









【原文地址】:https://www.vincentqin.tech/posts/light-field-depth-estimation/(排版更美观)
本文将介绍光场领域进行深度估计的相关研究。
In this post, I’ll introduce some depth estimation algorithms using Light field information. Here is some of the code.
研究生阶段的研究方向是光场深度信息的恢复。再此做一些总结,以便于让大家了解光场数据处理的一般步骤以及深度估计的相关的知识。如有任何疑问或者建议,请大家在评论区提出,或者直接访问这里。
什么是光场?
提到光场,很多人对它的解释模糊不清,在此我对它的概念进行统一表述。它的故事可以追溯到1936年,那是一个春天,Gershun写了一本名为The Light Field1的鸿篇巨著(感兴趣的同学可以看看那个年代的论文),于是光场的概念就此诞生,但它并没有因此被世人熟知。经过了近六十年的沉寂,1991年Adelson2等一帮帅小伙将光场表示成了如下的7维函数:
P ( θ , ϕ , λ , t , V x , V y , V z ) . (1) P(\theta,\phi,\lambda,t,V_x,V_y,V_z). \tag{1} P(θ,ϕ,λ,t,Vx,Vy,Vz).(1)
其中
(
θ
,
ϕ
)
(\theta,\phi)
(θ,ϕ)表示球面坐标,
λ
\lambda
λ表示光线的波长,
t
t
t表示时间,
(
V
x
,
V
y
,
V
z
)
(V_x,V_y,V_z)
(Vx,Vy,Vz)表示观察者的位置。
可以想象假如有这样一张由针孔相机拍摄的黑白照片,它表示:我们从某个时刻、单一视角观察到的可见光谱中某个波长的光线的平均。也就是说,它记录了通过
P
P
P点的光强分布,光线方向可以由球面坐标
P
(
θ
,
ϕ
)
P(\theta,\phi)
P(θ,ϕ)或者笛卡尔坐标
P
(
x
,
y
)
P(x,y)
P(x,y)来表示。对于彩色图片而言,我们要添加光线的波长
λ
\lambda
λ信息即变为
P
(
θ
,
ϕ
,
λ
)
P(\theta,\phi,\lambda)
P(θ,ϕ,λ)。按照同样的思路,彩色电影也就是增加了时间维度
t
t
t,因此
P
(
θ
,
ϕ
,
λ
,
t
)
P(\theta,\phi,\lambda,t)
P(θ,ϕ,λ,t)。对于彩色全息电影而言,我们可以从任意空间位置
(
V
x
,
V
y
,
V
z
)
(V_x,V_y,V_z)
(Vx,Vy,Vz)进行观看,于是其可以表达为最终的形式
P
(
θ
,
ϕ
,
λ
,
t
,
V
x
,
V
y
,
V
z
)
P(\theta,\phi,\lambda,t,V_x,V_y,V_z)
P(θ,ϕ,λ,t,Vx,Vy,Vz)。这个函数又被成为全光函数(Plenoptic Function)。
但是以上的七维的全光函数过于复杂,难以记录以及编程实现。所以在实际应用中我们对其进行简化处理。第一个简化是单色光以及时不变。可分别记录3原色以简化掉波长
λ
\lambda
λ,可以通过记录不同帧以简化
t
t
t,这样全光函数就变成了5D。第二个简化是Levoy3等人(1996年)认为5D光场中还有一定的冗余,可以在自由空间(光线在传播过程中能量保持不变)中简化成4D。
光场参数化表示
参数化表示要解决的问题包括:1. 计算高效;2. 光线可控;3. 光线均匀采样。目前比较常用的表示方式是双平面法( 2 P P 2PP 2PP)3,利用双平面法可以将光场表示为: L ( u , v , s , t ) L(u,v,s,t) L(u,v,s,t)。其中 ( u , v ) (u,v) (u,v)为第一个平面, ( s , t ) (s,t) (s,t)是第二个平面。那么一条有方向的直线可以表示为连接 u v uv uv以及 s t st st平面上任意两点确定的线,如下图所示:
【注】:Levoy3首先利用双平面法对光场进行表示,光线首先通过 u v uv uv平面,然后再通过 s t st st平面。但是后来(同年)Gortler4等人将其传播方向反了过来,导致后续研究者对此表述并不一致。与此同时,也有不少文献中也引入了 x y xy xy坐标,例如著名的光场相机的缔造者N.G.博士的毕业论文。通常情况下,这指的是像平面坐标,即指的是由传感器得到的图像中像素的位置坐标。由于后续处理中都是针对图像而言,而对于光学结构以及光线的传播过程并不感兴趣。所以为了方便起见,我们在本文中统一采用Levoy3的方式对光场图像进行表示,即 u v uv uv表示角度分辨率, x y xy xy表示空间分辨率,即 L ( u , v , x , y ) L(u,v,x,y) L(u,v,x,y)。同时在表示光场时用 L ( u , v , s , t ) L(u,v,s,t) L(u,v,s,t)。有时候二者不做区分,注意即可。
光场的可视化
虽然光场由 7 D 7D 7D全光函数降维到 4 D 4D 4D,但是其结构还是很难直观想象。通过固定4D光场参数化表示 L ( u , v , s , t ) L(u,v,s,t) L(u,v,s,t)中的某些变量,我们可以很容易地对光场进行可视化。我们通常认为 ( u , v ) (u,v) (u,v)控制着某个视角的位置,即相机平面;而 ( s , t ) (s,t) (s,t)控制着从某个视角观察到的图像。说简单点: u v uv uv控制角度分辨率, s t st st控制空间分辨率(视野)。注意上式描述的是光线的表示方法,并没有涉及图像处理,所以没有 x y xy xy。

