









基于词项和基于全文的搜索
基于Term的查询
Term 是表达语义的最小单位。搜索和利用统计语言模型进行自然语言处理都需要处理Term
特点
- Term Level Query: Term Query / Range Query / Exists Query / Prefix Query / Wildcard Query
- 在ES中,Term 查询,对输入不会进行分词处理,直接将输入做为一个整体在倒排索引中查找准确的词项,并且使用相关度算分公司为每个包含该词项的文档进行相关度算分(相关度算分会影响查找性能)
- 可以通过Constant Score 将查询转换为一个Filtering,来避免算分,并利用缓存,提高性能
demo

创建索引
//创建索引
PUT /products
{
"mappings":{
"properties":{
"productID" : {
"type":"text",
"fields": {
"keyword":{
"type":"keyword",
"ignore_above":"256"
}
}
},
"desc" : {
"type":"text",
"fields": {
"keyword":{
"type":"keyword",
"ignore_above":"256"
}
}
}
}
}
}
//插入数据
POST /products/_bulk
{"index": {"_id": 1}}
{"productID" : "XHDK-A-1293-#fJ3", "desc":"iPhone"}
{"index": {"_id": 2}}
{"productID" : "KDKE-B-9947-#kL5", "desc":"iPad"}
{"index": {"_id": 3}}
{"productID" : "JODL-X-1293-#pV7", "desc":"MBP"}
第一个查询demo
//1
POST /products/_search
{
"query": {
"term": {
"desc": {
"value": "iPhone"
}
}
}
}
//2
POST /products/_search
{
"query": {
"term": {
"desc": {
"value": "iphone"
}
}
}
}
