






代码记录一下,嚯嚯嚯,0182被我提取出来啦
我们需要对这个图片验证码进行解析。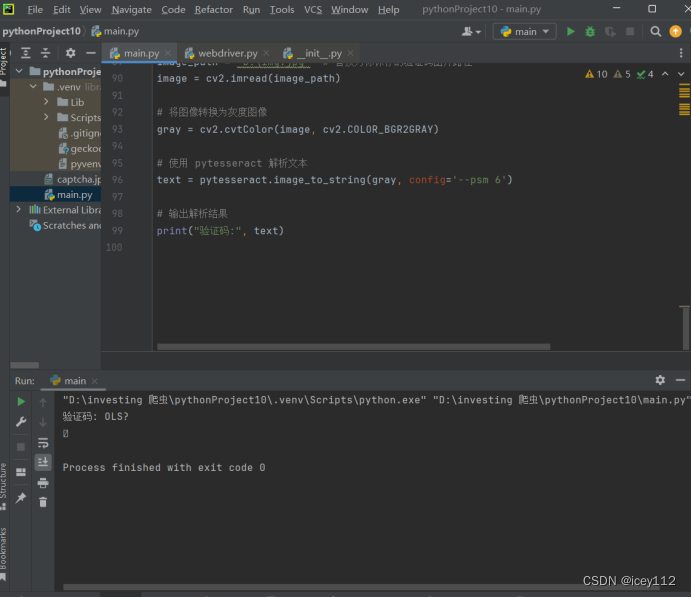
通过上图,我们可以发现,如果只是简单地进行灰度化处理,验证码地识别度并不和高,不能准确地识别出来。识别出来的是0LS?,与我们的0182还有很大的差距。因此,我们可以通过图片二值化、线性降噪或者利用 Tesseract 进行验证码识别,来提高验证码的识别准确度。
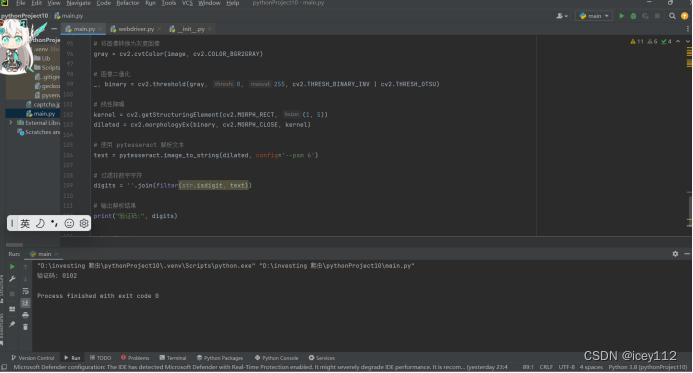
通过进一步的代码改进,验证码的识别有了很大的提高,识别出了0102,虽然正确的是0182,只有一个0和8的差距,但是我们仍然需要进一步地加强和改进代码。
通过代码的进一步改进,验证码被准确识别成0812!!成功啦!
def GrayImage(img):
'''
功能:图像灰度化
'''
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 转化为灰度图
return img
def Binarisation(img):
'''
将图片二值化
img:待处理的图像
阈值:其值对识别率影响巨大,可根据验证码图片的具体情况将 125 改为其他值
'''
_, img = cv2.threshold(img, 125, 255, cv2.THRESH_BINARY)
return img
def denoise_line(img, threshold):
'''
功能:线降
'''
h, w = img.shape[:2]
for y in range(1, w - 1): # 要去掉四条边线
for x in range(1, h - 1):
count = 0
if img[x, y - 1] > threshold:
count = count + 1
if img[x, y + 1] > threshold:
count = count + 1
if img[x - 1, y] > threshold:
count = count + 1
if img[x + 1, y] > threshold:
count = count + 1
if img[x - 1, y - 1] > threshold:
count = count + 1
if img[x - 1, y + 1] > threshold:
count = count + 1
if img[x + 1, y + 1] > threshold:
count = count + 1
if img[x + 1, y - 1] > threshold:
count = count + 1
if count >= 6:
img[x, y] = 255
return img
# 读取验证码图片
image_path = 'D:\img.jpg' # 替换为你保存的验证码图片路径
image = cv2.imread(image_path)
# 图像处理
gray = GrayImage(image)
binary = Binarisation(gray)
denoised = denoise_line(binary, 125)
# 使用 pytesseract 解析文本
text = pytesseract.image_to_string(denoised, config='--psm 6')
# 过滤非数字字符
digits = ''.join(filter(str.isdigit, text))
# 输出解析结果
print("验证码:", digits)

















 2472
2472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









