










4.1 矩阵的维数
- DNN结构示意图:

对于第 l l l 层神经网络,单个样本及各个参数的矩阵维度为: - W [ l ] : ( n [ l ] , n [ l − 1 ] ) W^{[l]} : (n^{[l]},n^{[l-1]}) W[l]:(n[l],n[l−1])
- b [ l ] : ( n [ l ] , 1 ) b^{[l]} : (n^{[l]},1) b[l]:(n[l],1)
- d W [ l ] : ( n [ l ] , n [ l − 1 ] ) dW^{[l]} : (n^{[l]},n^{[l-1]}) dW[l]:(n[l],n[l−1])
- d b [ l ] : ( n [ l ] , 1 ) db^{[l]} : (n^{[l]},1) db[l]:(n[l],1)
- Z [ l ] : ( n [ l ] , 1 ) Z^{[l]} : (n^{[l]},1) Z[l]:(n[l],1)
- A [ l ] = Z [ l ] : ( n [ l ] , 1 ) A^{[l]}=Z^{[l]} : (n^{[l]},1) A[l]=Z[l]:(n[l],1)
4.2 为什么使用深层表示

对于人脸识别,神经网络的第一层从原始图片中提取人脸的轮廓和边缘,每个神经元学习到不同边缘的信息;网络的第二层将第一层学得的边缘信息组合起来,形成人脸的一些局部的特征,例如眼睛、嘴巴等;后面的几层逐步将上一层的特征组合起来,形成人脸的模样。随着神经网络层数的增加,特征也从原来的边缘逐步扩展为人脸的整体,由整体到局部,由简单到复杂。层数越多,那么模型学习的效果也就越精确。
对于语音识别,第一层神经网络可以学习到语言发音的一些音调,后面更深层次的网络可以检测到基本的音素,再到单词信息,逐渐加深可以学到短语、句子。
所以从上面的两个例子可以看出随着神经网络的深度加深,模型能学习到更加复杂的问题,功能也更加强大。
4.3 前向和反向传播
DNN的一些参数:
- L : L: L:DNN的总层数;
- n [ l ] : n^{[l]}: n[l]:表示第 l l l 层包含单元的个数;
- a [ l ] : a^{[l]}: a[l]:表示第 l l l 层激活函数的输出;
- W [ l ] : W^{[l]}: W[l]:表示第 l l l 层的权重;
- 输入 x x x 又为 a [ 0 ] a^{[0]} a[0],输出 y ^ \hat{y} y^又为 a [ L ] a^{[L]} a[L].
前向传播:
- Input: a [ l − 1 ] a^{[l-1]} a[l−1]
- Output: a [ l ] , c a c h e ( z [ l ] ) a^{[l]} , \rm cache(z^{[l]}) a[l],cache(z[l])
- 公式:
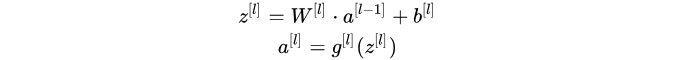
- 向量化程序:
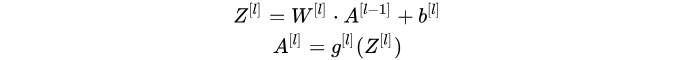
反向传播:
- Input: d a [ l ] da^{[l]} da[l]
- Output: d a [ l − 1 ] , d W [ l ] , d b [ l ] da^{[l-1]} , dW^{[l]} ,db^{[l]} da[l−1],dW[l],db[l]
- 公式:
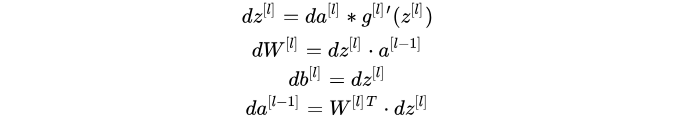
- 向量化程序:
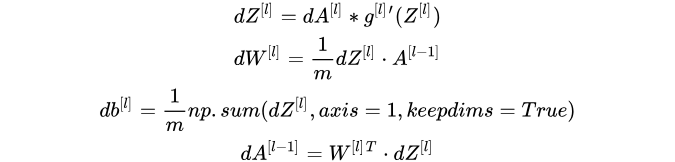
4.4 参数和超参数
参数: 在训练过程中想要模型学习到的信息, W [ l ] W^{[l]} W[l], b [ l ] b^{[l]} b[l]。
超参数: 控制参数的输出值的一些网络信息,也就是超参数的改变会导致最终得到的参数 W [ l ] W^{[l]} W[l], b [ l ] b^{[l]} b[l]的改变。
超参数举例:
- 学习速率: α \alpha α
- 迭代次数:N
- 隐藏层的层数:L
- 每一层的神经元个数: n [ 1 ] , n [ 2 ] , . . . n^{[1]},n^{[2]},... n[1],n[2],...
- 激活函数 g ( z ) g(z) g(z)的选择
本文完全来自:https://blog.csdn.net/koala_tree/article/details/78087711















 1444
1444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