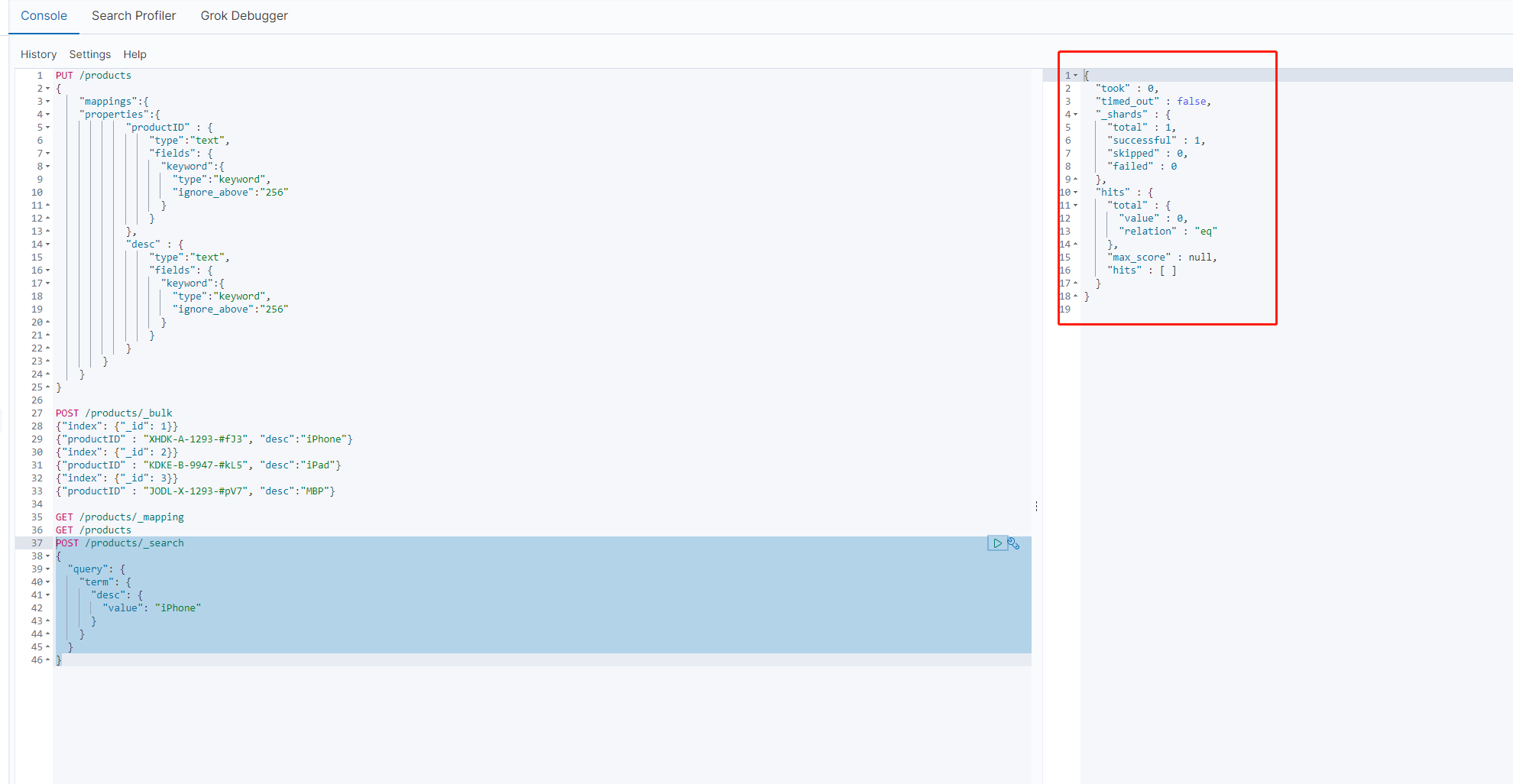
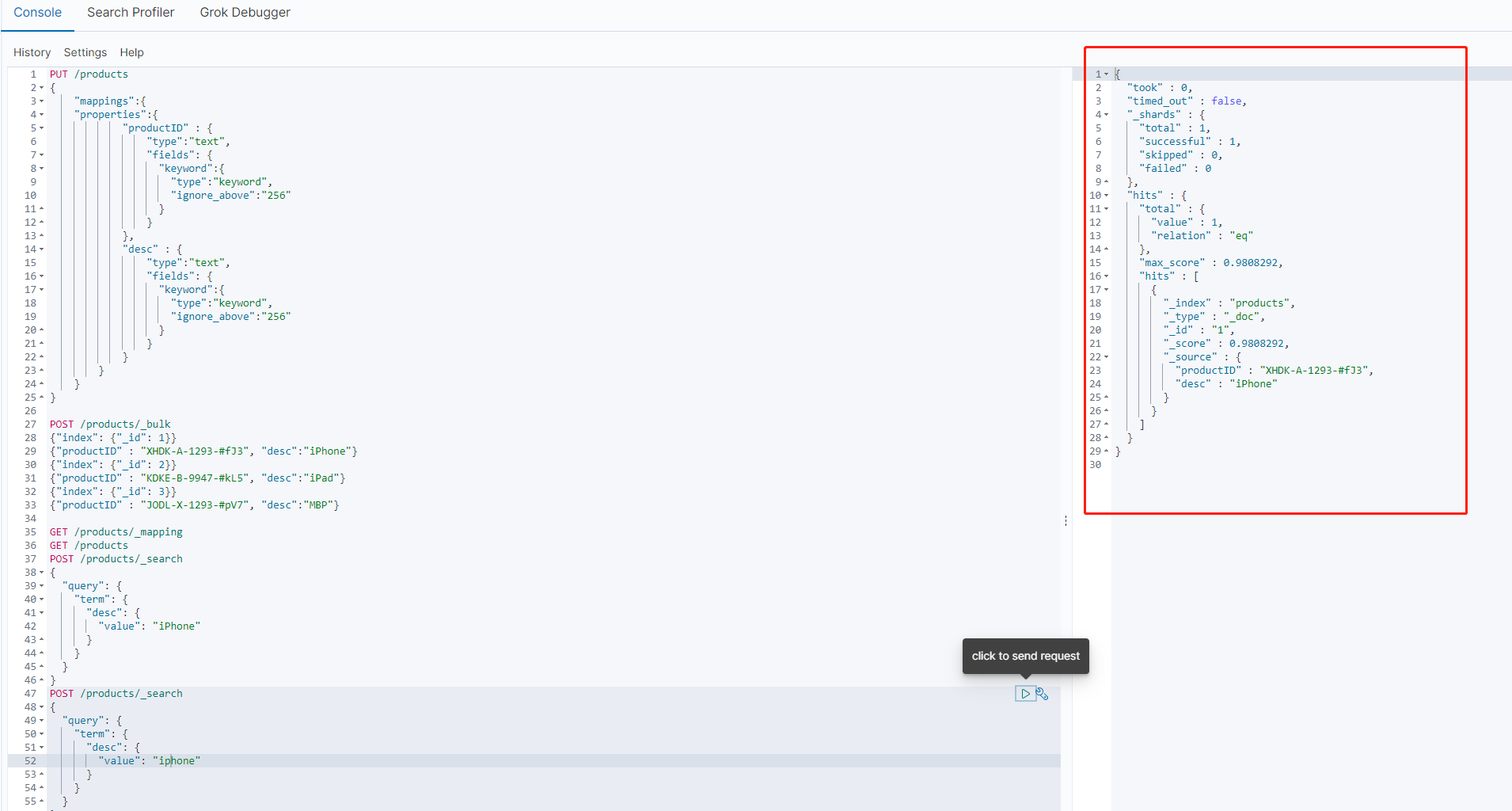
可以看到,第一种,大写的iPhone并没有查询到结果,而小写的iphone有查询结果
这是因为,term查询的时候,将关键词看作为一个整体,并不会对其进行分词,而我们的索引种,desc是text类型的,es在为其构建倒排索引时,会进行分词处理,大写转换为小写。所以 小写的iphone是有结果的。而大写的是没有结果的。
第二种查询demo
//1
POST /products/_search
{
"query": {
"term": {
"productID": {
"value": "XHDK-A-1293-#fJ3"
}
}
