






1.明确因变量与自变量
研究范围:南京老城
研究单元:500×500m格网
因变量:店铺密度(即每个研究单元内商业店铺的个数)
自变量:产业园可达性(研究单元与最近产业园的距离)、地铁可达性、景点密度、路网密度等
数据来源:高德poi数据,南京行政边界shp,南京道路网shp
方法:OLS/SLM/SEM和GWR
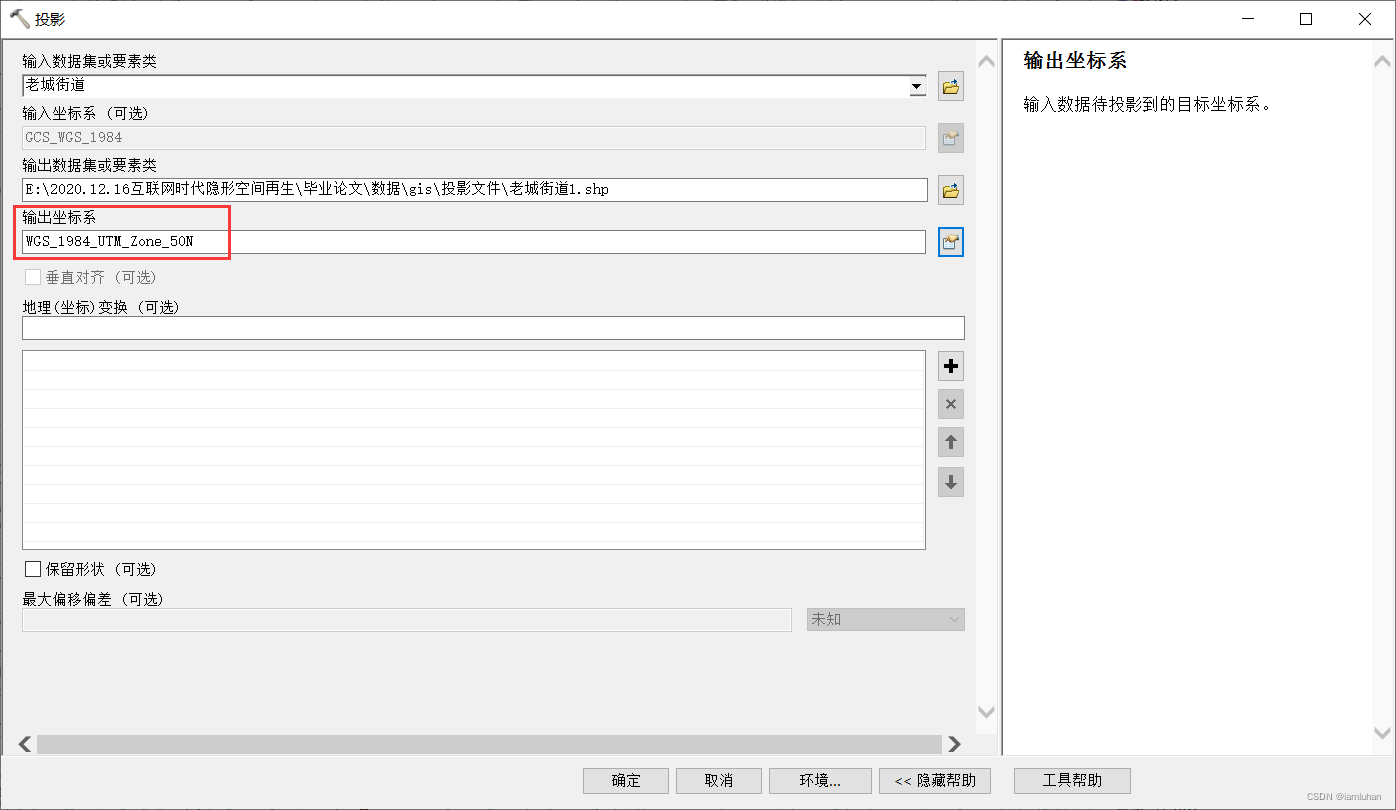
2.【投影】把地理坐标转换为投影坐标
如果原本数据是WGS1984坐标,先通过数据【管理工具——投影和变换——投影】转化为对应的投影坐标,【输出数据集或要素】最好建一个投影文件夹用来存放投影过的数据,【输出坐标系】不同城市不一样例如南京的投影坐标是50N,选择【投影坐标系——UTM——WGS1984——Northerm——WGS_1984_UTM_Zone_50N】,确定。
