









这是我们《GPU高性能运算之CUDA》一书的勘误表,多谢读者朋友的反馈与分享~~
1. 前言中的致谢部分:
讨论群中的陈国峰、
修改为:
讨论群中的刘伟峰、刘国峰、
2. 前言中的致谢部分:
以及 NVIDIA 深圳有限公司的 Terrence Hong, Jerry Zhou, Jonny Qiu, Blues Yu, Jerry Jia, Donaven Chen, Sandy Zou 等同事的支持;
修改为:
以及 NVIDIA 深圳有限公司的 Terence horng, Jerry Zhou, Johnny Qiu, Blues Yu, Jerry Jia, Donovan Chen, Sandy Zou 等同事的支持;
3. 第 3 页
现代 CPU 的分支预测正确率已经达到了 99% 以上
修改为:
现代 CPU 的分支预测正确率已经达到了 95% 以上
4. 第 19 页代码中的:
"s_data[128] = A[bid *128 + tid]"
修改为:
"s_data[tid] = A[bid *128 + tid]"
5. 第 30 页
“整个 grid 中最多也只能定义 65535 个 block"
修改为:
“整个 grid 中最多能定义 65535 * 65535 个 block"
” Db.x 和 Db.y 最大值为 512 , Db.z 最大为 4 “
修改为:
"Db.x 和 Db.y 最大值为 512 , Db.z 最大为 64"
6. 第 32 页
gridDim 。 grid dimension ,用于说明整个网格的维度与尺寸,与 host 端 <<< >>> 中的 Ng 相对应; gridDim.x , gridDim.y 分别与 Ng.x,Ng.y 相等
修改为:
gridDim 。 grid dimension ,用于说明整个网格的维度与尺寸,与 host 端 <<< >>> 中的 Dg 相对应; gridDim.x , gridDim.y 分别与 Dg.x,Dg.y 相等
blockDim 。 block Dimension ,用于说明每个 block 的维度与尺寸,与 host 端 <<<>>> 中的 Nb 对应; blockDim.x, blockDim.y, blockDim.z 分别与 Nb.x, Nb.y, Nb.z 相等。
应为:
blockDim 。 block Dimension ,用于说明每个 block 的维度与尺寸,与 host 端 <<< >>> 中的 Db 对应; blockDim.x , blockDim.y , blockDim.z 分别与 Db.x , Db.y , Db.z 相等。
7. 第 31 页图 2-8
右边的 block 标号应为 (1,0)
见附件图