}
}
//2
POST /products/_search
{
"query": {
"term": {
"productID": {
"value": "xhdk-a-1293-#fj3"
}
}
}
}
//3
POST /products/_search
{
"query": {
"term": {
"productID": {
"value": "xhdk"
}
}
}
}
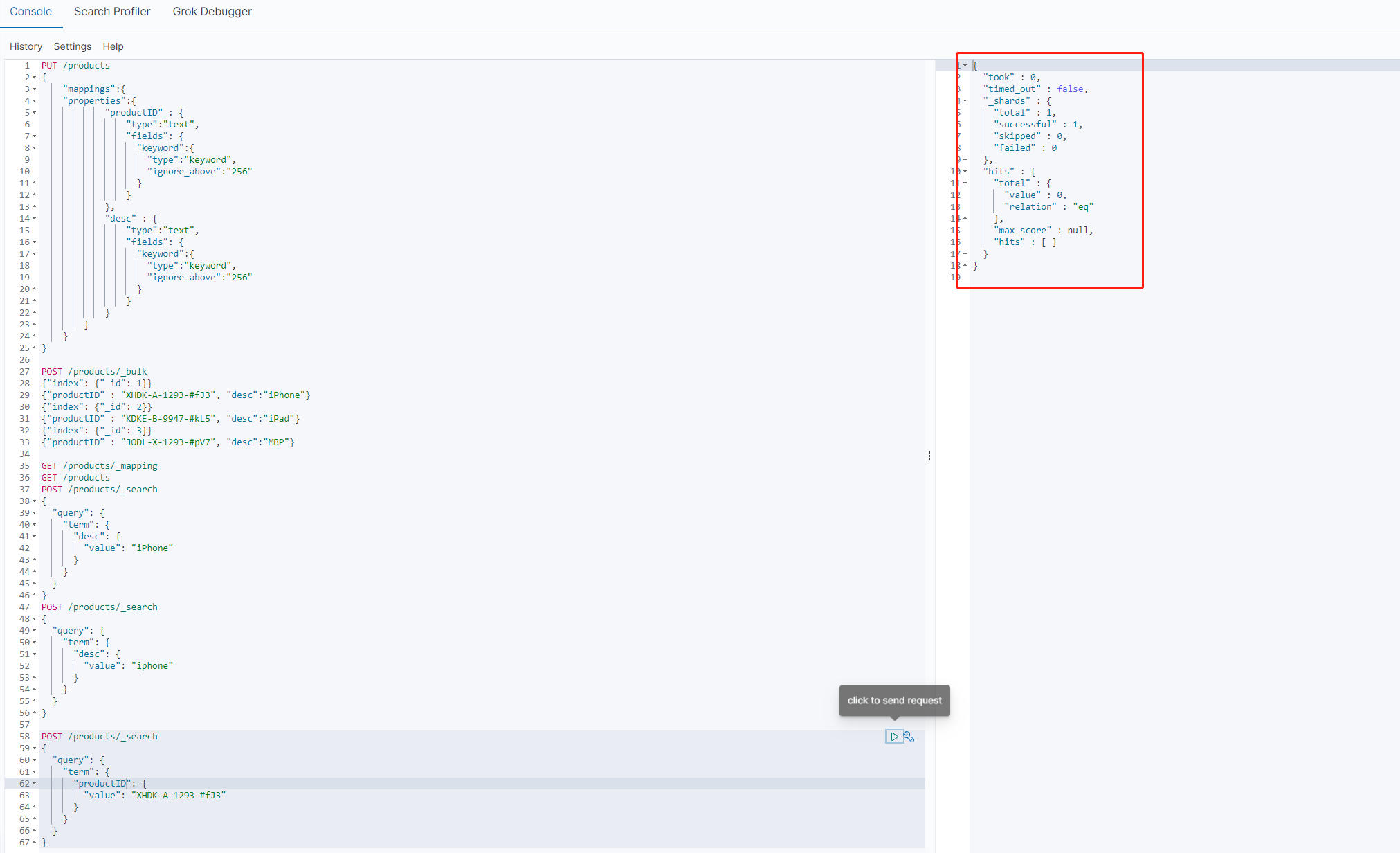
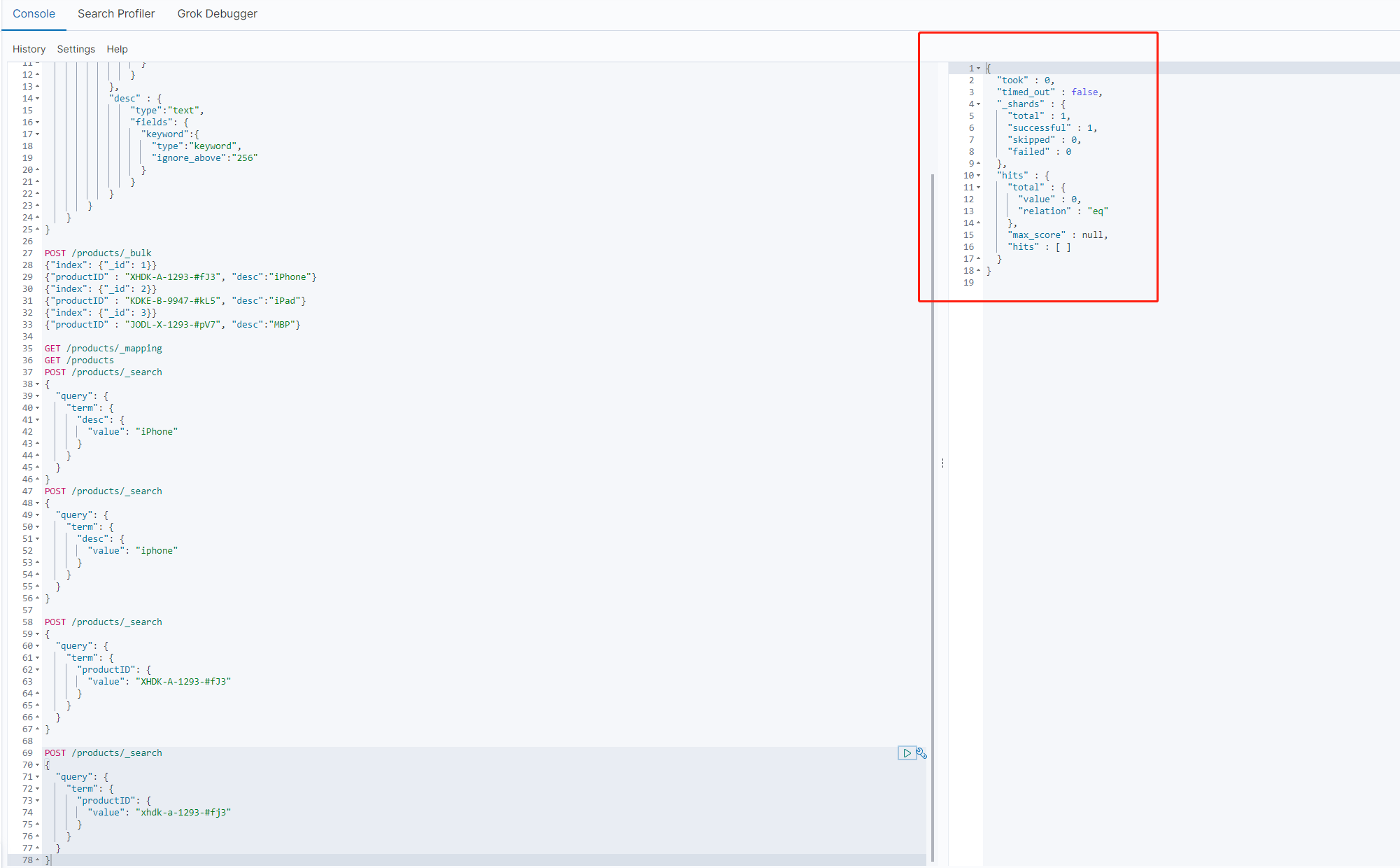
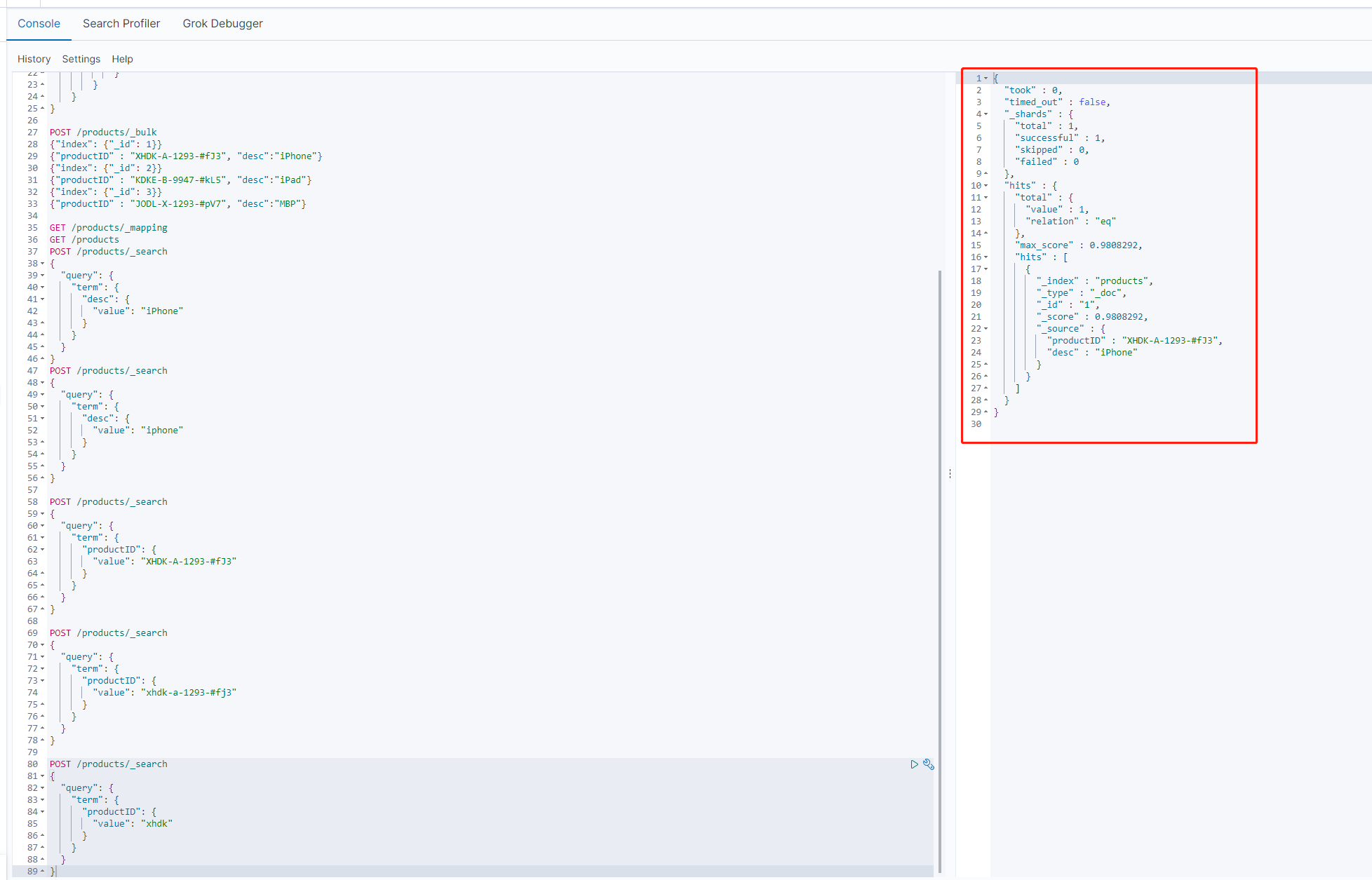