输出后可以改当前gis的背景坐标也可以新建一个gis文件(我倾向新建)把投影过的数据拖进去。
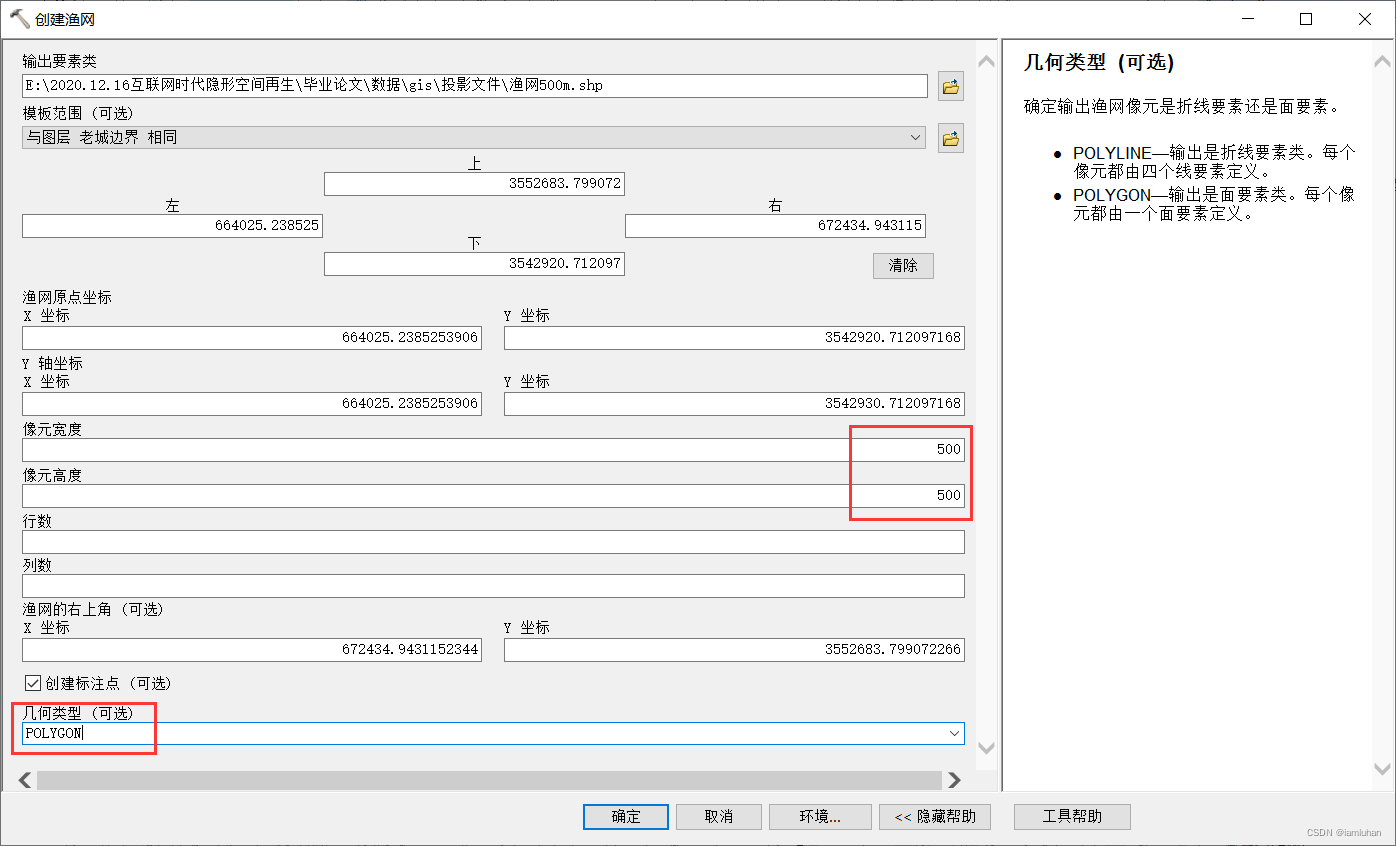
2.【创建渔网】确定最小研究单元
由于行政边界数据精确到街道,我的研究范围内的街道数量没几个,空间分析至少需要30个样本才能获得比较好的结果,于是我需要创建500m×500m的渔网。在【ArcToolBox——数据管理工具——采样——创建渔网】,【输出要素类】可以选择投影文件夹,【模板范围】选择研究范围,自动获取上下左右坐标,【像元宽度】【像元高度】均填500,【几何类型】选第二个polygon即生成面,确定。
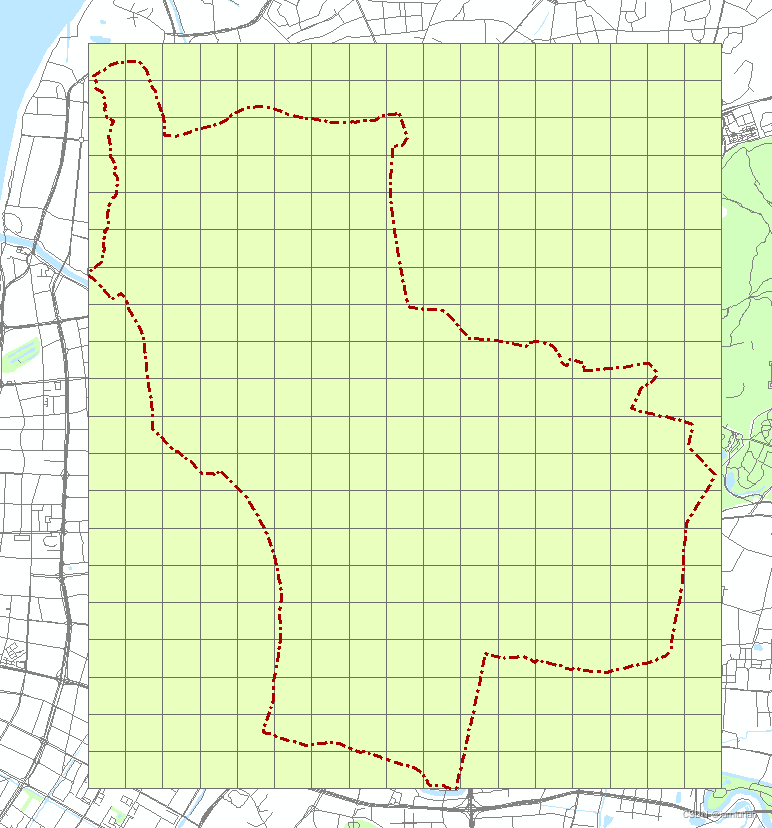
生成了这样的均匀网格面,先不着急裁剪。接下来先把自变量和因变量的值赋在网格上。
3.【空间连接】将变量信息赋到网格上
(1)统计产业园密度前,先把南京产业园区点数据的属性表打开,添加字段“CY_个数”,并用字段计算器全部赋值为1