接下来讲解,几种常见的可视化方式(图片来源5)。首先是多视图法。很容易理解,对于最简单的情况,首先固定KaTeX parse error: Undefined control sequence: \* at position 5: u=u^\̲*̲,v=v^\*,我们可以得到多视角的某个视图KaTeX parse error: Undefined control sequence: \* at position 5: L(u^\̲*̲,v^\*,s,t),如下图所示:
[外链图片转存失败(img-YfPo7qwF-1563614877876)(https://qcloud.coding.net/u/vincentqin/p/blogResource/git/raw/master/light-field-depth-estimation/allviews.png)]
第二种表示方法是角度域法,通过固定KaTeX parse error: Undefined control sequence: \* at position 5: s=s^\̲*̲,t=t^\*可以得到某个宏像素KaTeX parse error: Undefined control sequence: \* at position 9: L(u,v,s^\̲*̲,t^\*),如下图所示:
第三种表示方法是极线图法,通过固定KaTeX parse error: Undefined control sequence: \* at position 5: v=v^\̲*̲,t=t^\*可以得到极线图:KaTeX parse error: Undefined control sequence: \* at position 7: L(u,v^\̲*̲,s,t^\*),如下图中水平方向的图所示;同理固定KaTeX parse error: Undefined control sequence: \* at position 5: u=u^\̲*̲,s=s^\*可以得到极线图:KaTeX parse error: Undefined control sequence: \* at position 5: L(u^\̲*̲,v,s^\*,t),如下图中竖直方向的图所示:
最后,给出这几种方式的对应关系图(注意图中, x y xy xy对应于以上 s t st st, s t st st对应于 u v uv uv)。
光场的获取
我们知道传统的相机只能采集来自场景某个方向的 2 D 2D 2D信息,那怎么才能够采集到光场信息呢?试想一下,当多个相机在多个不同视角同时拍摄时,这样我们就可以得到一个光场的采样(多视角图像)了。当然,这是容易想到的方法,目前已有多种获得光场的方式,如下表格中列举了其中具有代表性的方式5。
光场深度估计算法分类
由上可知,光场图像中包含来自场景的多视角信息,这使得深度估计成为可能。相较于传统的多视角深度估计算法而言,基于光场的深度估计算法无需进行相机标定,这大大简化的深度估计的流程。但是由于光场图像巨大导致了深度估计过程占用大量的计算资源。同时这些所谓的多个视角之间虚拟相机的基线过短,从而可能导致误匹配的问题。以下将对多种深度估计算法进行分类并挑选具有代表性的算法进行介绍。
多视角立体匹配
根据光场相机的成像原理,我们可以将光场图像想像成为多个虚拟相机在多个不同视角拍摄同一场景得到图像的集合,那么此时的深度估计问题就转换成为多视角立体匹配问题。以下列举几种基于多视角立体匹配算法的深度估计算法6 7 8 9 10。

在这里介绍Jeon等人6提出的基于相移的亚像素多视角立体匹配算法。
相移理论
该算法的核心就是用到了相移理论,即空域的一个小的位移在频域为原始信号的频域表达与位移的指数的幂乘积,即如下公式:
F { I ( x + Δ x ) } = F { I ( x ) } exp 2 π j Δ x . (2) \mathcal{F}\left\{I(x+\Delta x)\right\} = \mathcal{F}\left\{I(x)\right\}\exp^{2\pi j\Delta x}. \tag{2} F{I(x+Δx)}=F{I(x)}exp2πjΔx.(2)
所以,经过位移后图像可以表示为:
I ′ ( x ) = I ( x + Δ x ) = F − 1 { F { I ( x ) } exp 2 π j Δ x } , (3) I'(x)=I(x+\Delta x)={\mathcal{F}^{-1}\left\{\mathcal{F}\left\{I(x)\right\}\exp^{2 \pi j \Delta x}\right\}},\tag{3} I′(x)=I(x+Δx)=F−1{F{I(x)}exp2πjΔx},(3)
面对Lytro相机窄基线的难点,通过相移的思想能够实现亚像素精度的匹配,在一定程度上解决了基线短的问题。那么大家可能好奇的是,如何将这个理论用在多视角立体匹配中呢?带着这样的疑问,继续介绍该算法。
匹配代价构建
为了能够使子视角图像之间进行匹配,作者设计了2中不同的代价量:Sum of Absolute Differences (SAD)以及Sum of Gradient Differences (GRAD),最终通过加权的方式获得最终的匹配量 C C C,它是位点 x x x以及损失编号(可以理解成深度/视差层) l l l的函数,具体形式如下公式所示:
C ( x , l ) = α C A ( x , l ) + ( 1 − α ) C G ( x , l ) , (4) C(x,l) = \alpha C_A(x,l)+(1-\alpha)C_G(x,l),\tag{4} C(x,l)=αCA(x,l)+(1−α)CG(x,l),(4)
