




前段时间作者通过一篇文章(链接地址:https://bbs.21ic.com/icview-3451652-1-1.html)从工作原理,算法步骤,时间复杂度,空间复杂度,稳定性,源代码和仿真验证等方面介绍了三种常用的排序算法(冒泡排序、选择排序、插入排序)。其实对于一般的嵌入式系统设计来说,这三种排序算法基本上也够用了,不过对于更高级的嵌入式系统应用,比如航空航天和军事应用等,则可能需要更高效的数据排序算法,这篇文章作者就带大家一起来看下两个相对来说效率更高的排序算法,即归并排序算法和快速排序算法。
1、归并排序算法
归并排序(Merge Sort)是一种基于分治法的高效排序算法,其核心思想就是将数组递归地分成两半,分别排序后再合并成一个有序数组。
算法步骤主要包括:
分解:将当前数组从中间分成左右两部分,直到子数组长度为1(天然有序);
解决:递归地对左右子数组进行归并排序;
合并:将两个已排序的子数组合并成一个有序数组。
其中合并是归并排序的核心步骤,详细如下:
初始化一个临时数组,用两个指针分别指向左右子数组的起始位置;
比较指针指向的元素,将较小的放入临时数组,并移动对应指针;
重复步骤2,直到某一子数组被完全合并;
将剩余子数组的元素直接追加到临时数组;
将临时数组拷贝回原数组的对应位置。
算法的时间复杂度如下所示:
最优/最差/平均情况:均为 O(nlogn)。
每次分解数组需要 O(logn) 层递归,每层合并操作需要 O(n) 时间。
算法的空间复杂度如下所示:
O(n),因合并时需要临时数组。
算法的主要特点如下所示 :
稳定排序:相等元素的相对顺序不会改变;
非原地排序:需要额外空间(但可通过优化减少);
适合大数据集:相比冒泡排序等算法更高效,但常数因子较大。
C语言实现的算法代码如下:
复制
// 合并两个已排序的子数组void merge(int arr[], int left, int mid, int right) {int i, j, k;int n1 = mid - left + 1; // 左子数组的大小int n2 = right - mid; // 右子数组的大小// 创建临时数组int *L = (int *)malloc(n1 * sizeof(int));int *R = (int *)malloc(n2 * sizeof(int));// 拷贝数据到临时数组for (i = 0; i < n1; i++)L[i] = arr[left + i];for (j = 0; j < n2; j++)R[j] = arr[mid + 1 + j];// 合并临时数组回原数组i = 0; // 初始化左子数组的索引j = 0; // 初始化右子数组的索引k = left; // 初始化合并子数组的索引while (i < n1 && j < n2) {if (L[i] <= R[j]) {arr[k] = L[i];i++;} else {arr[k] = R[j];j++;}k++;}// 拷贝左子数组剩余的元素(如果有)while (i < n1) {arr[k] = L[i];i++;k++;}// 拷贝右子数组剩余的元素(如果有)while (j < n2) {arr[k] = R[j];j++;k++;}// 释放临时数组内存free(L);free(R);}// 归并排序主函数void mergeSort(int arr[], int left, int right) {if (left < right) {// 计算中间点,避免溢出int mid = left + (right - left) / 2;// 递归排序左半部分mergeSort(arr, left, mid);// 递归排序右半部分mergeSort(arr, mid + 1, right);// 合并已排序的两部分merge(arr, left, mid, right);}}
在Visual C++ 6.0软件上验证算法代码的正确性:

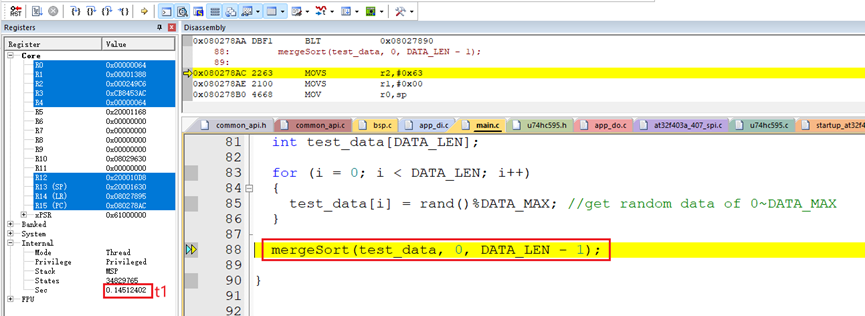
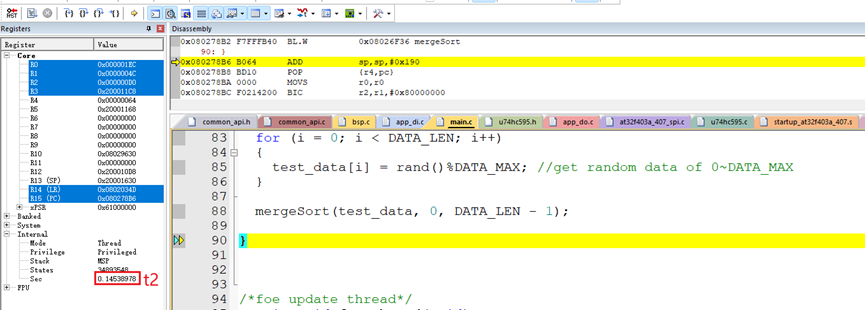
使用硬件板子在Keil软件上测试了排序100个随机数据的算法执行时间:
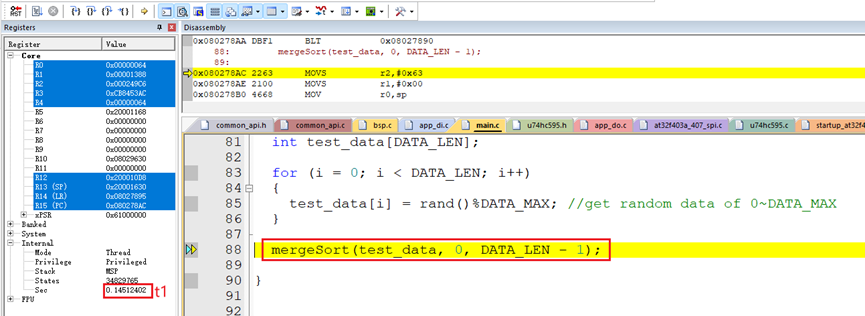
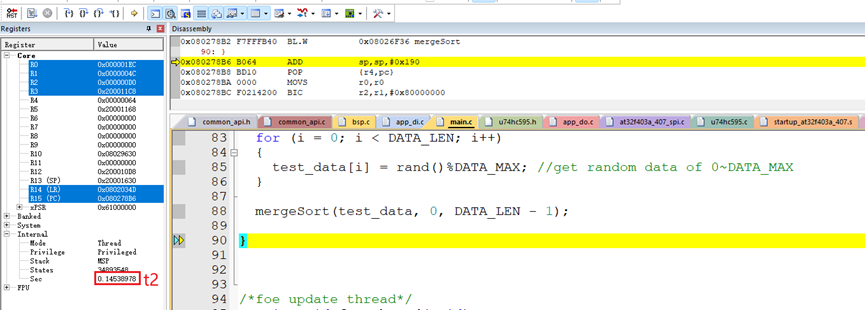
排序100个随机数据的算法执行时间t:
t = t2-t1 = 0.14538978秒 – 0.14512402秒 = 265.76微秒。
2、快速排序算法
快速排序(Quick Sort)是由Tony Hoare 在 1959 年提出的一种高效的分治排序算法,其核心思想是通过一趟排序将待排序列分割成独立的两部分,其中一部分的所有元素比另一部分小,然后递归地对这两部分继续排序。
算法步骤主要包括:
选择基准:从数组中选择一个元素作为基准(通常选第一个、最后一个或随机元素)。
分区:将小于基准的元素移到基准左侧,大于基准的元素移到右侧,基准最终位于正确的位置(排序后的最终位置);
递归排序:对基准左右两边的子数组重复上述过程,直到子数组长度为 1 或 0。
时间复杂度:
平均情况:O(n log n)
每次分区将数组分成大致相等的两部分,递归深度为 log n,每层分区操作耗时 O(n);
最坏情况:O(n²)
当数组已有序或逆序时,每次分区只能减少一个元素(如基准总选到最大/最小值)。
空间复杂度:
平均:O(log n);
最坏:O(n)(未优化的递归实现)。
稳定性:
快速排序是不稳定排序,因为分区过程中可能改变相等元素的相对顺序。
C语言实现的算法代码如下:
复制
// 交换两个元素的值void swap(int* a, int* b) {int temp = *a;*a = *b;*b = temp;}// 分区函数,返回基准元素的最终位置int partition(int arr[], int low, int high) {int pivot = arr[high]; // 选择最后一个元素作为基准int i = (low - 1); // i是小于基准的元素的索引for (int j = low; j <= high - 1; j++) {// 如果当前元素小于或等于基准if (arr[j] <= pivot) {i++; // 增加iswap(&arr[i], &arr[j]); // 交换元素}}swap(&arr[i + 1], &arr[high]); // 将基准放到正确的位置return (i + 1);}// 快速排序主函数void quickSort(int arr[], int low, int high) {if (low < high) {// pi是分区索引,arr[pi]现在在正确的位置int pi = partition(arr, low, high);// 分别对分区前后的子数组进行排序quickSort(arr, low, pi - 1);quickSort(arr, pi + 1, high);}}
在Visual C++ 6.0软件上验证算法代码的正确性:

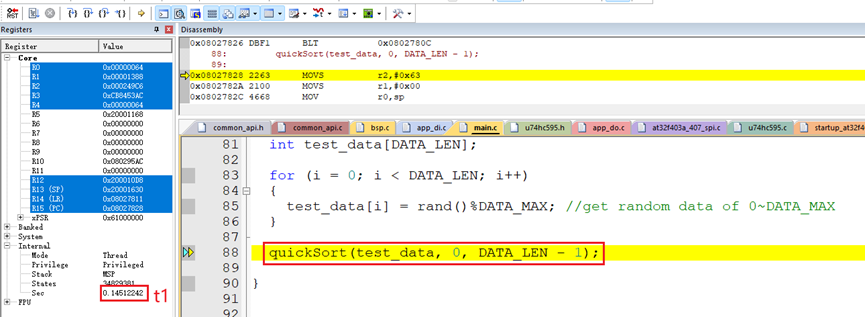
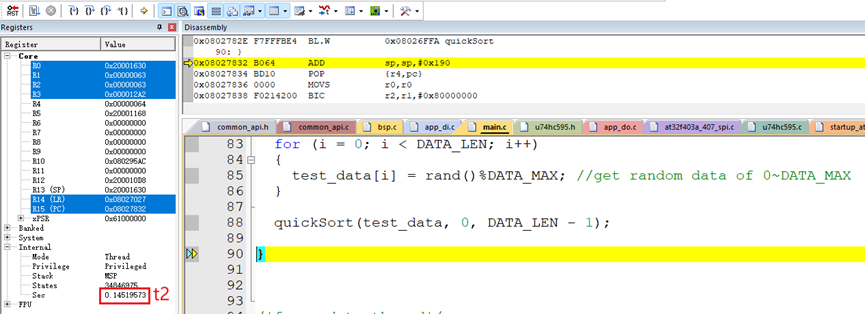
使用硬件板子在Keil软件上测试了排序100个随机数据的算法执行时间:
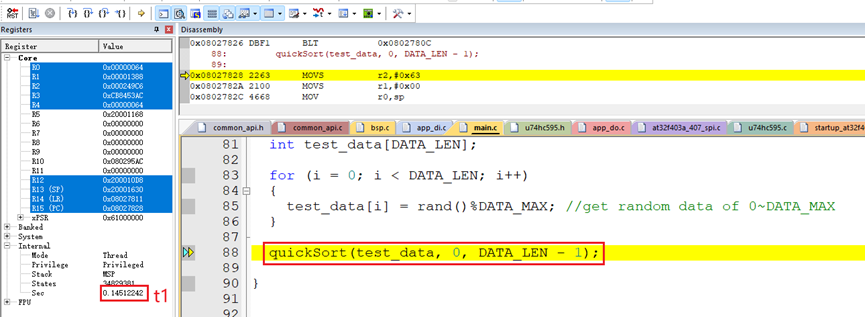
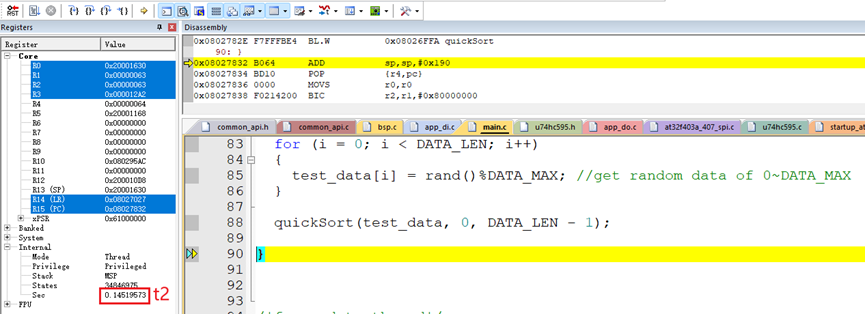
排序100个随机数据的算法执行时间t:
t = t2-t1 = 0.14519573秒 – 0.14512242秒 = 73.31微秒。
另外,快速排序是面试中可能经常会涉及的算法,有兴趣的朋友可以深入研究一下!
从以上对两种排序算法的实测验证可以得出结论:
在平均情况下,快速排序算法的执行速度更快,特别是在处理大规模数据的时候;
归并排序算法的执行时间看上去好像和插入排序算法差不多,其实原因是这样的:如果测试数据已经是有序的或者接近有序的,插入排序会表现得非常好,因为它的时间复杂度在最好情况下是O(n);而归并排序的时间复杂度是O(nlogn),在这种特殊情况下,归并排序的优势无法体现。
因此,在实际应用时,也要根据待排序数据的有序性和数据量等方面综合考虑选择合适的排序算法,甚至可以通过数据排序实测的方法来确定选择使用哪一种排序算法,毕竟适合自己的才是最好的!
加上之前文章介绍的排序算法,作者总共提供了五种排序算法,供大家参考和选择:
冒泡排序、插入排序、选择排序、归并排序、快速排序。


。
---------------------
作者:dffzh
链接:https://bbs.21ic.com/icview-3458580-1-1.html
来源:21ic.com
此文章已获得原创/原创奖标签,著作权归21ic所有,任何人未经允许禁止转载。

















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