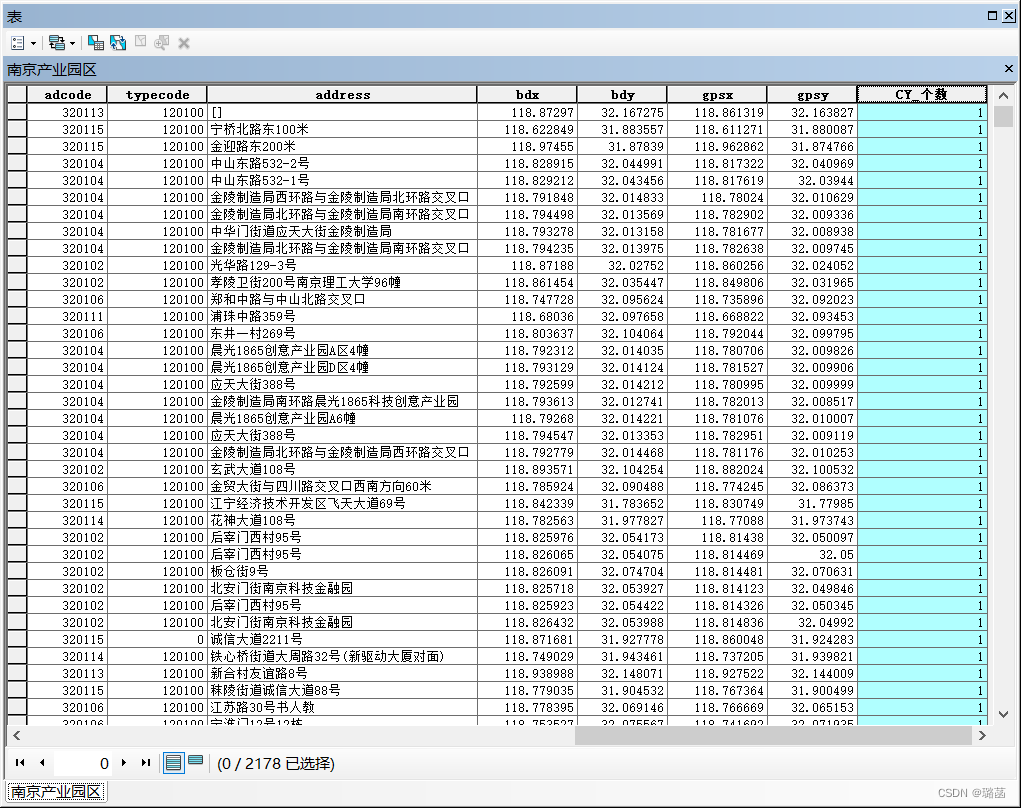
(2)ArcToolBox——分析工具——叠加分析——空间连接
【目标要素】选择渔网,【连接要素】选择产业园区的poi点,【输出要素】改个名字,【连接操作】默认一对一,把【连接要素的字段映射】中没用的字段叉掉,留下之前创建的“CY_个数”字段,右键改名为“CYYQ_midu”,右键【合并规则】选择【总和】,其他默认,确定。
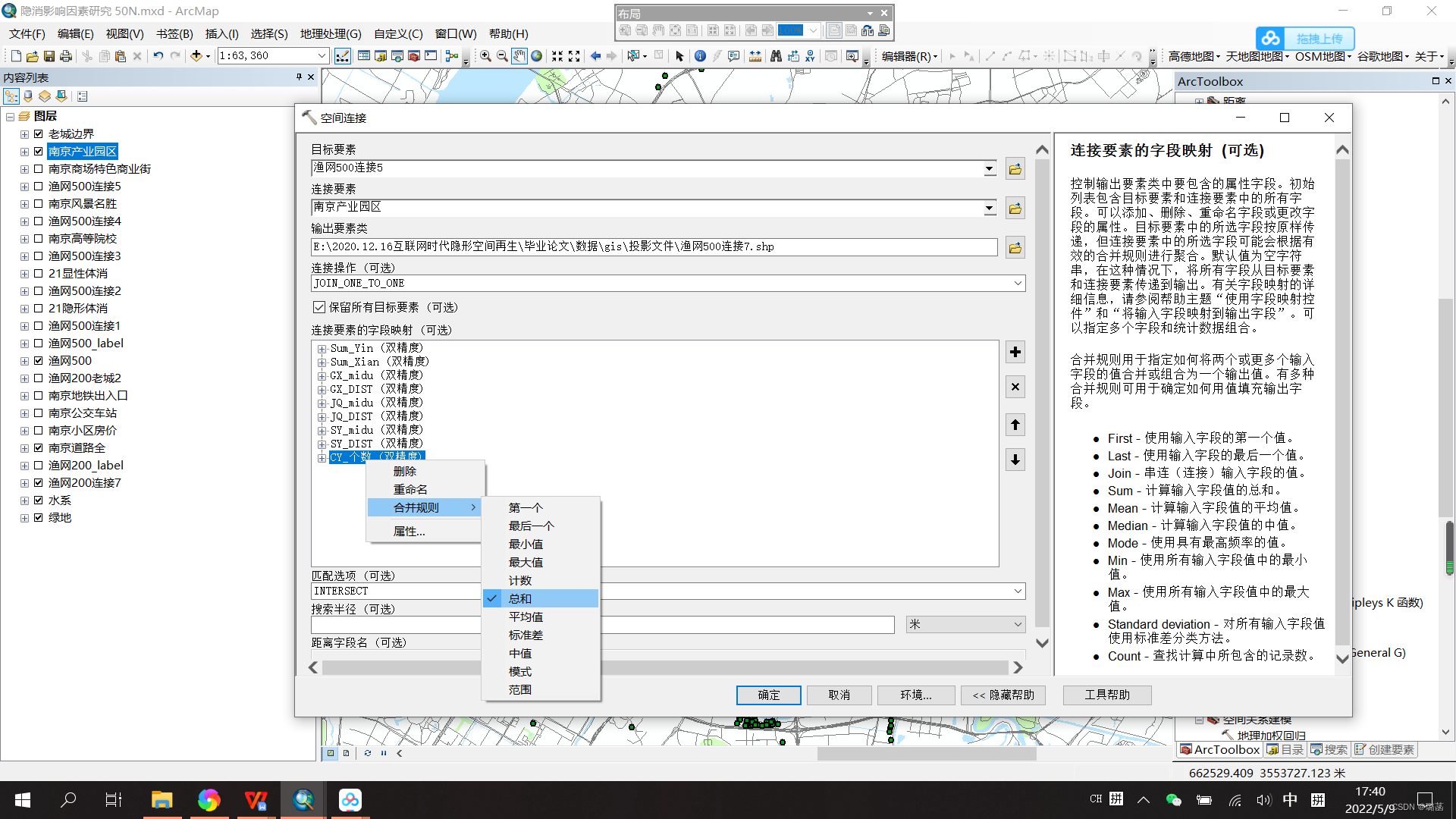
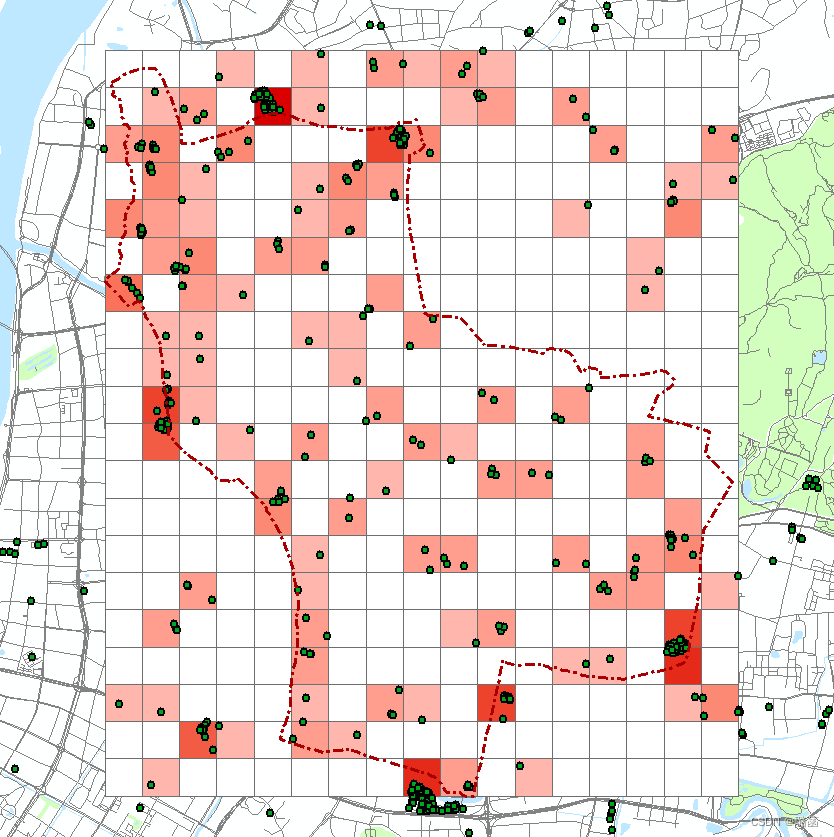
每个格子里产业园点的数量就已经赋值到渔网上了,每个格子面积相等,当作产业园区密度,可视化时,如果把0值手动调整为白色,可看出没有产业园落点的格子和有落点的格子数值不同。