其中 α ∈ [ 0 , 1 ] \alpha \in [0,1] α∈[0,1]表示SAD损失量 C A C_A CA以及SGD损失量 C G C_G CG之间的权重。同时其中的 C A C_A CA被定义为如下形式:
C A ( x , l ) = ∑ u ∈ V ∑ x ∈ R x min ( ∣ I ( u c , x ) − I ( u , x + Δ x ( u , l ) ) ∣ , τ 1 ) , (5) C_A(x,l) = \sum_{u \in V}\sum_{x \in R_x}{\min\left( | I(u_c,x)-I(u,x+\Delta x(u,l))|,\tau _1\right)},\tag{5} CA(x,l)=u∈V∑x∈Rx∑min(∣I(uc,x)−I(u,x+Δx(u,l))∣,τ1),(5)
其中的 R x R_x Rx表示在 x x x点邻域的矩形区域; τ 1 \tau _1 τ1是代价的截断值(为了增加算法鲁棒性); V V V表示除了中心视角 u c u_c uc之外的其余视角。上述公式通过比较中心视角图像 I ( u c , x ) I(u_c,x) I(uc,x)与其余视角 I ( u , x ) I(u,x) I(u,x)的差异来构建损失量,具体而言就是通过不断地在某个视角 I ( u i , x ) I(u_i,x) I(ui,x)上 x x x点的周围移动一个小的距离并于中心视角做差;重复这个过程直到比较完所有的视角(i=1…视角数目N)为止。此时会用到上节提及的相移理论以得到移动后的像素强度,注意上面提到的小的距离实际上就是公式中的 Δ x \Delta x Δx,它被定义为如下形式:
Δ x ( u , l ) = l k ( u − u c ) , (6) \Delta x(u,l) = lk(u-u_c),\tag{6} Δx(u,l)=lk(u−uc),(6)
其中k表示深度/视差层的单位(像素), Δ x \Delta x Δx会随着任意视角与中心视角之间距离的增大而线性增加。同理,可以构造出第二个匹配代价量SGD,其基本形式如下所示:
C G ( x , l ) = ∑ u ∈ V ∑ x ∈ R x β ( u ) min ( D i f f x ( u c , u , x , l ) , τ 2 ) + ( 1 − β ( u ) ) min ( D i f f y ( u c , u , x , l ) , τ 2 ) , (7) C_G(x,l) = \sum_{u \in V}\sum_{x \in R_x}\beta (u){\min\left( Diff_x(u_c,u,x,l),\tau _2\right)}+ \\ \ \ \ (1-\beta (u)){\min\left( Diff_y(u_c,u,x,l),\tau _2\right)},\tag{7} CG(x,l)=u∈V∑x∈Rx∑β(u)min(Diffx(uc,u,x,l),τ2)+ (1−β(u))min(Diffy(uc,u,x,l),τ2),(7)
其中的 D i f f x ( u c , u , x , l ) = ∣ I x ( u c , x ) − I x ( u , x + Δ x ( u , l ) ) ∣ Diff_x(u_c,u,x,l)=|I_x(u_c,x)-I_x(u,x+\Delta x(u,l))| Diffx(uc,u,x,l)=∣Ix(uc,x)−Ix(u,x+Δx(u,l))∣表示子视角图像在x方向的上的梯度,同理 D i f f y Diff_y Diffy表示子孔径图像在y方向上的梯度; β ( u ) \beta (u) β(u)控制着这两个方向代价量的权重,它由任意视角与中心视角之间的相对距离表示:
β ( u ) = ∣ u − u c ∣ ∣ u − u c ∣ + ∣ v − v c ∣ . (8) \beta (u) = \frac{|u-u_c|}{|u-u_c|+|v-v_c|}.\tag{8} β(u)=∣u−uc∣+∣v−vc∣∣u−uc∣.(8)
至此,代价函数构建完毕。随后对于该代价函数利用边缘保持滤波器进行损失聚合,得到优化后的代价量。紧接着作者建立了一个多标签优化模型(GC求解)以及迭代优化模型对深度图进行优化,再此不做详细介绍。下面是其算法的分部结果:
基于EPI的方法

不同于多视角立体匹配的方式,EPI的方式是通过分析光场数据结构的从而进行深度估计的方式。EPI图像中斜线的斜率就能够反映出场景的深度。上图中点P为空间点,平面 Π \Pi Π为相机平面,平面 Ω \Omega Ω为像平面。图中 Δ u \Delta u Δu与 Δ x \Delta x Δx的关系可以表示为如下公式11:
Δ x = − f Z Δ u , (9) \Delta x=- \frac{f}{Z}\Delta u,\tag{9} Δx=−ZfΔu,(9)
假如固定相同的 Δ u \Delta u Δu,水平方向位移较大的EPI图中斜线所对应的视差就越大,即深度就越小。如下图所示, Δ x 2 \Delta x_2 Δx2> Δ x 1 \Delta x_1 Δx1,那么绿色线所对应的空间点要比红色线所对应的空间点深度小。

以下列举几种基于EPI的深度估计算法12 13 14 15 16 17。
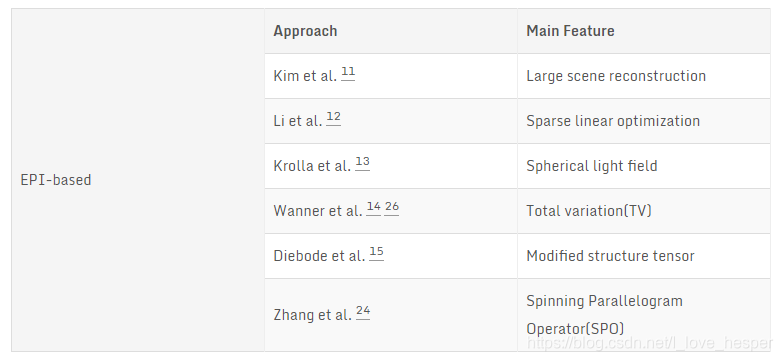
在以上表格中最具代表性的算法是由wanner15提出的结构张量法得到EPI图中线的斜率,如下公式所示:
J = [ G σ ∗ ( S x S x ) G σ ∗ ( S x S y ) G σ ∗ ( S x S y ) G σ ∗ ( S y S y ) ] = [ J x x J x y J x y J y y ] , (10) J= \left[ \begin{matrix} G_{\sigma}*(S_xS_x) & G_{\sigma}*(S_xS_y) \\ G_{\sigma}*(S_xS_y) & G_{\sigma}*(S_yS_y) \end{matrix} \right]= \left[ \begin{matrix} J_{xx} & J_{xy}\\ J_{xy} & J_{yy} \end{matrix} \right], \tag{10} J=[Gσ∗(SxSx)Gσ∗(SxSy)Gσ∗(SxSy)Gσ∗(SySy)]=[JxxJxyJxyJyy],(10)
其中KaTeX parse error: Undefined control sequence: \* at position 8: S=S_{y^\̲*̲,v^\*}为极线图。
S
x
S_x
Sx以及
S
y
S_y
Sy表示极线图在x以及y方向上的梯度,
G
σ
G_{\sigma}
Gσ表示高斯平滑算子。最终极线图中局部斜线的斜率可以表示成如下形式:
J
=
[
Δ
x
Δ
v
]
=
[
sin
φ
cos
φ
]
,
(11)
J=\left[ \begin{matrix} \Delta x \\ \Delta v \end{matrix} \right]= \left[ \begin{matrix} \sin \varphi\\ \cos \varphi \end{matrix} \right], \tag{11}
J=[ΔxΔv]=[sinφcosφ],(11)
其中
φ
=
1
2
arctan
(
J
y
y
−
J
x
x
2
J
x
y
)
\varphi = \frac{1}{2}\arctan\left(\frac{J_{yy}-J_{xx}}{2J_{xy}}\right)
φ=21arctan(2JxyJyy−Jxx)。因此深度可以由公式(9)推出:
Z = − f Δ v Δ x , (12) Z=-f\frac{\Delta v}{\Delta x}, \tag{12} Z=−fΔxΔv,(12)
通常情况下,可以用一种更加简单的形式,如视差对其进行表示:
d y ∗ , v ∗ = − f / Z = Δ x Δ v = tan ϕ . (13) d_{y^*,v^*}=-f/Z=\frac{\Delta x}{\Delta v}=\tan \phi . \tag{13} dy∗,v∗=−f/Z=ΔvΔx=tanϕ.(13)
至此,利用上述公式可以从EPI中估计出视差。
散焦及融合的方法
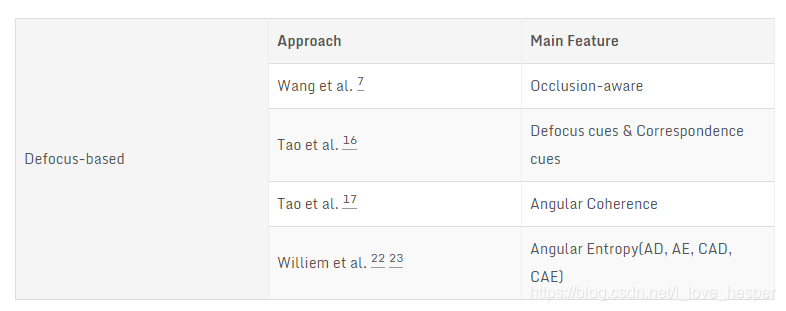
光场相机一个很重要的卖点是先拍照后对焦,这其实是根据光场剪切原理18得到的。通过衡量像素在不同焦栈处的“模糊度”可以得到其对应的深度。以下列举几种基于散焦的深度估计算法19 20 21 22 23。
这里介绍一个最具代表性的工作,由Tao等人20在2013年提出,下图为其算法框架以及分部结果。
该工作其实就做了2件事情:1. 设计两种深度线索并估计原始深度;2. 置信度分析及MRF融合。以下对其进行具体介绍。
双线索提取
首先对光场图像进行重聚焦,然后得到一系列具有不同深度的焦栈。然后对该焦栈分别提取2个线索:散焦量以及匹配量。其中散焦量被定义为:
D α ( x ) = 1 ∣ W D ∣ ∑ x ′ ∈ W D ∣ Δ x L α ( x ′ ) ∣ , (14) D_{\alpha}(x)=\frac{1}{|W_{D}|}{\sum _{x' \in W_D} {|\Delta _x{L}_{\alpha}(x')|}},\tag{14} Dα(x)=∣WD∣1x′∈WD∑∣ΔxLα(x′)∣,(14)
其中, W D W_D WD表示为当前像素领域窗口大小, Δ x \Delta _x Δx表示水平方向拉式算子, L ‾ α ( x ) \overline{L}_{\alpha}(x) Lα(x)为每个经过平均化后的重聚焦后光场图像,其表达式如下:
L ‾ α ( x ) = 1 N u ∑ u ′ L α ( x , u ′ ) , (15) \overline{L}_{\alpha}(x)=\frac{1}{N_{u}}\sum _{u'} {L}_{\alpha}(x,u'),\tag{15} Lα(x)=Nu1u′∑Lα(x,u′),(15)
其中 N u N_{u} Nu表示每一个角度域内像素的数目。然后匹配量被定义成如下形式:
C α ( x ) = 1 ∣ W C ∣ ∑ x ′ ∈ W C σ α ( x ′ ) , (16) {C}_{\alpha}(x)=\frac{1}{|W_{C}|}\sum _{x' \in W_C} {\sigma}_{\alpha}(x'),\tag{16} Cα(x)=∣WC∣1x′∈WC∑σα(x′),(16)
其中, W C W_C WC表示为当前像素领域窗口大小, σ α ( x ) {\sigma}_{\alpha}(x) σα(x)表示每个宏像素强度的标准差,其表达式为:
σ α ( x ) 2 = 1 N u ∑ u ′ ( L α ( x , u ′ ) − L ‾ α ( x ) ) 2 . (17) {\sigma}_{\alpha}(x)^2=\frac{1}{N_{u}}\sum _{u'} \left({L}_{\alpha}(x,u')-\overline{L}_{\alpha}(x)\right)^2.\tag{17} σα(x)2=Nu1u′∑(Lα(x,u′)−Lα(x))2.(17)