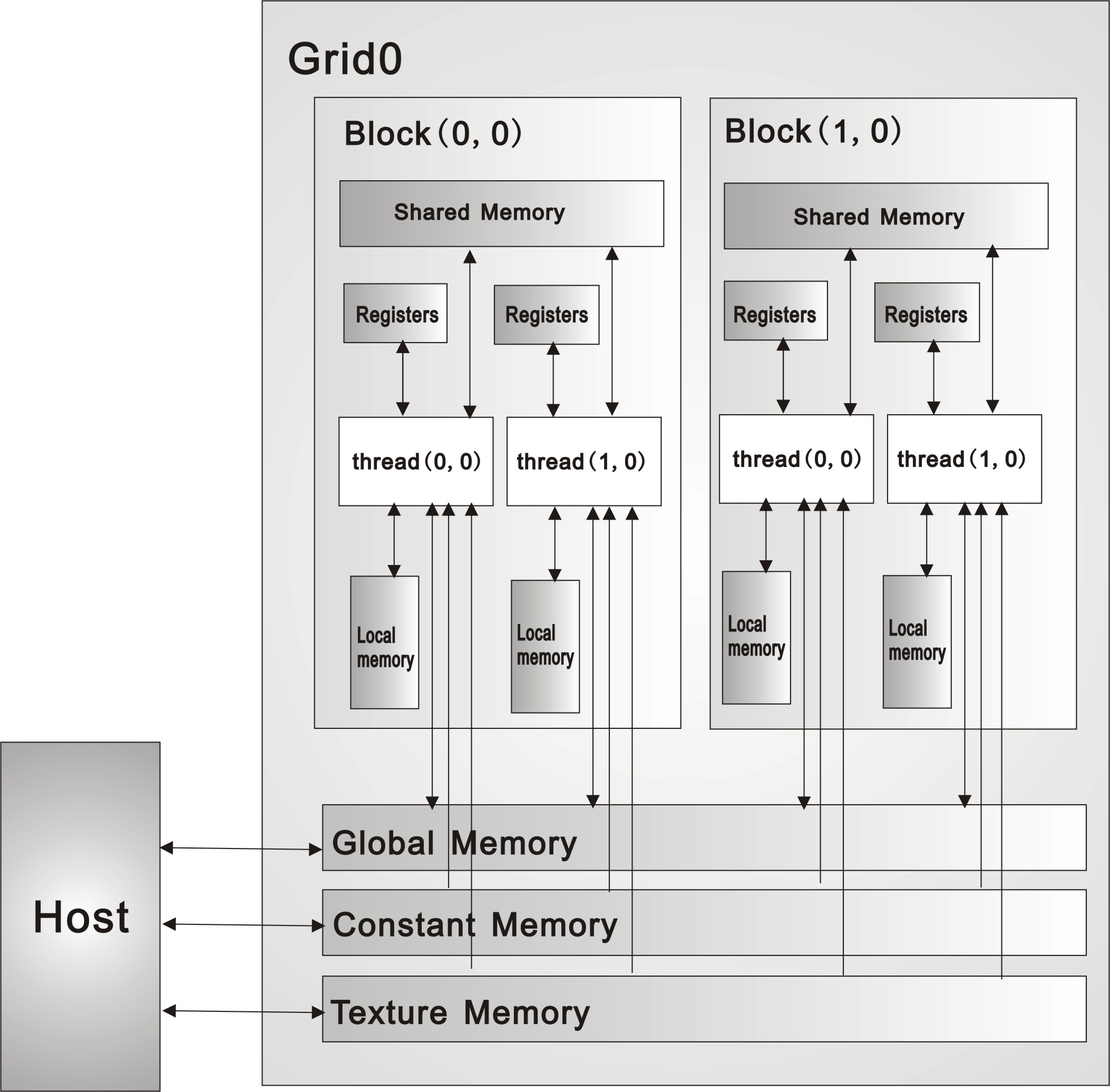
图2-8,图2-17
8. 第 44 页图 2-17
右边的 block 标号应为 (1,0)
见附件图
9. 第 66 页
“ output[y * width + x] = tex2D[tex, tu, ty];”
修改为:
“ output[y * width + x] = tex2D[texRef, tu, ty];”
10. 第 72 页
执行 __thradfence_block() 、 __threadfence() 或 __syncthreads() ,
修改为:
执行 __threadfence() 、 __threadfence_block() 、或 __syncthreads() ,
11. 第 80 页
cudaStreamDestroy(&stream[i]);
修改为:
cudaStreamDestroy(stream[i]);
12. 第 81 页
For (int i = 0; i < 2; ++i)
cudamemcpyasync(inputdevptr + i * size, hostptr + i * size,size, cudamemcpyhosttodevice, stream);
For (int i = 0; i < 2; ++i)
mykernel<<<100, 512, 0, stream>>>(outputdevptr + i * size, inputdevptr + i * size, size);
For (int i = 0; i < 2; ++i)
cudamemcpyasync(hostptr + i * size, outputdevptr + i * size,size, cudamemcpydevicetohost, stream);
Cudathreadsynchronize();
修改为:
for (int i = 0; i < 2; ++i)
cudamemcpyasync(inputdevptr + i * size/sizeof(float), hostptr + i * size/sizeof(float) ,size, cudamemcpyhosttodevice, stream);
for (int i = 0; i < 2; ++i)
mykernel<<<100, 512, 0, stream>>>(outputdevptr + i * size, inputdevptr + i * size, size);
For (int i = 0; i < 2; ++i)
cudamemcpyasync(hostptr + i * size/sizeof(float), outputdevptr + i * size/sizeof(float),size, cudamemcpydevicetohost, stream);