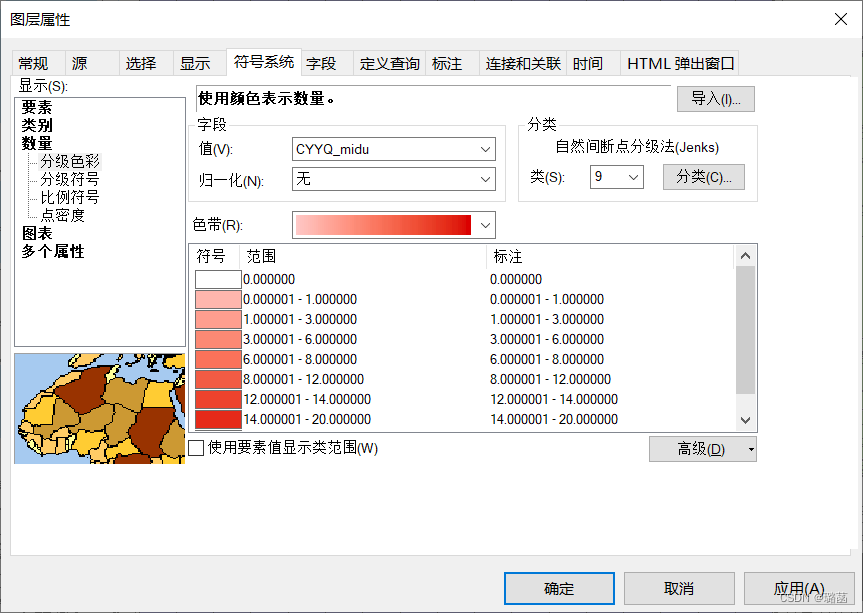
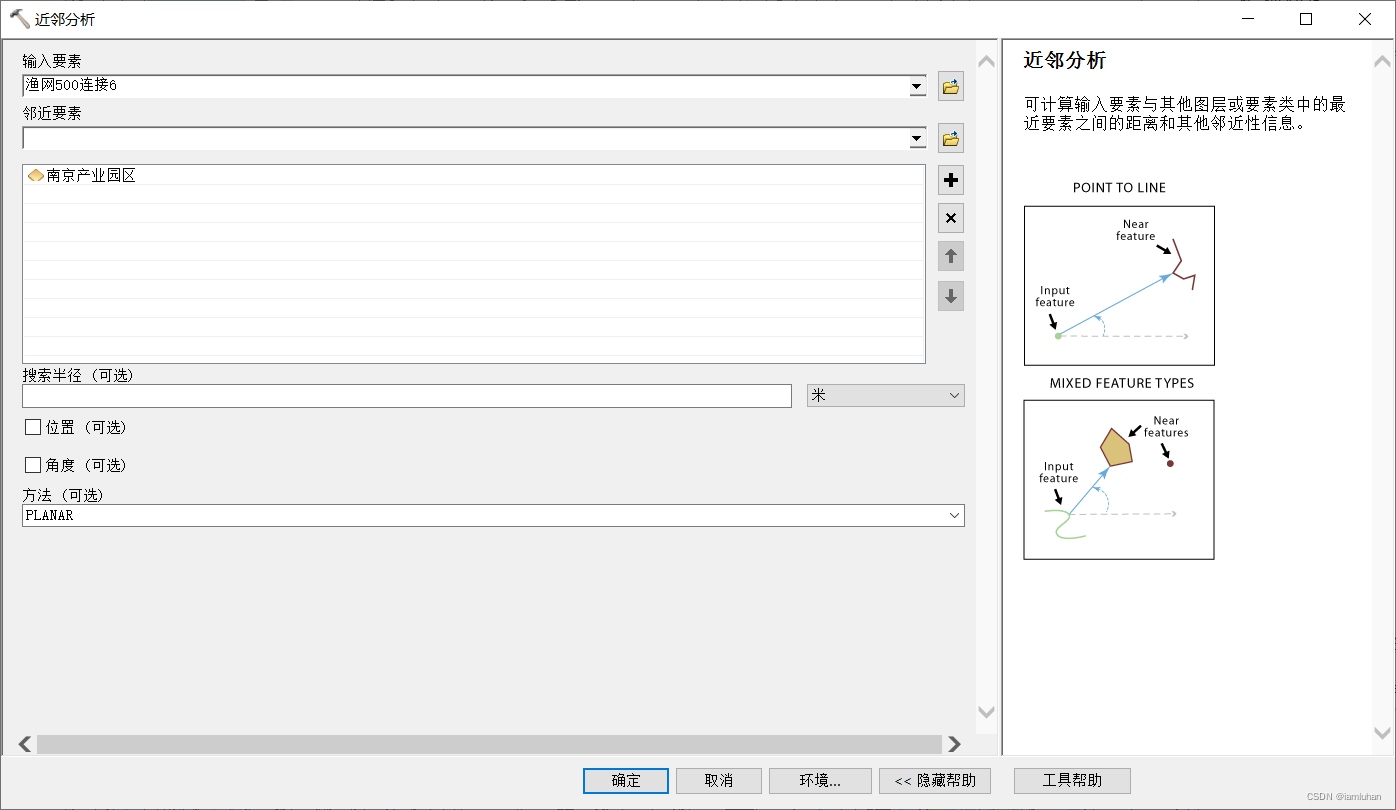
(3)ArcToolBox——分析工具——邻域分析——近邻分析
用【近邻分析】可以量出每个格子和离它最近的产业园点的距离,【输入要素】选择上一步生成的渔网面shp,【邻近要素】选择产业园poi数据,其他默认,确定。
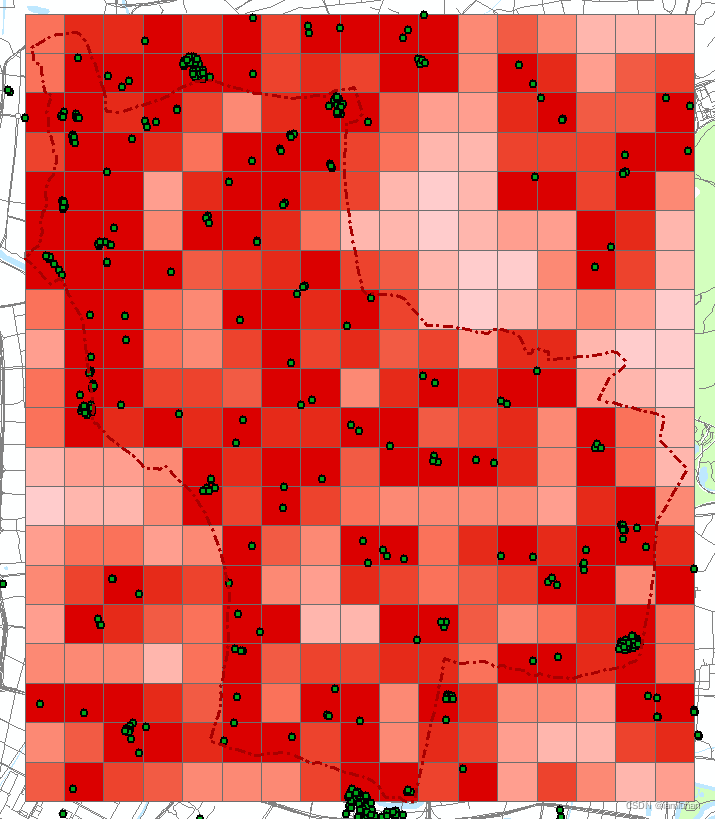
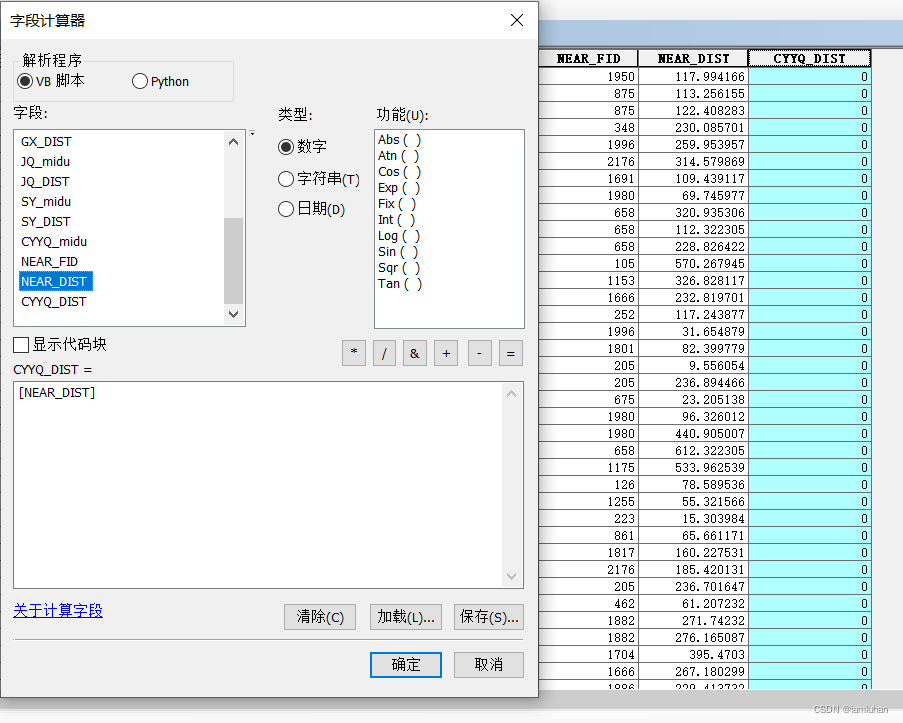
打开该渔网图层的属性表,发现多了两列字段,NEAR_DIST即为每个格子和离它最近的产业园点的距离,为了方便辩认可以给字段改个名字,添加字段“CYYQ_DIST”,用字段计算器让该字段等于“NEAR_DIST”,然后就可以删掉那两列字段了。至此,每个网格单元的产业园密度和产业园可达性都有了。