经过以上两个线索可以通过赢者通吃(Winner Takes All,WTA)得到两张原始深度图。注意:对这两个线索使用WTA时略有不同,通过最大化空间对比度可以得到散焦线索对应的深度,最小化角度域方差能够获得匹配量对应的深度。因此二者深度可以分别表示为如下公式:
α D ∗ ( x ) = arg max α D α ( x ) . (18) \alpha ^{*}_D(x)=\mathop{\arg\max}_{\alpha} \ \ {D}_{\alpha}(x).\tag{18} αD∗(x)=argmaxα Dα(x).(18)
α C ∗ ( x ) = arg min α C α ( x ) . (19) \alpha ^{*}_C(x)=\mathop{\arg\min}_{\alpha} \ \ {C}_{\alpha}(x).\tag{19} αC∗(x)=argminα Cα(x).(19)
置信度分析及深度融合
上图中显示了两个线索随着深度层次而变化的曲线。接下来的置信度分析用主次峰值比例(Peak Ratio)来定义每种线索的置信度,可表示为如下公式,其中的 α D ∗ 2 ( x ) \alpha_{D}^{* 2}(x) αD∗2(x)以及 α C ∗ 2 ( x ) \alpha_{C}^{* 2}(x) αC∗2(x)分别表示曲线的次峰值对应的深度层次。
D c o n f ( x ) = D α D ∗ ( x ) D α D ∗ 2 ( x ) . (20) D_{conf}(x)=\frac{D_{\alpha ^{*}_D}(x)}{D_{\alpha ^{*2}_D}(x)}.\tag{20} Dconf(x)=DαD∗2(x)DαD∗(x).(20)
C c o n f ( x ) = C α C ∗ ( x ) C α C ∗ 2 ( x ) . (21) C_{conf}(x)=\frac{C_{\alpha ^{*}_C}(x)}{C_{\alpha ^{*2}_C}(x)}.\tag{21} Cconf(x)=CαC∗2(x)CαC∗(x).(21)
接下来对原始深度进行MRF置信度融合:
m i n i m i z e Z ∑ s o u r c e λ s o u r c e ∑ i W i ∣ Z i − Z i s o u r c e ∣ \mathop{minimize}_{Z} \ \ \sum_{source}\lambda _{source} \sum _i W_i|Z_i-Z_i^{source}| minimizeZ source∑λsourcei∑Wi∣Zi−Zisource∣
+ λ f l a t ∑ ( x , y ) ( ∣ ∂ Z i ∂ x ∣ ( x , y ) + ∣ ∂ Z i ∂ y ∣ ( x , y ) ) + λ s m o o t h ∑ ( x , y ) ∣ Δ Z i ∣ ( x , y ) . (22) +\lambda _{flat} \sum _{(x,y)}\left( \left |\frac{\partial Z_i}{\partial x}\right|_{(x,y)}+\left|\frac{\partial Z_i}{\partial y}\right|_{(x,y)}\right) + \lambda _{smooth} \sum _{(x,y)}|\Delta Z_i|_{(x,y)}.\tag{22} +λflat(x,y)∑(∣∣∣∣∂x∂Zi∣∣∣∣(x,y)+∣∣∣∣∂y∂Zi∣∣∣∣(x,y))+λsmooth(x,y)∑∣ΔZi∣(x,y).(22)
其中, s o u r c e source source控制着数据项,即优化后的深度要与原始深度尽量保持一致。第二项与第三项分别控制着平坦性(flatness)与平滑性(smoothness)。注意:平坦的意思是物体表面没有凹凸变化的沟壑,例如魔方任一侧面,无论是否拼好(忽略中间黑线)。而平滑则表示在平坦的基础上物体表面没有花纹,如拼好的魔方的一个侧面。另外的 W W W是权重量,此处选用的是每个线索的置信度。
{ Z 1 s o u r c e , Z 2 s o u r c e } = { α C ∗ , α D ∗ } . (23) \{Z_1^{source},Z_2^{source}\}=\{\alpha_C^{*},\alpha_D^{*}\}.\tag{23} {Z1source,Z2source}={αC∗,αD∗}.(23)
{ W 1 s o u r c e , W 2 s o u r c e } = { C c o n f , D c o n f } . (24) \{W_1^{source},W_2^{source}\}=\{C_{conf},D_{conf}\}.\tag{24} {W1source,W2source}={Cconf,Dconf}.(24)
至此,该算法介绍完毕,其代码已经放在我的Github。
学习的方法
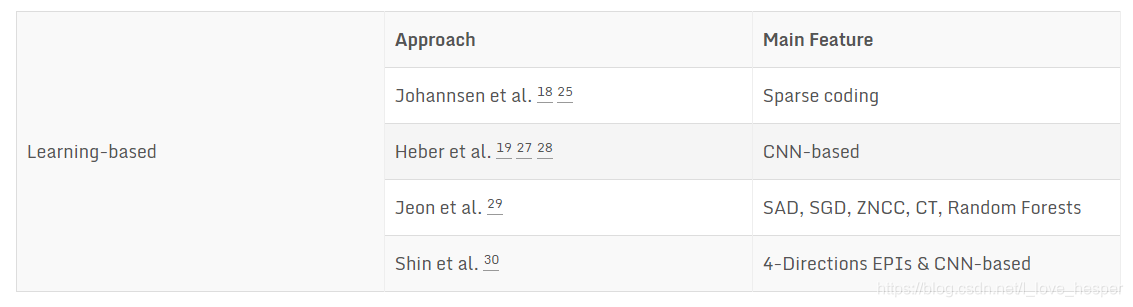
目前而言,将深度学习应用于从双目或者单目中恢复深度已经不再新鲜,我在之前的博文1&博文2中有过对这类算法的介绍。但是将其应用于光场领域进行深度估计的算法还真是寥寥无几。不过总有一些勇敢的践行者去探索如何将二者结合,以下列举几种基于学习的深度估计算法24 25 26 27 28 29 30。
在此,我将对截止目前(2018年5月29日)而言,在HCI新数据集上表现最好的EPINET: A Fully-Convolutional Neural Network Using Epipolar Geometry for Depth from Light Field Images30算法进行介绍,下图为该算法在各个指标上的表现情况。
