







 本文介绍了线性分类器的基础,特别是SVM的score function和loss function。通过非向量化和向量化实现,详细阐述了损失函数的计算及梯度求解过程,强调了广播运算在矩阵操作中的重要性,并提供了理解和优化代码的见解。
本文介绍了线性分类器的基础,特别是SVM的score function和loss function。通过非向量化和向量化实现,详细阐述了损失函数的计算及梯度求解过程,强调了广播运算在矩阵操作中的重要性,并提供了理解和优化代码的见解。
Assignment 1# SVM
线性分类器简介:
在这里的两个分类器SVM和softmax都是线性分类器,也是后序神经网络的基础。他由两部分组成:score function和loss function。
前者通过 W T x + b W^Tx+b WTx+b的线性方式计算出每一个图片向量对于不同类别的得分,后者则采用不同的loss对误差进行度量(SVM or softmax)。
score function:
对于一张高维的图片,首先还是将它伸展为一维的列向量。 W T x + b W^Tx+b WTx+b获得不同类别的得分向量。如下图所示。对于为什么矩阵相乘,W矩阵的意义是什么,解释是模式匹配。
W W W的每一行可以认为是各类别的模版(如下图中第一行可以认为是猫向量,算法认为标准的猫就是行向量的样子),每一行与图片向量的点乘可以看作一种距离的度量方式(很简单,如果两个向量相似,他们的余弦就小,点乘的结果就更大)。这样score越大就认为越可能属于该类。下图也提供了对训练后的 W W W可视化,更加印证了模式匹配这一观点。


loss function
loss function 分为两部分,分类误差和泛化误差。
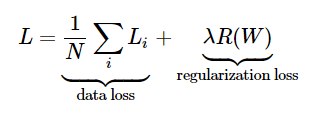
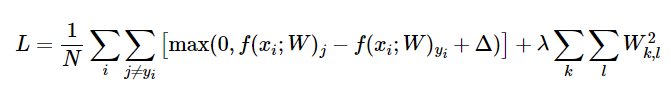
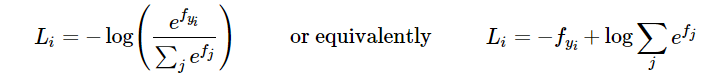
naive implementation:
这两部分分别现在linear_SVM.py 里面写好,是可以采用循环的。
loss function:
inputs:
- W: A numpy array of shape (D, C) containing weights.
- X: A numpy array of shape (N, D) containing a minibatch of data.
- y: A numpy array of shape (N,) containing training labels;
对所有的N个样本循环,计算每一个的loss L i L_i Li。对于每一个 L i L_i Li先求出得分向量scores。 x [ i ] T W x[i]^TW x[i]TW。具体谁乘谁可以形状判断。遍历所有的错误类别看它的得分是不是超过正确类别大于一。
最后平均在加上reg loss。
num_classes = W.shape[1]
num_train = X.shape[0]
loss = 0.0
for i in range(num_train):
scores = X[i].dot(W)
correct_class_score = scores[y[i]]
for j in range(num_classes):
if j == y[i]:
continue
margin = scores[j] - correct_class_score + 1 # note delta = 1
if margin > 0:
loss += margin
loss /= num_train
loss += reg * np.sum(W * W)
gradient:
唯一可以依靠的就是上面loss 的计算式子。
感觉这里也是为后面的BP做铺垫,唯有链式法则方为正道。
两部分,reg loss部分的导数很简单,就是W矩阵的二倍。
model loss 部分。对于每个i我们对上式拆分 ∑ j ≠ y i [ max ( 0 , x i W j − x i W y i + δ ) ] \sum_{j\neq y_i}[\max(0,x_iW_j-x_iW_{y_i}+\delta)] ∑j=yi[max(0,xiWj−
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1673
1673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