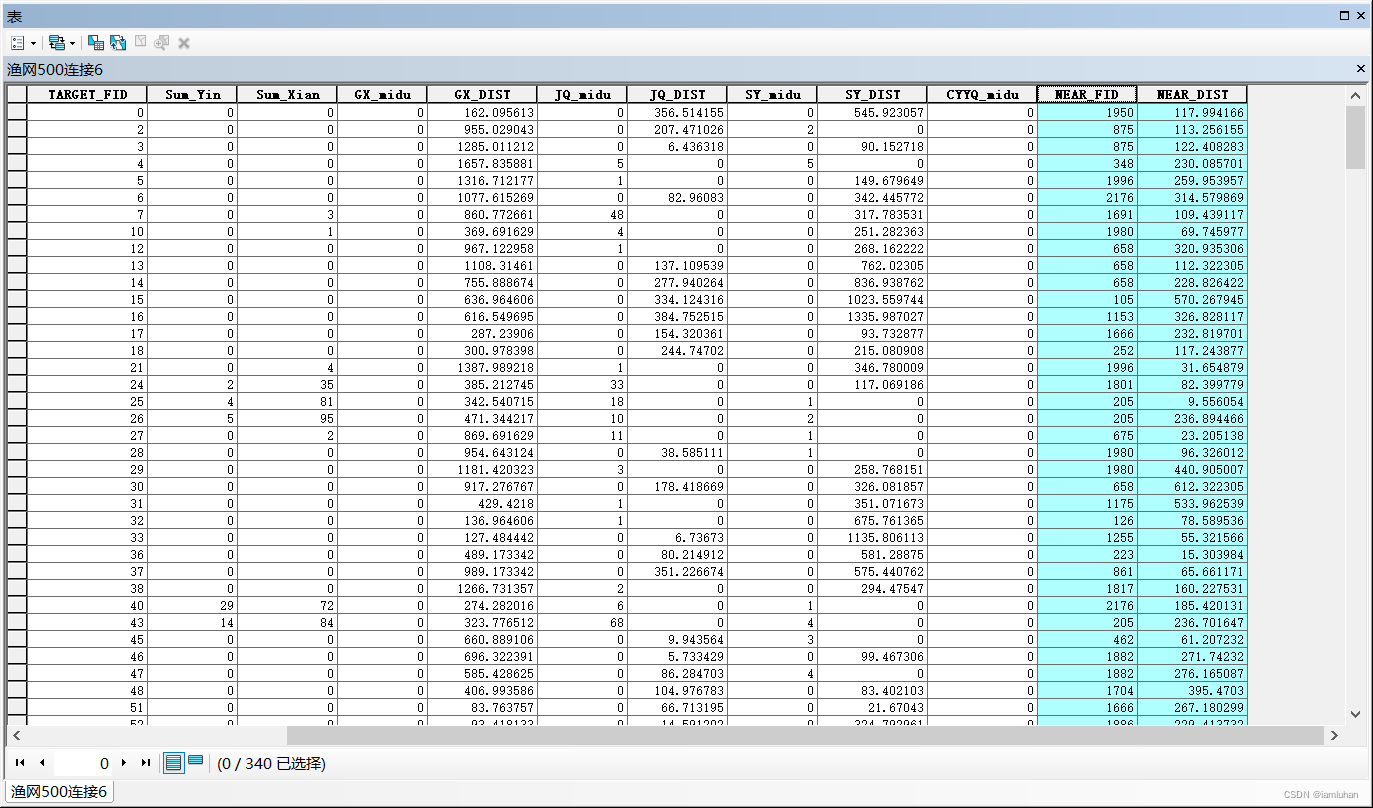
(4)同理把其他变量如景点密度、商场可达性、地铁可达性等自变量以及店铺密度因变量用【空间连接】或【近邻分析】赋值到网格,至此,大部分变量都赋值到了单元格。
4.统计渔网单元格的路网密度
(1)ArcToolBox——分析工具——叠加分析——相交
把南京路网线数据shpfile与“渔网500”图层相交,输出“渔网500道路”,即得到渔网范围内的道路线要素,此时路网已被网格打断,打开属性表,添加双精度字段“length”,【计算几何】长度单位米,计算出每段路长度。
(2)右键“FID_渔网”字段汇总,统计“length”字段的总和,输出debase表“Sum_路长500”
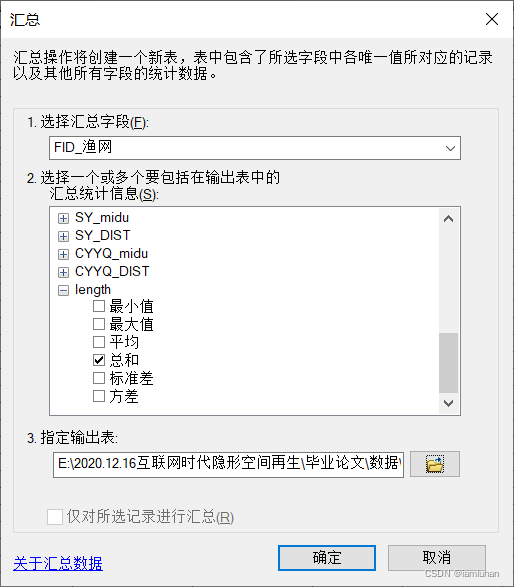
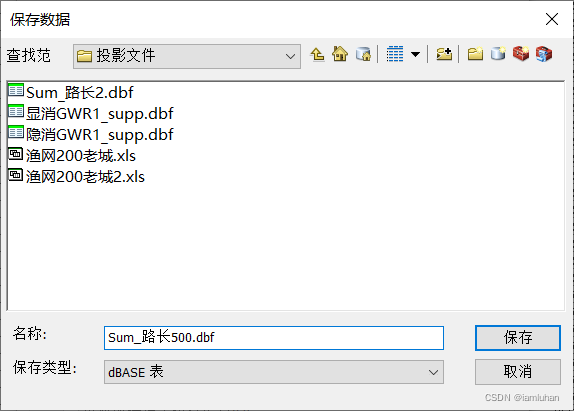