算法摘要:光场相机能够同时采集空间光线的空域以及角度域信息,因此可以根据这种特性恢复出空间场景的涉深度。在本文中,作者提出了一种基于CNN的快速准确的光场深度估计算法。作者在设计网络时将光场的几何结构加入考虑,同时提出了一种新的数据增强算法以克服训练数据不足的缺陷。作者提出的算法能够在HCI 4D-LFB上在多个指标上取得Top1的成绩。作者指出,光场相机存在优势的同时也有诸多缺点,例如:基线超级短且空间&角度分辨率有一定的权衡关系。目前已有很多工作去克服这些问题,这样一来,深度图像的精度提升了,但是带来的后果就是计算量超级大,无法快速地估计出深度。因此作者为了解决精度以及速度之间权衡关系设计了该算法(感觉很有意义吧)。
上面表格中提到的诸如Johannsen24 26以及Heber25 27 28等人设计的算法仅仅考虑到了一个极线方向,从而容易导致低置信度的深度估计。为了解决他们算法中存在的问题,作者通过一种多流网络将不同的极线图像分别进行编码去预测深度。因为,每个极线图都有属于自己的集合特征,将这些极线图放入网络训练能够充分地利用其提供的信息。
光场图像几何特征
由于光场图像可以等效成多个视角图像的集合,这里的视角数目通常要比传统的立体匹配算法需要的视角数目多得多。所以,如果利用全部的视角做深度估计将会相当耗时,所以在实际情况下并不需要用到全部的视角。作者的思路就是想办法尽量减少实际要使用的视角数目,所以作者探究了不同角度域方向光场图像的特征。中心视角图像与其余视角的关系可以表示成如下公式:
L ( x , y , 0 , 0 ) = L ( x + d ( x , y ) ∗ u , y + d ( x , y ) ∗ v , u , v ) , (25) L(x,y,0,0)=L(x+d(x,y)*u,y+d(x,y)*v,u,v),\tag{25} L(x,y,0,0)=L(x+d(x,y)∗u,y+d(x,y)∗v,u,v),(25)
其中 d ( x , y ) d(x,y) d(x,y)表示中心视角到其相应相邻视角之间的视差(disparity)。令角度方向为 θ \theta θ( tan θ = v / u \tan \theta=v/u tanθ=v/u),我们可以将上式改写成如下公式:
L ( x , y , 0 , 0 ) = L ( x + d ( x , y ) ∗ u , y + d ( x , y ) ∗ u tan θ , u , u tan θ ) . (26) L(x,y,0,0)=L(x+d(x,y)*u,y+d(x,y)*u \tan \theta,u,u \tan \theta).\tag{26} L(x,y,0,0)=L(x+d(x,y)∗u,y+d(x,y)∗utanθ,u,utanθ).(26)
作者选择了四个方向 θ \theta θ: 0o,45o,90o,135o,同时假设光场图像总视角数为 ( 2 N + 1 ) × ( 2 N + 1 ) (2N+1)\times(2N+1) (2N+1)×(2N+1)。
网络设计
如本节开始的图所示的网络结构,该网络的开始为多路编码网络(类似于Flownet以及Efficient Deep Learning for Stereo Matching31),其输入为4个不同方向视角图像集合,每个方向对应于一路网络,每一路都可以对其对应方向上图像进行编码提取特征。每一路网络都由3个全卷积模块组成,因为全卷积层对逐点稠密预测问题卓有成效,所以作者将每一个全卷积模块定义为这样的卷积层的集合:Conv-ReLU-Conv-BN-ReLU,这样的话就可以在局部块中预逐点预测视差。为了解决基线短的问题,作者设计了非常小的卷积核: 2 × 2 2\times 2 2×2,同时stride = 1,这样的话就可以测量 ± 4 \pm 4 ±4的视差。为了验证这种多路网络的有效性,作者同单路的网络做了对比试验,其结果如下表所示,可见多路网络相对于单路网络有10%的误差降低。

在完成多路编码之后,网络将这些特征串联起来组成更维度更高的特征。后面的融合网络包含8个卷积块,其目的是寻找经多路编码之后特征之间的相关性。注意除了最后一个卷积块之外,其余的卷积块全部相同。为了推断得到亚像素精度的视差图,作者将最后一个卷积块设计为Conv-ReLU-Conv结构。
最后,图像增强方式包括视角偏移(从9*9视角中选7*7,可扩展3*3倍数据),图像旋转(90o,180o,270o),图像缩放([0.25,1]),色彩值域变化([0.5,2]),随机灰度变化,gamma变换([0.8,1.2])以及翻转,最终扩充了288倍。
以下为其各个指标上的性能表现:
以上介绍了目前已有的深度估计算法不同类别中具有代表性的算法,它们不一定是最优的,但绝对是最容易理解其精髓的。到目前为止,光场领域已经有一大波人做深度估计的工作,利用传统的方式其精度很难再往上提高。随着深度学习的大热,已经有一批先驱开始用深度学习做深度估计,虽然在仿真数据上可以表现得很好,但实际场景千变万化,即使是深度学习的策略也不敢保证对所有的场景都有效。路漫漫其修远兮,深度估计道路阻且长。我认为以后的趋势应该是从EPI图像下手,然后利用CNN提feature(或者响应);此时可供选择的工具有KITTI Stereo/HCI新数据集算法比较/Middlebury Stereo中较好的几种算法,我们需要总结其算法优势并迁移到光场领域中来。GPU这个Powerful的计算工具一定要用到光场领域中来,发挥出多线程的优势。否则传统的CPU对于动辄上百兆的数据有心无力。这样一来,深度图像不仅仅可以从精度上得以提高,而且深度估计的速度也会更快。至此,本文介绍到此结束。