Cudathreadsynchronize();
13. 第 133 页
关于增加 active block 和 active warp 数量优化程序性能的讨论,请见本书 4.6.2 、 4.6.3 和 4.6.4 节。
修改为:
关于增加 active block 和 active warp 数量优化程序性能的讨论,请见本书 4.3.2 节。
14. 第 137 页
对图 3-10 的修改
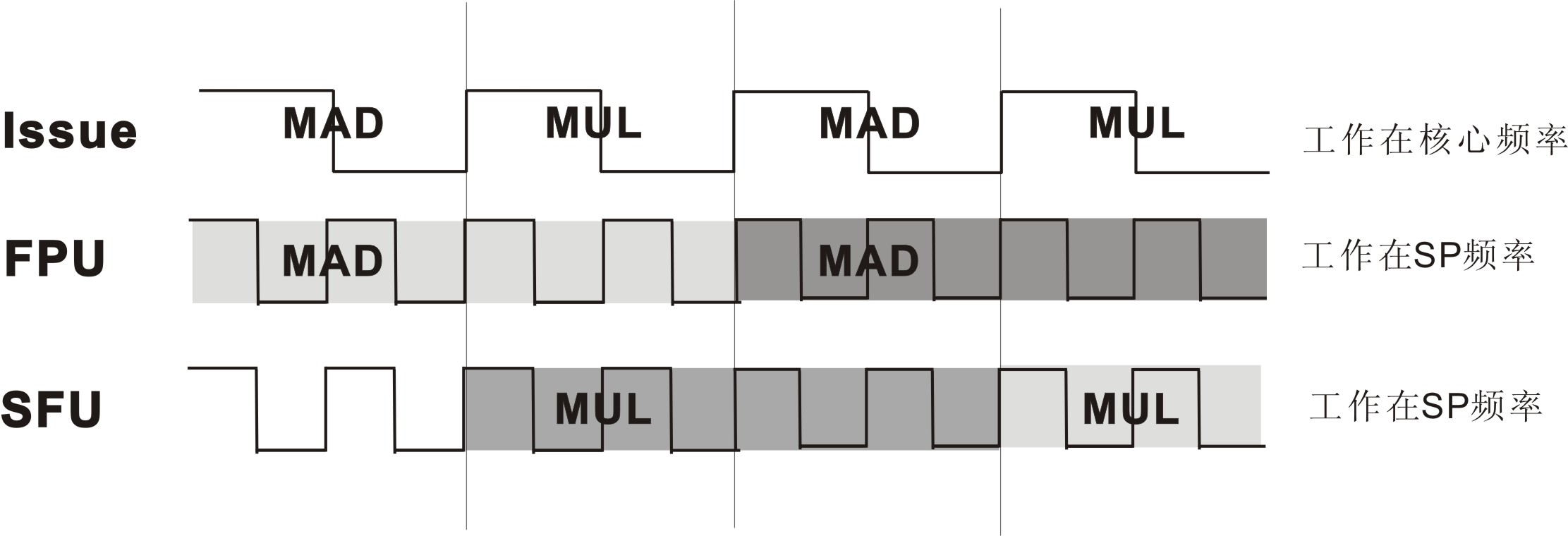
图 3-10 双发射时序示意图(不代表实际实现)
15. 第 197 页
“如果⊙为 .. ”
修改为:
“如果⊕为 .. ”
16. 第 238 页 规则添加里的第( 3 )条
( 3 )重启 VS 环境。
修改为:
( 3 )在工程名上右键,选择 custom build rules->Find Existing ,选中 cuda.rules ,点击 ok 。
17. 作者简介
张舒, 电子科技大学信息与通信工程专业硕士,现任 NVIDIA 深圳有限公司系统设计验证工程师, CUDA 技术顾问。曾实现基于 CUDA 的神经网络、聚类分析、主分量分析等模式识别算法,以及信号仿真、密码破解、字符串匹配等应用。
褚艳利, 西安电子科技大学计算机系硕士在读,从事高性能计算、模型验证、软件测试与自演化技术的研发工作,喜欢并精于算法设计与数据结构,多次参加 ACM/ICPC 程序设计大赛与数模竞赛。 CUDA 编程及优化经验丰富, GPU 高性能计算技术推广者。
赵开勇, 本科毕业于北京理工大学飞行器总体设计专业,曾任 CCUR( 美国并行计算机公司 ) 亚太区技术支持,现就读于香港浸会大学计算机系,主要从事高性能计算与网络编码技术的研究。在 CSDN 论坛中担任 CUDA 和高性能计算两个板块的大版主,积极推广高性能计算。同时担任浪潮集团 GPU 高性能开发顾问,提供各种应用的 GPU 高性能计算解决方案。任 2009 年 Nvidia CUDA 校园程序设计大赛评委。 http://www.hpctech.com 网站创始人之一。
张钰勃, 长期从事数值计算,计算流体力学,计算机图形学及可视化等领域的研究,拥有丰富的 GPU 并行计算经验。曾在浙江大学 CAD&CG 国家重点实验室参与国家 973 研究项目并在国内外会议期刊发表多篇优秀论文。本科与硕士分别毕业于浙江大学数学系和香港浸会大学数学系,现于加州大学戴维斯分校攻读计算机博士学位。















 9846
9846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