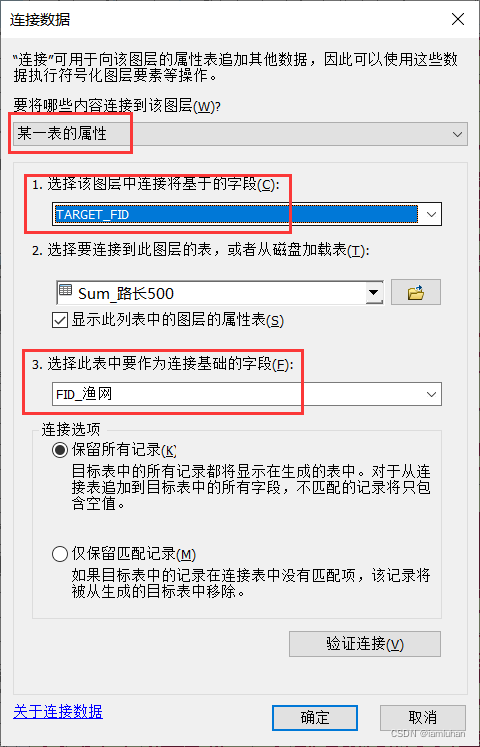
(3)右键渔网图层(此处延用第3步最新的“渔网500连接6”图层),连接生成的debase表的属性,基于的字段可以用FID或第3步生成的TARGET_FID,此表作为连接的字段选择“FID_渔网”,确定。
(4)打开属性表看到“Sum_length”即为每个格网内道路总长度(m),新建字段“Road_midu”,字段计算器使其=“Sum_length”/250,算出每个格网的道路密度(km/km²),然后可以解除连接。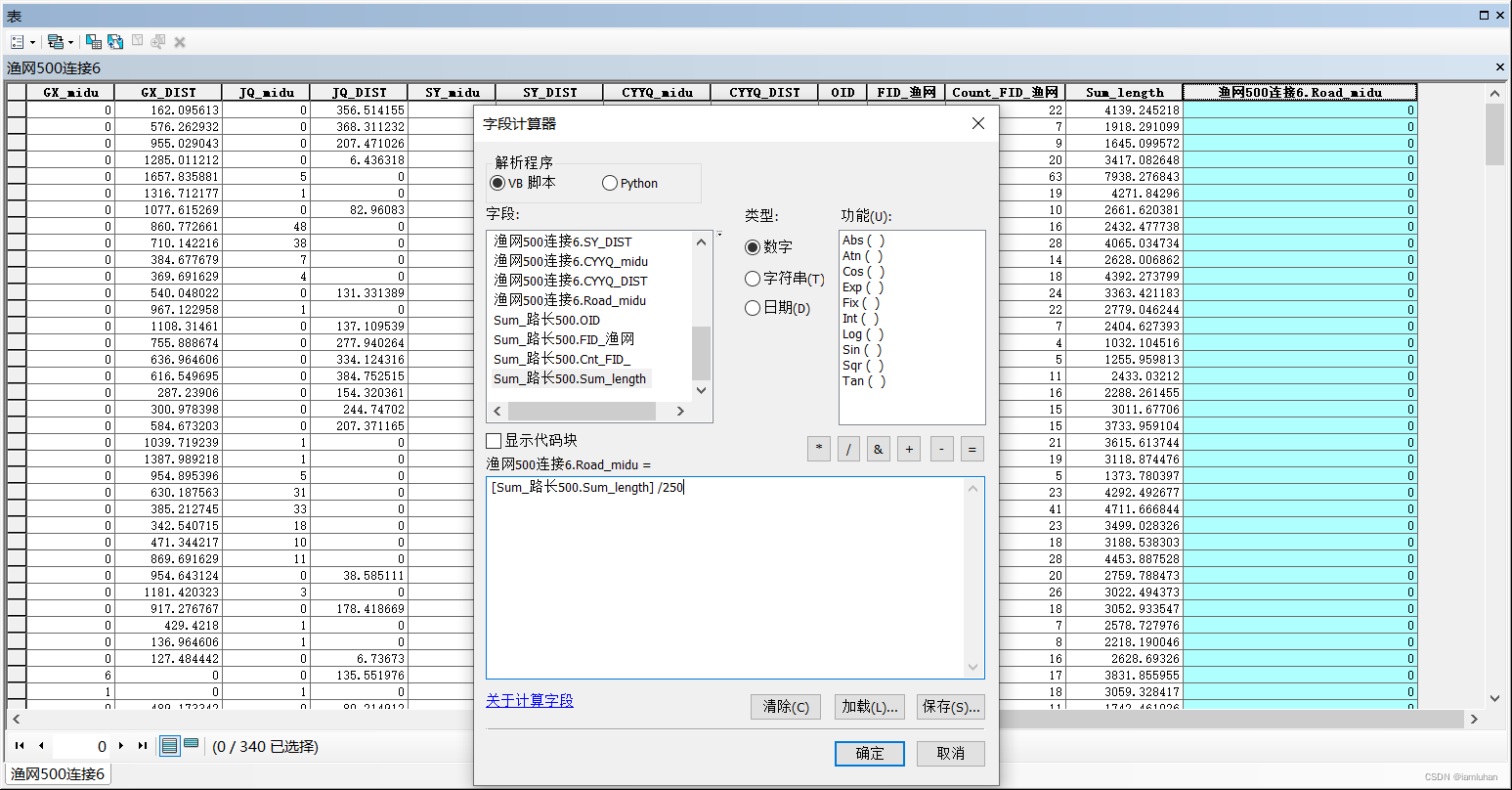
最后所有的变量都录入了,运用【ArcToolBox——分析工具——叠加分析——相交】把矩形网格沿着研究范围裁剪一下。把字段名都统一为非汉字,方便后续研究。
5.运用GEODA软件做最小二乘回归模型(OLS)、空间滞后模型(SLM)和空间误差模型(SEM)分析
