






目录
本人致力于工业互联网领域多年,做过云端项目与本地化项目,同时目前正在学习大数据与云原生,自己根据多年经验与网络资料,自定义了一套云原生项目架构用于学习研究,基于该架构可以衍生各种变种,例如物联网项目,大数据项目等。本人第一次写博客,有问题勿喷,欢迎技术交流。
一、云原生项目架构:
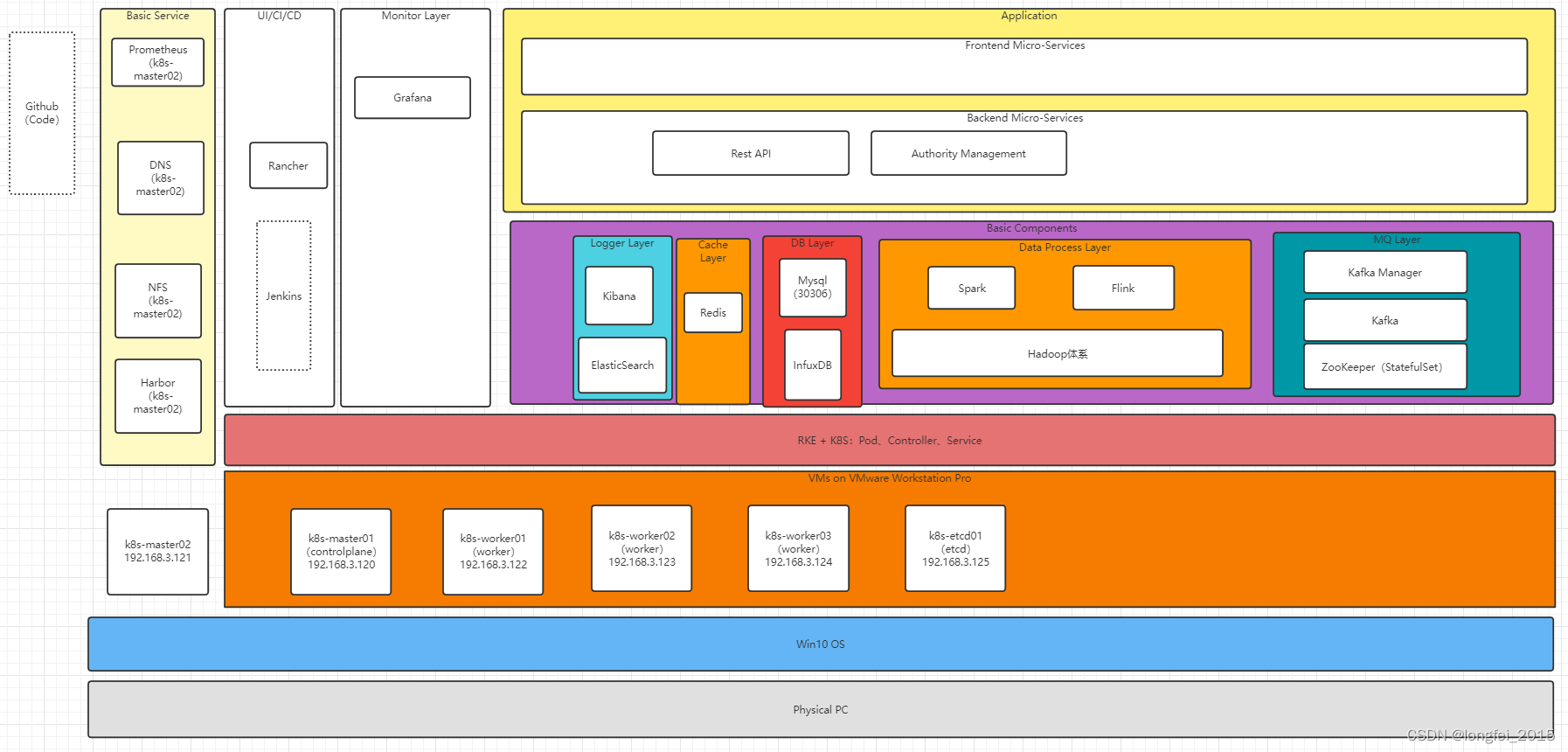
二、架构落地
1,MQ模块
参考资料:
1,https://www.hangge.com/blog/cache/detail_3091.html
2,https://www.cnblogs.com/lvcisco/p/12574601.html
Window环境Kafka管理工具:offset explorer
2,DB模块
1. MySQL部署参考资料: https://www.cnblogs.com/code-craftsman/p/11661959.html
2. InfluxDB部署参考资料: https://www.cnblogs.com/zhangsi-lzq/p/14457707.html
3,大数据组件模块
Flink: flink session部署模式
参考资料:
1.https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/deployment/resource-providers/standalone/kubernetes/
2.https://blog.csdn.net/qq_14999375/article/details/123309667
注意事项:通过RBAC 解决权限问题
Hadoop
参考资料:https://blog.csdn.net/chenleiking/article/details/82467715
问题:
1,部署复杂:需要自制Hadoop容器镜像,预配置Hadoop配置文件,NameNode和DataNode需要有先后部署顺序
2,稳定性问题:NameNode和DataNode启动需要有先后顺序,集群虚拟机重启后,Hadoop组件重启,此时会出现启动故障。
Spark:Spark Operator部署模式
参考资料:https://blog.csdn.net/u010318804/article/details/118306990
使用Helm部署Spark Operator
碰到的问题:
1,镜像拉取困难问题:通过阿里云镜像构建服务方式拉取
4,组件运行状态



















 205
205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