从上面三个图中可以看出,在使用productID 进行查询的时候,无论的完整的Id还是全部都是小写的id,都是查询不到结果的,反而是局部匹配的xhdk查询到了正确的结果
这个还是因为分词的缘故,因为es在构建倒排索引时会进行分词,而从下图中可以看到,es的标准分词器,会将分割符 “-”去掉,剩下的部分分别看作一个词 。而我们查询时使用的时term查询(term查询不会分词),所以匹配不到对应的倒排索引数据。
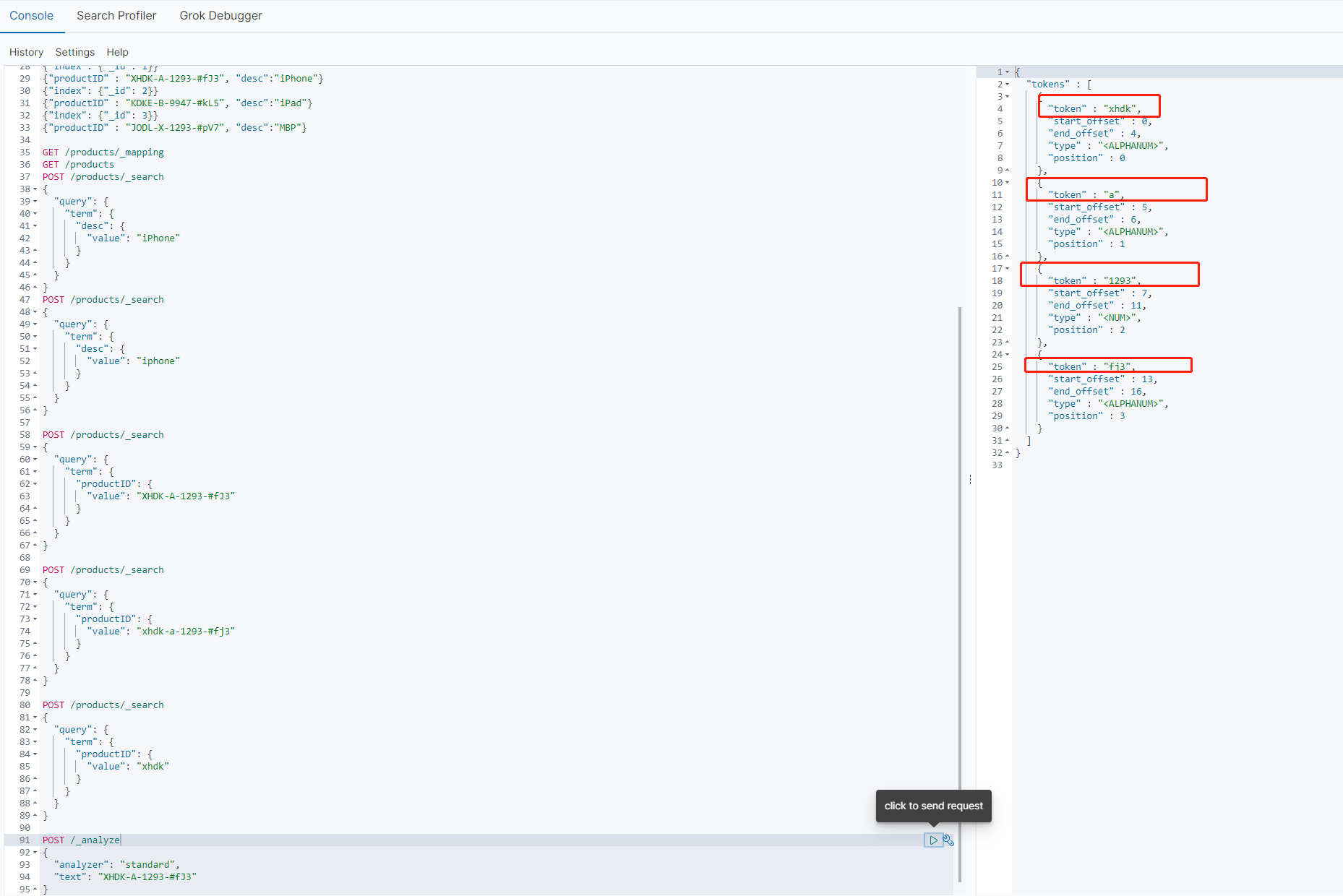
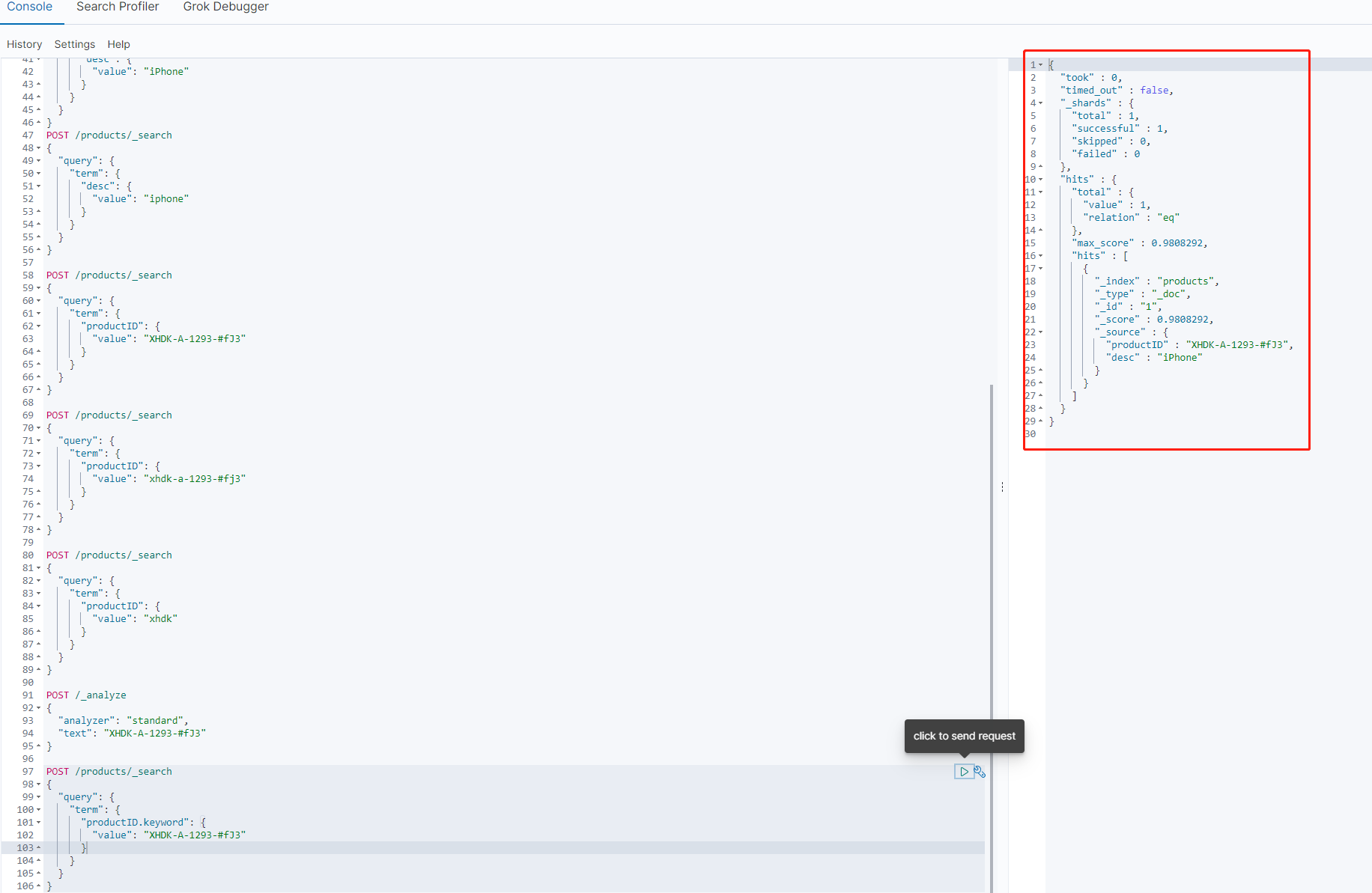
如果一定要用id全文去匹配结果,那么可以使用keyword,因为我们在创建索引时使用多字段mapping子类型给字段productID和desc都配置了一个keyword类型(参考这里)