欢迎大家关注我的公众号,最新文章第一时间推送。

References
Gershun, A. “The Light Field.” Studies in Applied Mathematics 18.1-4(1939):51–151. ↩︎
Adelson, Edward H, and J. R. Bergen. "The plenoptic function and the elements of early vision. " Computational Models of Visual Processing (1991):3-20. ↩︎
Levoy, Marc. “Light field rendering.” Conference on Computer Graphics and Interactive Techniques ACM, 1996:31-42. ↩︎ ↩︎ ↩︎ ↩︎
Gortler, Steven J., et al. “The Lumigraph.” Proc Siggraph 96(1996):43-54. ↩︎
Wu, Gaochang, et al. “Light Field Image Processing: An Overview.” IEEE Journal of Selected Topics in Signal Processing PP.99(2017):1-1. ↩︎ ↩︎
Jeon, Hae Gon, et al. “Accurate depth map estimation from a lenslet light field camera.” Computer Vision and Pattern Recognition IEEE, 2015:1547-1555. ↩︎ ↩︎
Yu, Zhan, et al. “Line Assisted Light Field Triangulation and Stereo Matching.” IEEE International Conference on Computer Vision IEEE, 2014:2792-2799. ↩︎
Heber, Stefan, and T. Pock. “Shape from Light Field Meets Robust PCA.” Computer Vision – ECCV 2014. 2014:751-767. ↩︎
Heber, Stefan, R. Ranftl, and T. Pock. “Variational Shape from Light Field.” Energy Minimization Methods in Computer Vision and Pattern Recognition. Springer Berlin Heidelberg, 2013:66-79. ↩︎
Chen, Can, et al. “Light Field Stereo Matching Using Bilateral Statistics of Surface Cameras.” IEEE Conference on Computer Vision and Pattern Recognition IEEE Computer Society, 2014:1518-1525. ↩︎
Wanner, Sven, and B. Goldluecke. “Variational Light Field Analysis for Disparity Estimation and Super-Resolution.” IEEE Transactions on Pattern Analysis & Machine Intelligence 36.3(2013):1. ↩︎
Kim, Changil, et al. “Scene reconstruction from high spatio-angular resolution light fields.” Acm Transactions on Graphics 32.4(2017):1-12. ↩︎
Li, J., M. Lu, and Z. N. Li. “Continuous Depth Map Reconstruction From Light Fields.” IEEE Transactions on Image Processing A Publication of the IEEE Signal Processing Society 24.11(2015):3257. ↩︎
Krolla, Bernd, et al. “Spherical Light Fields.” British Machine Vision Conference 2014. ↩︎
Wanner, Sven, C. Straehle, and B. Goldluecke. “Globally Consistent Multi-label Assignment on the Ray Space of 4D Light Fields.” IEEE Conference on Computer Vision and Pattern Recognition IEEE Computer Society, 2013:1011-1018. ↩︎ ↩︎
Diebold, Maximilian, B. Jahne, and A. Gatto. “Heterogeneous Light Fields.” Computer Vision and Pattern Recognition IEEE, 2016:1745-1753. ↩︎
