







后缀树与最长回文子串
最长回文子串的问题:
回文串:正反一样的字符串.
如ABCDCBA,反过来是还是ABCDCBA.
回文子串:DABCAEA中有两个回文子串(不包括长度为1的),即ABCA,AEA.
长度ABCA>AEA.
那么字符串DABCAEA的最长回文子串就是ABCA.
解决方法:
1. 遍历所有的子串.
长度N的字符串,共有2^N个子串,去除长度为0,1的,也有2^N-N-1个.遍历的时间复杂度是O(2^N),还要加上判断是否回文的函数.
2. 以某个字符为中心,向两边扩散寻找.
当某个字符为中心较短的子串不满足要求时,其更长的子串也不可能满足要求,减少了遍历算法中许多不必要的计算.
时间复杂度为O(N^2).
3. 后缀树
后缀树是解决许多字符串问题的利器.下面介绍后缀树.
Trie
Trie树,又称字典树,单词查找树或者前缀树,是一个用于快速检索的多叉树. 典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计(@july)。如英文字母的字典树是一个26叉树,数字的字典树是一个10叉树.
Trie利用字符串的公共前缀来节省存储空间,并且能够以空间换时间.
盗用别人的一张图, 给出一组单词,inn, int, at, age, adv, ant, 我们可以得到下面的Trie:
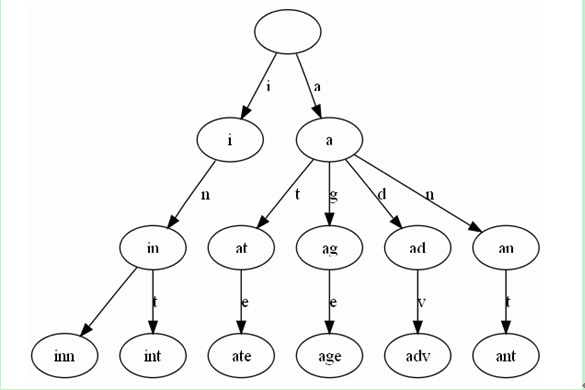
根据上面的trie,我们可以
1. 计算任意某两个单词的最长公共前缀,就是我们待会要详细说明的LCA算法.
2. 快速计算某个单词的出现次数.也就是我们上面说的以空间换时间的方法,建树与查询同时进行,每次根据单词查询或新建节点,计数.时间复杂度为O(N*length),length表示字符串的平均长度.
后缀树
我们再通过trie,即前缀树,来引出后缀树.
后缀的含义:
对于字符串XMADAMYX,他的后缀是从后往前数的任意连续序列,如X,YX,MYX...XMADAMYX等都是其后缀,我们记作S[i],表示从第i个到最后的后缀.
S[1], XMADAMYX, 也就是字符串本身,起始位置为1
S[2], MADAMYX,起始位置为2
S[3], ADAMYX,起始位置为3
S[4], DAMYX,起始位置为4
S[5], AMYX,起始位置为5
S[6], MYX,起始位置为6
S[7], YX,起始位置为7
S[8], X,起始位置为8
接着,我们用上面trie的方法,把一个字符串的所有后缀建立trie.再盗用一张图.如下:
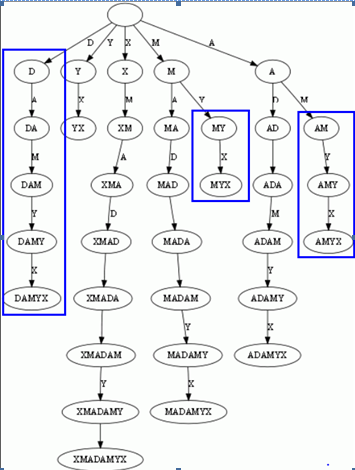
正如我们上面说的,一般trie是许多字符串生成的前缀树,而这里我们用一个字符串生成N个后缀子串,再用后缀子串生成trie.
上图中,有许多中间节点是多余的,我们要用最少的节点来表示,并且所有的后缀都是叶子节点,那么就做如下的压缩:
1. 每个节点可以存储多个字母.
2. 字符串后加一个结尾,如’$’,那么就不会有任意后缀是其他后缀的前缀,压缩的时候就不会有后缀被压缩掉.
于是,我们得到了压缩的后缀树:
继续盗图:
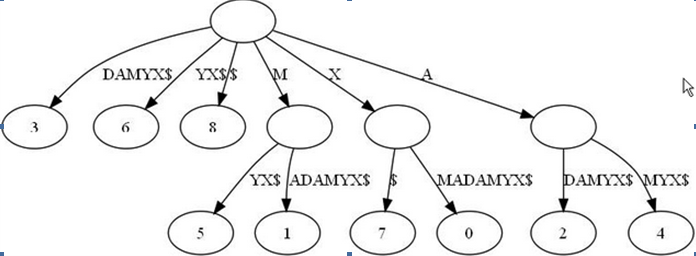
于是我们概括为 ( 后缀树=后缀子串们+ trie ).
最长回文字串与后缀树
那么后缀子串的trie与最长回文有什么关系呢?
S1=XMADAMYX反过来是S2=XYMADAMX,S1(4)=DAMYX,S2(5)=DAMX,他们的最长公共前缀是DAM,也就是最长回文子串的MADAM的半径.
于是,我们得到了解决最长回文子串的方法.
S1 和翻转 S2,生成的所有后缀子串压入到trie中,计算S1(i)与S2(n-i+1)节点的最低公共祖先,即其最长公共前缀,再得到最长回文子串.
如下图,用S1+’$’ 即翻转后的S2+’#’建立后缀树,得到如下的树.

