







一、前言
针对前面的wordcout的程序作一些解读
二、wordcount 运行过程
package hadoop.v3;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.hai.hdfs.utils.HDFSUtils;
/**
* hadoop 的 hello word
* @author : chenhaipeng
* @date : 2015年9月5日 下午8:38:13
*/
public class WordCount {
//Map
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output,
Reporter reporter) throws IOException{
String line = value.toString();
System.out.println("line---->"+line);
StringTokenizer tokenizer = new StringTokenizer(line);
while(tokenizer.hasMoreTokens()){
word.set(tokenizer.nextToken());
output.collect(word, one);
}
}
}
//reduce
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable>{
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,Reporter reporter)throws IOException{
int sum = 0;
while(values.hasNext()){
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void deletedir(String path){
try {
HDFSUtils.DeleteHDFSFile(path);
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("mywordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
deletedir(args[1]);
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
}
1、map类实现了
Mapper<LongWritable, Text, Text, IntWritable>接口,重写了void map(K1 key, V1 value, OutputCollector<K2, V2> output, Reporter reporter)方法 ,javadoc的解析如下
The Hadoop Map-Reduce framework spawns one map task for each InputSplit generated by theInputFormat for the job. Mapper implementations can access theJobConf for the job via the JobConfigurable.configure(JobConf) and initialize themselves. Similarly they can use theCloseable.close() method for de-initialization.
The framework then calls map(Object, Object, OutputCollector, Reporter) for each key/value pair in theInputSplit for that task.
意思就是说map方法通过inputFormat 子类生成map任务,并输出中间值key/value。
到这里我们有问题如下:
a)既然inputFormat 类可以决定map的数量,那么他是怎样控制map的数目
进入FileInputFormat类,getSplits源代码如下:
public InputSplit[] getSplits(JobConf job, int numSplits)
throws IOException {
FileStatus[] files = listStatus(job);
// Save the number of input files in the job-conf
job.setLong(NUM_INPUT_FILES, files.length);
long totalSize = 0; // compute total size
for (FileStatus file: files) { // check we have valid files
if (file.isDir()) {
throw new IOException("Not a file: "+ file.getPath());
}
totalSize += file.getLen();
}
long goalSize = totalSize / (numSplits == 0 ? 1 : numSplits);
long minSize = Math.max(job.getLong("mapred.min.split.size", 1),
minSplitSize);
// generate splits
ArrayList<FileSplit> splits = new ArrayList<FileSplit>(numSplits);
NetworkTopology clusterMap = new NetworkTopology();
for (FileStatus file: files) {
Path path = file.getPath();
FileSystem fs = path.getFileSystem(job);
long length = file.getLen();
BlockLocation[] blkLocations = fs.getFileBlockLocations(file, 0, length);
if ((length != 0) && isSplitable(fs, path)) {
long blockSize = file.getBlockSize();
long splitSize = computeSplitSize(goalSize, minSize, blockSize);
long bytesRemaining = length;
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {
String[] splitHosts = getSplitHosts(blkLocations,
length-bytesRemaining, splitSize, clusterMap);
splits.add(new FileSplit(path, length-bytesRemaining, splitSize,
splitHosts));
bytesRemaining -= splitSize;
}
if (bytesRemaining != 0) {
splits.add(new FileSplit(path, length-bytesRemaining, bytesRemaining,
blkLocations[blkLocations.length-1].getHosts()));
}
} else if (length != 0) {
String[] splitHosts = getSplitHosts(blkLocations,0,length,clusterMap);
splits.add(new FileSplit(path, 0, length, splitHosts));
} else {
//Create empty hosts array for zero length files
splits.add(new FileSplit(path, 0, length, new String[0]));
}
}
LOG.debug("Total # of splits: " + splits.size());
return splits.toArray(new FileSplit[splits.size()]);
}totalSize 就是文件总量
minisize 就是mapred.min.split.size 设置的大小 ,里面有个setMinSplitSize应该可以动态改变
numSplits 就是文件数量
blockSize 为文件系统默认大小64M
splitSize 计算方法如下:如果文件超过blockSize 就用blocksize,如果没有就是用文件本身
protected long computeSplitSize(long goalSize, long minSize,
long blockSize) {
return Math.max(minSize, Math.min(goalSize, blockSize));
}(double)file.getLen()/block>1.1 每次减少一个spliSize 来分块,所以map 的数量应该就是file.getLen()/block的数量了
b)继续这个类会使InputFormat 里面的getRecordReader得到实现
例如:TextInputFormat里面的getRecordReader
public RecordReader<LongWritable, Text> getRecordReader(
InputSplit genericSplit, JobConf job,
Reporter reporter)
throws IOException {
reporter.setStatus(genericSplit.toString());
return new LineRecordReader(job, (FileSplit) genericSplit);
}key 为行偏移量,value 为行值
OutputCollector 是什么呢?