Zhang S, Sheng H, Li C, et al. “Robust depth estimation for light field via spinning parallelogram operator.” Computer Vision and Image Understanding, 2016, 145:148-159. ↩︎
Ng, Ren. “Digital light field photography.” 2006, 115(3):38-39. ↩︎
Wang, Ting Chun, A. A. Efros, and R. Ramamoorthi. “Occlusion-Aware Depth Estimation Using Light-Field Cameras.” IEEE International Conference on Computer Vision IEEE, 2016:3487-3495. ↩︎
Tao, M. W, et al. “Depth from Combining Defocus and Correspondence Using Light-Field Cameras.” IEEE International Conference on Computer Vision IEEE Computer Society, 2013:673-680. ↩︎ ↩︎
Tao, Michael W., et al. “Depth from shading, defocus, and correspondence using light-field angular coherence.” Computer Vision and Pattern Recognition IEEE, 2015:1940-1948. ↩︎
Williem W, Kyu P I. “Robust light field depth estimation for noisy scene with occlusion.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016:4396-4404. ↩︎
Williem W, Park I K, Lee K M. “Robust light field depth estimation using occlusion-noise aware data costs.” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2017(99):1-1. ↩︎
Johannsen, Ole, A. Sulc, and B. Goldluecke. “Variational Separation of Light Field Layers.” (2015). ↩︎ ↩︎
Heber, Stefan, and T. Pock. “Convolutional Networks for Shape from Light Field.” Computer Vision and Pattern Recognition IEEE, 2016:3746-3754. ↩︎ ↩︎
Johannsen O, Sulc A, Goldluecke B. “What sparse light field coding reveals about scene structure.” In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016(1/3/4):3262-3270. ↩︎ ↩︎
Heber S, Yu W, Pock T. “U-shaped networks for shape from light field.” British Machine Vision Conference, 2016, 37:1-12. ↩︎ ↩︎
Heber S, Yu W, Pock T. “Neural EPI-Volume networks for shape from light field.” IEEE International Conference on Computer Vision (ICCV), IEEE Computer Society, 2017:2271-2279. ↩︎ ↩︎
Jeon H G, Park J, Choe G, et.al. “Depth from a Light Field Image with Learning-based Matching Costs.” IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2018. ↩︎
Shin C, Jeon H G, Yoon Y. “EPINET: A Fully-Convolutional Neural Network for Light Field Depth Estimation Using Epipolar Geometry.” Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018. ↩︎ ↩︎
Luo, Wenjie, A. G. Schwing, and R. Urtasun. “Efficient Deep Learning for Stereo Matching.” IEEE Conference on Computer Vision and Pattern Recognition IEEE Computer Society, 2016:5695-5703. ↩︎














 2309
2309











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