根据我们上面的描述,我们现在的任务是计算S1(i)和S2(n-i+1)节点的最低公共祖先.如上图1$与8#,2$与7#...等的LCA,最后得出最长的.
LCA(最长公共前缀)
下面我们具体的说说LCA问题,即计算任意两个单词的最长公共前缀.
LCA(Lowest Common Ancestor: ):最低相同祖先,即树型结构中两个节点离root节点最近的公共祖先节点.如下图:

两个黄色节点的LCA为图中所示蓝色节点.
方法: Tarjan'sAlgorithm
Tarjan的方法,深度优先遍历树,用并查集的思想层级记录遍历过节点的祖先情况,具体看下图及代码:

代码:可见算法网站:http://www.csie.ntnu.edu.tw/~u91029/
#include<iostream>
using namespace std;
bool adj[9][9]; // adjacency matrix,数组存树
bool visit[9]; // 访问判断
int lca[9][9]; // 任意两点之间的LCA
int p[9];//并查集数组,表示其夫节点
int find(int x)
{
return x == p[x] ? x : (p[x] = find(p[x]));//find函数寻找某个节点的所属集合
}
void DFS(int x)
{
if (visit[x]) return;
visit[x] = true;
cout<<"P[]"<<endl;
for (int y=0; y<6; ++y)
{
cout<<p[y]<<' ';
}cout<<endl;
//计算LCA
for (int y=0; y<9; ++y)
if (visit[y])
lca[x][y] = lca[y][x] = find(y);
// DFS
for (int y=0; y<9; ++y)
if (adj[x][y])
{
DFS(y);
p[y] = x; // DFS回溯的时候,改变这个节点所属的集合,即把这个节点加入到更大的集合中.
}
}
void demo()
{
for (int i=0; i<9; ++i) p[i] = i;//预处理,所有的节点各自为一个并查集
for (int i=0; i<9; ++i) visit[i] = false;
DFS(0); // 假设树根为0
int x, y;
while (cin >> x >> y)
cout << x<<" and "<<y<<" LCA是 " <<lca[x][y]<<endl;
}
void buildtree()
{
adj[0][1]=1;
adj[1][2]=1;
adj[1][3]=1;
adj[0][4]=1;
adj[4][5]=1;
}
int main()
{
memset(adj,0,sizeof(adj));
buildtree();
demo();
return 0;
}通过上面的翻转,建树,计算LCA.我们最后得到了以每个字符为中心的最长回文.最后在统计得到总的最长回文.
上述插叙任意两个节点的LCA时间复杂度为O(N).但是我们传统的建树过程,时间复杂度应该是O(N^2).这样,如果是一般较少的查询,建树的时间复杂度会抵消插叙带来的遍历.
后来有人发明了时间复杂度为O(N)的建树方法-Ukkonen,我们就可以大胆地使用后缀树做各种用途了.有兴趣的可以继续深入研究
后缀树的其他用途
最后是后缀树的其他用途(直接拷贝)
(1).查找字符串o是否在字符串S中。
方案:用S构造后缀树,按在trie中搜索字串的方法搜索o即可。
原理:若o在S中,则o必然是S的某个后缀的前缀。
例如S: leconte,查找o: con是否在S中,则o(con)必然是S(leconte)的后缀之一conte的前缀.有了这个前提,采用trie搜索的方法就不难理解了。
(2). 指定字符串T在字符串S中的重复次数。
方案:用S+’$'构造后缀树,搜索T节点下的叶节点数目即为重复次数
原理:如果T在S中重复了两次,则S应有两个后缀以T为前缀,重复次数就自然统计出来了。
(3). 字符串S中的最长重复子串
方案:原理同2,具体做法就是找到最深的非叶节点。
这个深是指从root所经历过的字符个数,最深非叶节点所经历的字符串起来就是最长重复子串。
为什么要非叶节点呢?因为既然是要重复,当然叶节点个数要>=2。
(4). 两个字符串S1,S2的最长公共部分
方案:将S1#S2$作为字符串压入后缀树,找到最深的非叶节点,且该节点的叶节点既有#也有$(无#)。
推荐阅读:
http://blog.csdn.net/v_july_v/article/details/6897097
http://www.csie.ntnu.edu.tw/~u91029/














 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