演示
POST /products/_search
{
"query": {
"term": {
"productID.keyword": {
"value": "XHDK-A-1293-#fJ3"
}
}
}
}
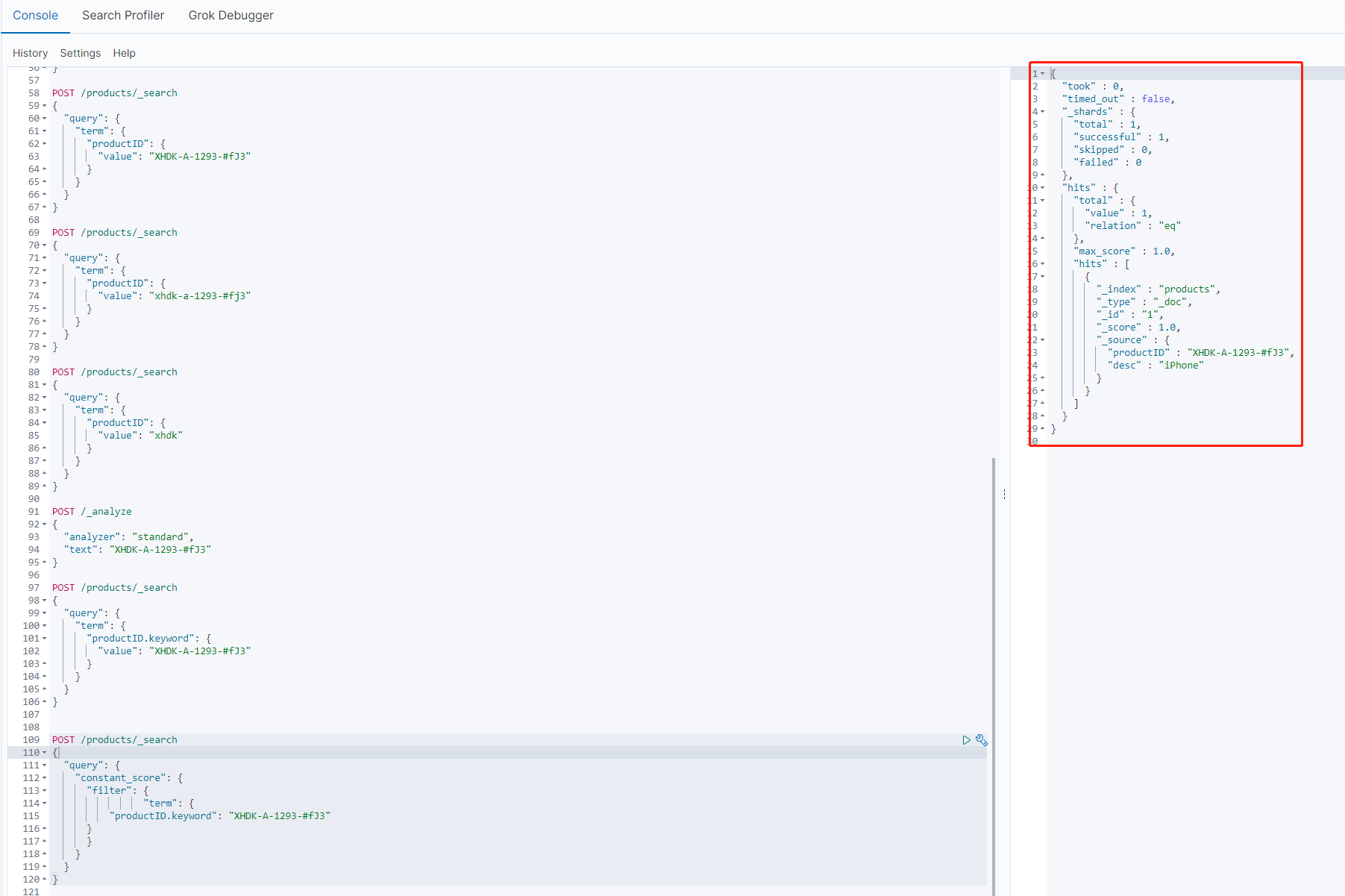
利用Constant Score 转为Filter 进行查询
POST /products/_search
{
"query": {
"constant_score": {
"filter": {
"term": {
"productID.keyword": "XHDK-A-1293-#fJ3"
}
}
}
}
}
基于全文的查询
特点
