
i
o
n
:
function:
function:
y ^ = P ( y = 1 ∣ x ) \widehat{y}=P(y=1|x) y =P(y=1∣x):当 y = 1 y=1 y=1时, P ( y ∣ x ) = y ^ P(y|x)=\widehat{y} P(y∣x)=y ;当 y = 0 y=0 y=0时, P ( y ∣ x ) = 1 − y ^ P(y|x)=1-\widehat{y} P(y∣x)=1−y 。
上述两种情况整合到一起,即 P ( y ∣ x ) = y ^ y ( 1 − y ^ ) 1 − y P(y|x)=\widehat{y}^{y}(1-\widehat{y})^{1-y} P(y∣x)=y y(1−y )1−y。
对上式进行log处理(单调函数不影响原函数的单调性):
l o g P ( y ∣ x ) = l o g ( y ^ y ( 1 − y ^ ) 1 − y ) = y l o g y ^ + ( 1 − y ) ( 1 − y ^ ) logP(y|x)=log(\widehat{y}^{y}(1-\widehat{y})^{1-y})=ylog\widehat{y}+(1-y)(1-\widehat{y}) logP(y∣x)=log(y y(1−y )1−y)=ylogy +(1−y)(1−y )
概率 P ( y ∣ x ) P(y|x) P(y∣x)表示预测的准确性,越大越好。对上式加上负号,转化为单个样本的 l o s s loss loss函数,期望越小越好:
L ( y ^ , y ) = − ( y l o g y ^ + ( 1 − y ) ( 1 − y ^ ) ) L(\widehat{y},y)=-(ylog\widehat{y}+(1-y)(1-\widehat{y})) L(y ,y)=−(ylogy +(1−y)(1−y )) -
c
o
s
t
cost
cost
f
u
n
c
t
i
o
n
:
function:
function:
m m m个训练样本时,假设样本之间独立同分布,则:
P ( l a b e l P(label P(label i n in in l a b e l s e t ) = ∏ i = 1 m P ( y ( i ) ∣ x ( i ) ) labelset)=\prod_{i=1}^{m}P(y^{(i)}|x^{(i)}) labelset)=∏i=1mP(y(i)∣x(i))
⇒ l o g P ( . . . ) = ∑ i = 1 m P ( y ( i ) ∣ x ( i ) ) = − ∑ i = 1 m L ( y ^ , y ) \Rightarrow logP(...)=\sum^m_{i=1}P(y^{(i)}|x^{(i)})=-\sum^m_{i=1}L(\widehat{y},y) ⇒logP(...)=∑i=1mP(y(i)∣x(i))=−∑i=1mL(y ,y)
此时 c o s t cost cost f u n c t i o n : function: function:(因为 c o s t cost cost求最小,加负号)
J ( w , b ) = 1 m ∑ i = 1 m L ( y ^ , y ) = − 1 m ∑ i = 1 m ( y l o g y ^ + ( 1 − y ) ( 1 − y ^ ) ) J(w,b)=\frac{1}{m}\sum_{i=1}^{m}L(\widehat{y},y)=-\frac{1}{m}\sum_{i=1}^{m}(ylog\widehat{y}+(1-y)(1-\widehat{y})) J(w,b)=m1∑i=1mL(y ,y)=−m1∑i=1m(ylogy +(1−y)(1−y ))
参考资料:
[1] Andrew Ng 课程笔记连载:https://zhuanlan.zhihu.com/p/29688927
[2] 网易云课堂 Andrew Ng课程
本周编程作业链接:https://blog.csdn.net/iCode_girl/article/details/86702982
测验链接:https://blog.csdn.net/u013733326/article/details/79865858















 362
362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