(1)将上一步生成的shpfile文件导入geoda软件(字段名为非汉字否则导入失败),显示出被划分为500×500网格的地图样式。
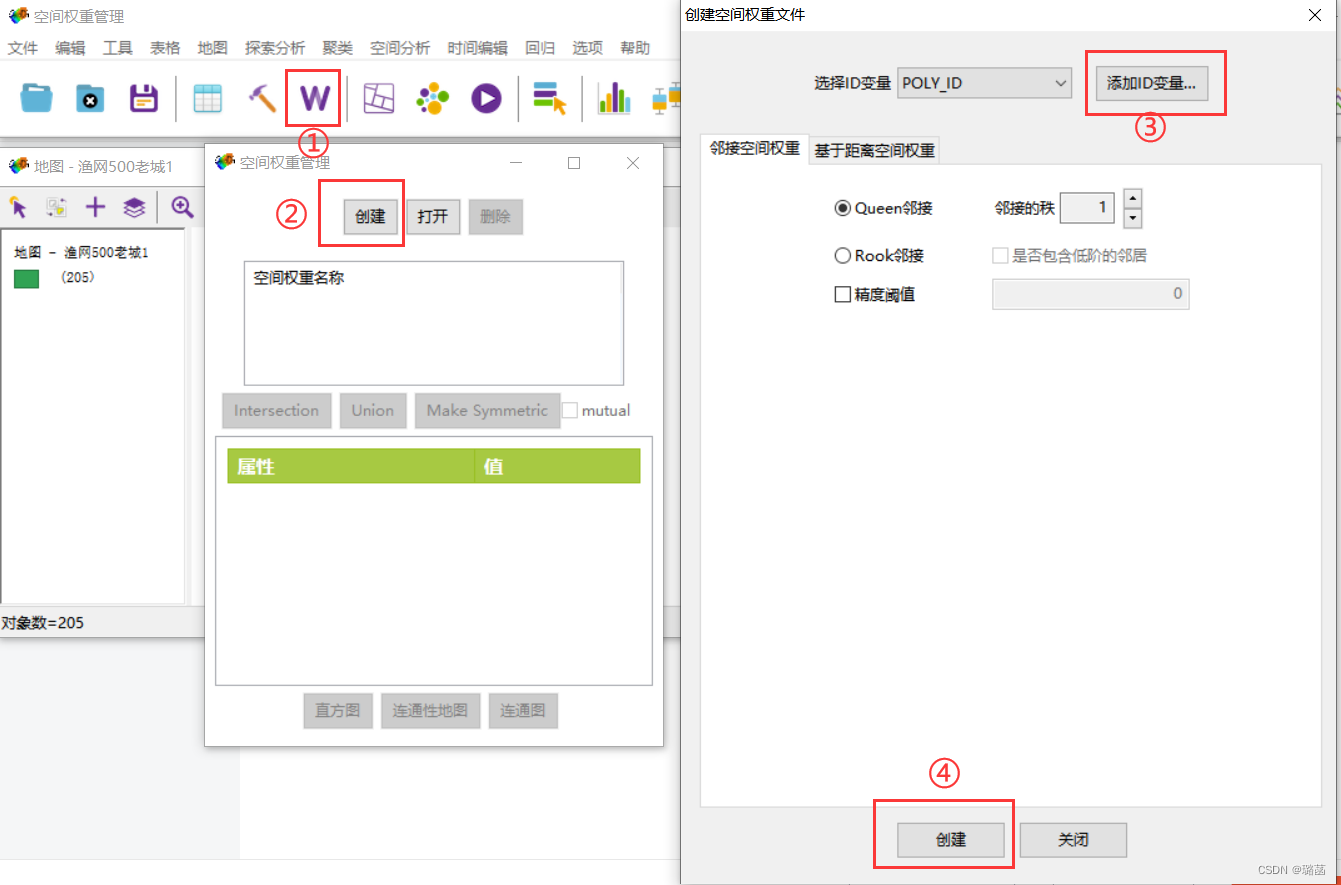
(2)生成空间权重矩阵
①找到空间权重管理图标,②创建权重矩阵,③由于每个网格都需要id,如果shp里没有这个变量,就创建POLY_ID变量,④设置相邻的类型,这里采用“Queen 邻接”或“Rook 邻接”都可以,其他默认,点创建。
(Queen邻接:两个格子有公共边界或公共点则相邻,为1;否则为0。Rook 邻接:是两个格子有公共边界则相邻,为1;否则为0。邻接的秩:生成的权重矩阵为一阶或多阶;一阶指只将直接相邻的格子记为1;二阶指不仅将直接相邻的格子记为1,相邻格子的相邻格子也记为1;以此类推。一般情况下,我们均采用一阶空间权重矩阵)
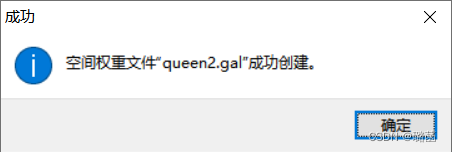