- Match Query / Match Phrase Query / Query String Query
- 索引和搜素时都会进行分词,查询字符串先传递到一个合适的分词器,然后生成一个供查询的词项列表
- 查询的时候,先会对输入的查询进行分词,然后每次词项诸葛进行底层的查询,最终将结果进行合并。并未每个文档生成一个算分。
Match Query 查询过程
以 输入 “Matrix reloaded” 为例
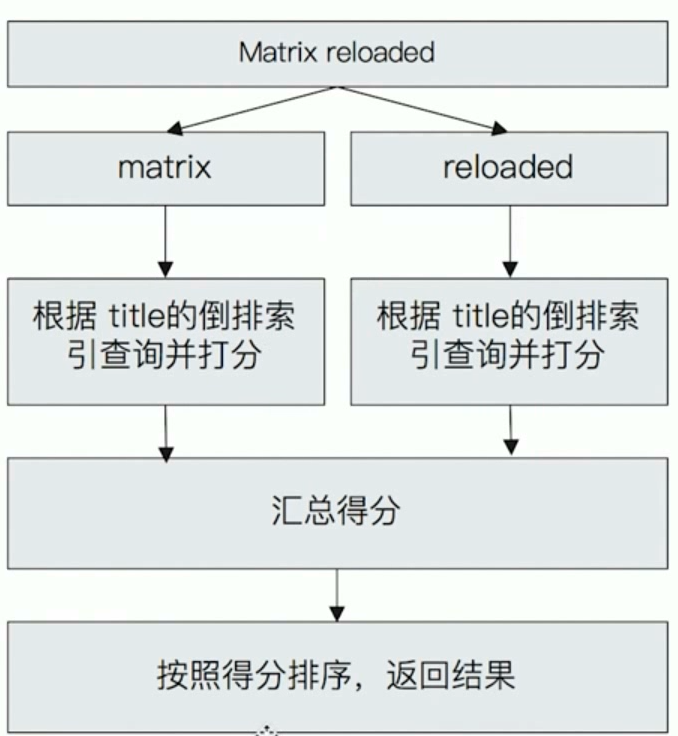















 323
323











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









