







 本文深入探讨了DB2数据库的查询优化过程,重点介绍了优化器的角色和工作原理,包括接收SQL语句、语法语义检查、查询重写、优化访问计划、生成可执行代码及执行访问计划等步骤。此外,还讲解了成本估算、过滤因子、统计信息和访问方式(如表扫描和索引扫描)在查询优化中的关键作用,强调了统计信息的及时更新对优化性能的重要性。
本文深入探讨了DB2数据库的查询优化过程,重点介绍了优化器的角色和工作原理,包括接收SQL语句、语法语义检查、查询重写、优化访问计划、生成可执行代码及执行访问计划等步骤。此外,还讲解了成本估算、过滤因子、统计信息和访问方式(如表扫描和索引扫描)在查询优化中的关键作用,强调了统计信息的及时更新对优化性能的重要性。
引言
我们知道,目前通用的数据库查询语言是SQL语言(Structured Query Language)。SQL语言也是一种编译型语言,需要SQL编译器编译后才能执行,但它与C、C++、Java等语言不同,SQL语言是一种非过程化语言,这意味着使用SQL进行操作的时候,你只需要指定你要达到什么目的,而无需指明要怎样达到目的。比如要查询EMPLOYEE的所有行,使用语句“Select * From EMPLOYEE”就行了,不需要规定该怎样查询这些行。
既然用户只需要解决“做什么”的问题,那么,“怎么做”的问题由谁来解决呢?这正是本文要讨论的问题。
优化器(Optimizer)
优化器
解决“怎么做”问题的工具就是“优化器”。优化器也称查询优化器(Query Optimizer)【注意这里的“查询”并不仅仅指Select操作,包括Select,Update,Delete,Insert等等在内的任何带WHERE条件子句的SQL操作都包含查询操作的】。它的主要工作是优化数据访问,根据提交的SQL语句,综合各种已有的信息(主要是系统编目表)来产生最优的可执行的访问方案。
优化器在整个数据库系统中占据着至高无上的地位,它是数据库性能的决定因素,是所有数据库引擎中最重要的组件。当前所有的数据库产品中,DB2的优化器是最强大的。这一点也是大多数拥有海量数据的企业选择DB2的主要原因。(事实上,70%以上的世界500强企业使用DB2作为主数据库)
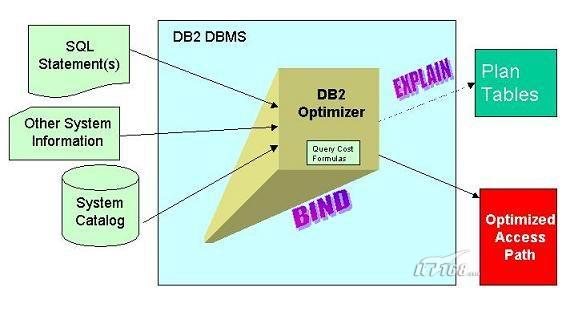
优化器的工作可以直观的理解为以下4个步骤:
1.接收并验证SQL语句的语法语义;
2.分析环境并优化满足SQL语句的方法;
3.创建计算机可读指令来执行优化的SQL;
4.执行指令或存储他们以便将来执行。
这其中的第2步是本文讨论的重点。至于优化器的其他内容,不介绍也不知道。
SQL语句执行过程
先来看看SQL语句的大致执行流程(SQL编译器是优化器的组成部分):
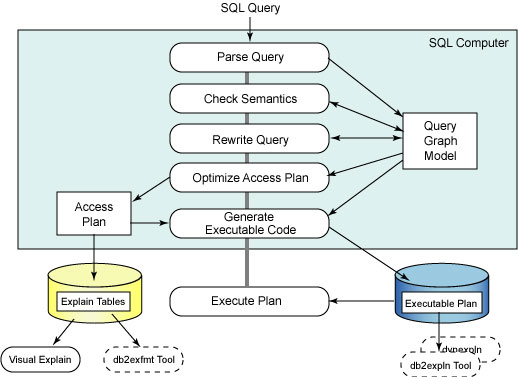
简述一下整个流程:
1.语法分析(Parse Query)
SQL语句被提交给SQL编译器,编译器分析该语句,检查其语法(Parse Query:语法分析),如果存在语法错误,编译器就停止处理并返回错误信息;如果不存在语法问题,编译器会将SQL语句转换为可被优化器分析的关系代数语句,并据此创建该查询的查询图模型(Query Graph Model,又称语法树)。
2.语义检查(Check Semantics)
语法分析完成后,编译器会根据查询图模型进行语义检查(比如检查语句中的数据类型是否与数据库的表列的数据类型一致),语义检查完成后也会将相关信息添加到查询图模型,包括参考约束,表检查约束,触发器,和视图信息等。
3.查询重写(Rewrite Query)
如果SQL语句的语法语义都没有问题,就可以正式进行查询操作了。这是优化器进行查询优化的开始阶段,DB2优化器三大组件之一的查询重写器(Query Rewriter)就是处理这一工作的。其目的是将提交的SQL语句优化成效率更高的形式,这种优化可以是基于查询成本的考虑,也可以是基于查询规则的考虑。举一个直观的例子:
考虑下面两条SQL语句(查询工龄为5年的员工及其所享有的年终奖级别):
Select EMPLOYEE.Name , WELFARE .Bonus From EMPLOYEE , WELFARE Where EMPLOYEE.Seniority > 5 And EMPLOYEE.Seniority = WELFARE .Seniority ;
Select EMPLOYEE.Name , WELFARE .Bonus From EMPLOYEE , WELFARE Where EMPLOYEE.Seniority > 5 And EMPLOYEE.Seniority = WELFARE .Seniority And EMPLOYEE.Seniority > 5;
很显然,两条语句的功能相同,第二条后面的“EMPLOYEE.Seniority = 5”条件还有点多余,那么,那条语句的执行效率更高?
答案是第二条!因为第一条将EMPLOYEE中Seniority>5的行与WELFARE中的所有行作外连接再来找Seniority相等的行,而第二条则是将EMPLOYEE中Seniority>5的行和WELFARE中Seniority>5的行作外连接再来找Seniority相等的行。显然,第二条语句只有更少的行参与外连接,效率自然更高。
可是,我们通常写出的查询语句都是第一条的形式,岂不是会影响效率?这就是查询重写的作用所在了,优化器的查询重写器能自动帮我们完成查询语句的优化,找到更高效的查询形式。当然了,查询重写并不是直接对SQL语句作上述例子那样的优化,它操作的是由语法分析转换过的关系代数语句,且需要根据重写图模型提供的信息作出形式优化。直观上是这么个意思而已。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1892
1892

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