键值对会被写到输出文件中,写入的方式由输出格式控制。OutputFormat的功能跟前面描述的InputFormat类很像,Hadoop提供的OutputFormat的实例会把文件写在本地磁盘或HDFS上,它们都是继承自公共的FileInputFormat类。
* The tokenizer uses the default delimiter set, which is
* <code>" \t\n\r\f"</code>: the space character,
StringTokenizer tokenizer = new StringTokenizer(line);
默认会用以上分隔符,所以整个map流程如下
输入 如:hello word-->(0,"hello word")-->(hello,1),(word,1)-->写到磁盘
我们查看一下hadoop 的帮助文档,印证我们的想法
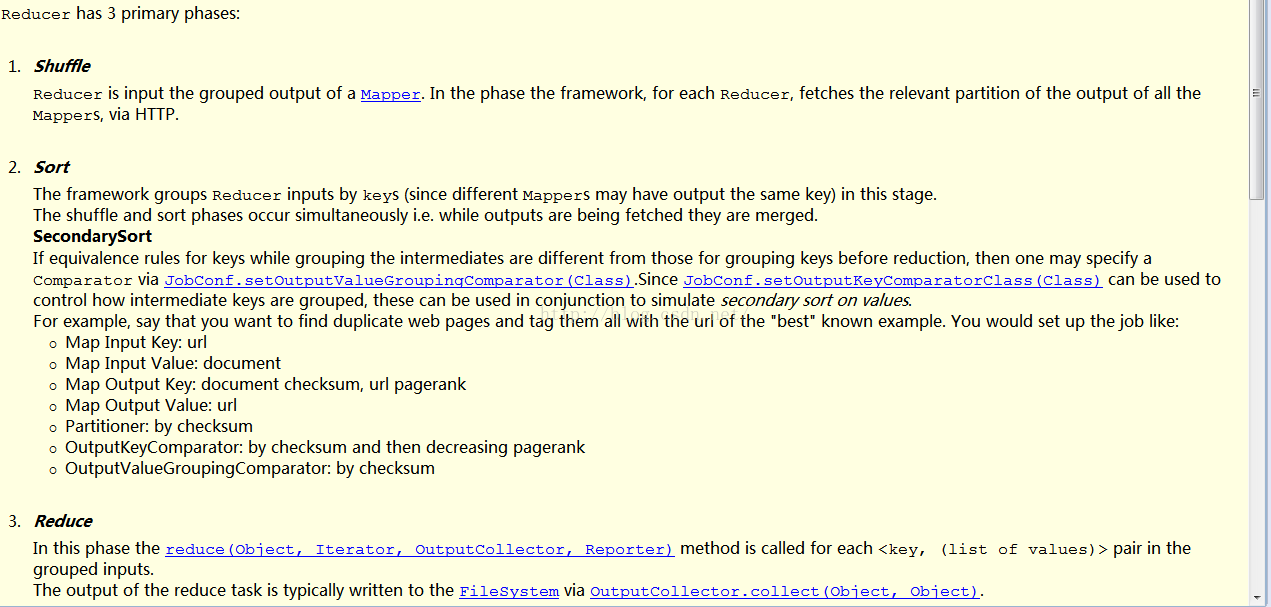
2、Reduce 类实现了Reducer
猜想:从代码上看wordcount代码上
public void reduce(Text key, Iterator<IntWritable> values,
OutputCollector<Text, IntWritable> output,Reporter reporter)throws IOException{
看map->reducer应该是做了一个排重合并的过程,将("hello",1),(“helo" 1)变成 了(“hello",2),
通过查看javadoc
最后:output再次写到磁盘
完~~~~~~~~~~~~~~~~~~















 6812
6812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