(3)打开回归分析面板,输入因变量和自变量,权重文件选择上一步生成的文件,分别做OLS、空间滞后(SLM)、空间误差模型(SEM)分析,运行。生成三份回归分析报告,可以横向比较各参数决定选择用哪个模型。
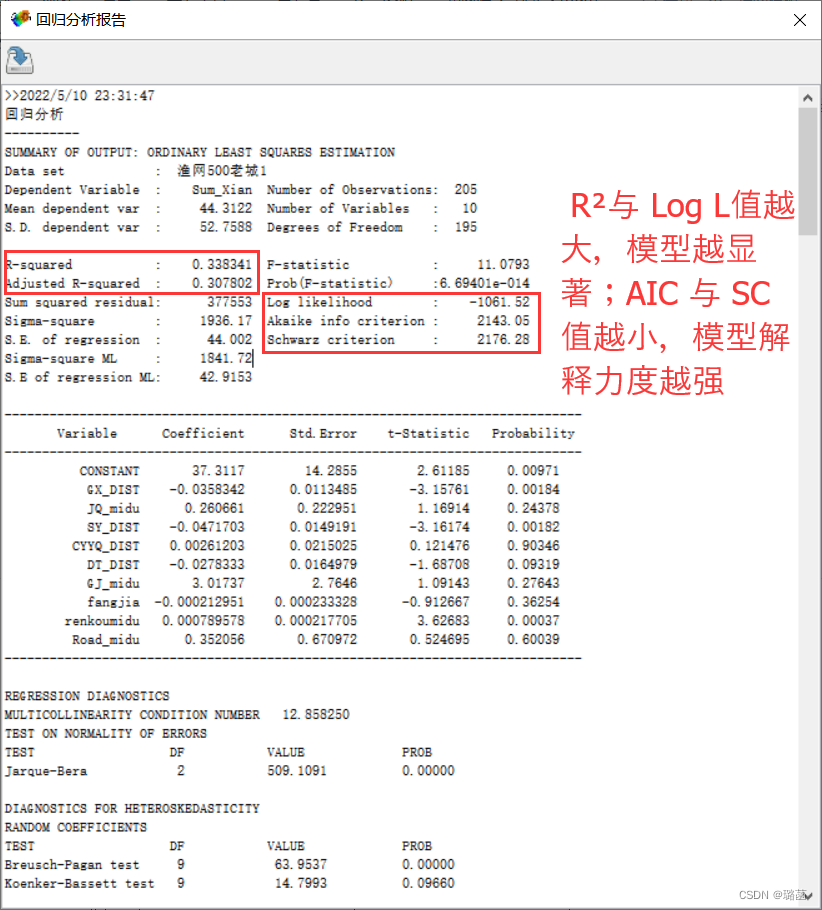
6.gis做GWR地理加权回归分析
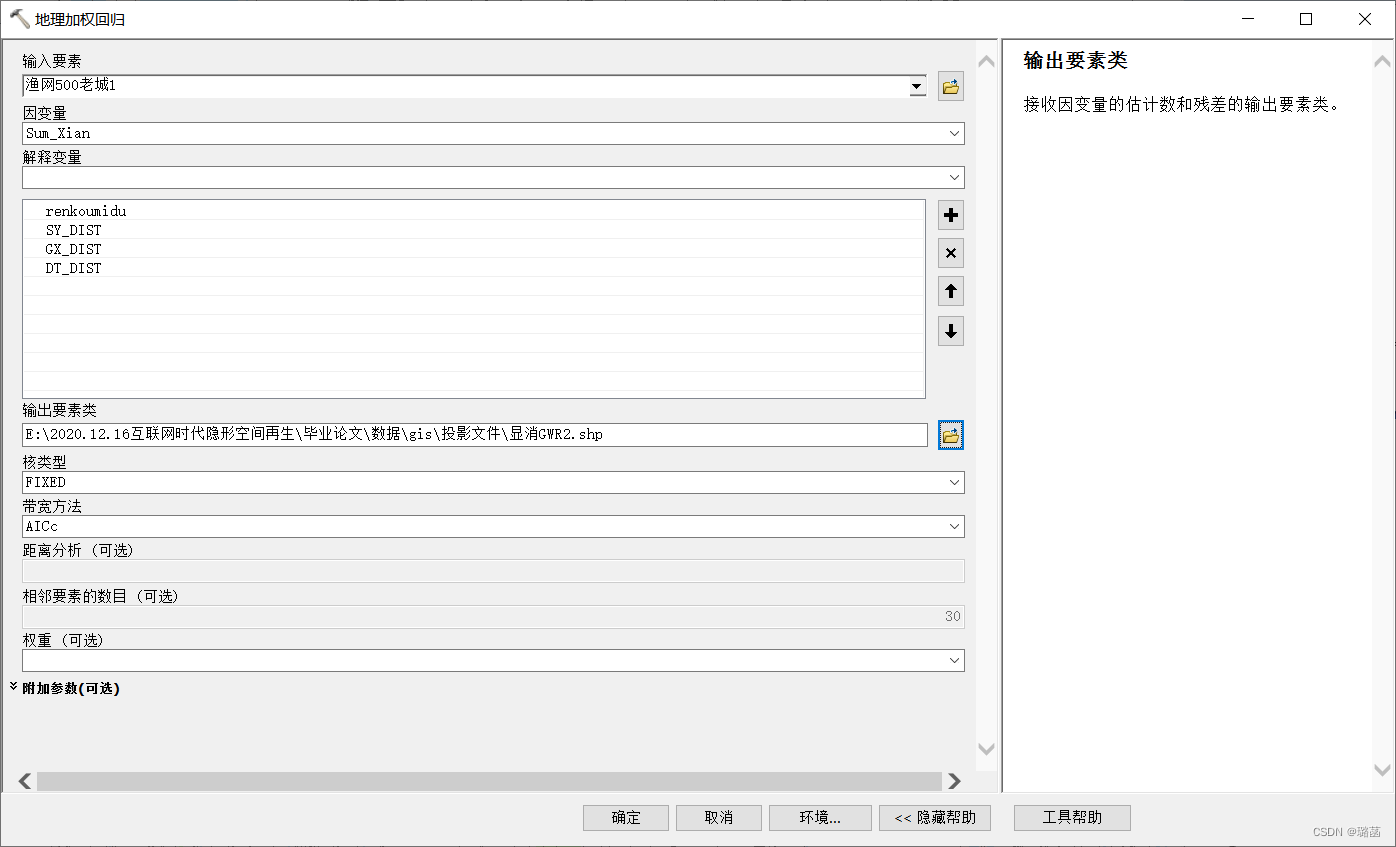
ArcToolBox——空间统计工具——空间关系建模——地理加权回归
输入要素为裁剪后的渔网,把通过显著性检验的自变量输入解释变量
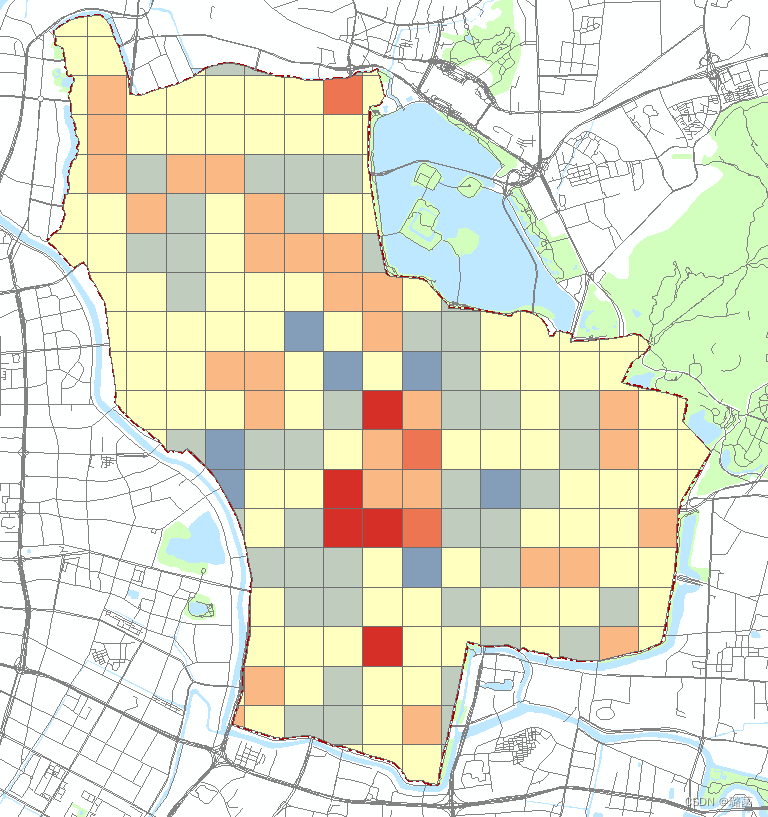

















 597
597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









