







背景
在OLAP环境下,数据的更新操作一般是通过定时调用ETL程序来定期将数据导入到内存仓库里面。这样带来的问题就是数据不是实时的,不够”新鲜“。
Hyper如何维持数据的新鲜
Hyper是一个同时支持OLTP和OLAP型的全内存数据库。
Hyper的设计目标:
- 能够在1s之内处理成百上千次的OLTP型的事务操作,达到像VoltDB或者TimesTen一样的处理效率。
- OLAP能够处理up-to-data的数据,达到像MonetDB或者是TREX一样的速率。
如果将OLAP和OLTP的操作在任务队列里面排队执行会出现什么问题:长时间的OLAP操作会阻塞OLTP操作的进行。而OLTP是短事务时间,需要能够具有实时处理的特点。
将OLAP和OLTP类型混合在一起处理,将不会满足OLTP实时性。Hyper的做法是依赖了目前系统中的COW技术(copy-on-write)。
如果一个父进程被fork,那么子进程并不会立即拷贝夫进程的物理内存,只有当父进程中的某个页面作了改变以后。子进程才真正将这部分的内存作拷贝。而且拷贝的单位是’以页面为单位’。如下图所示:
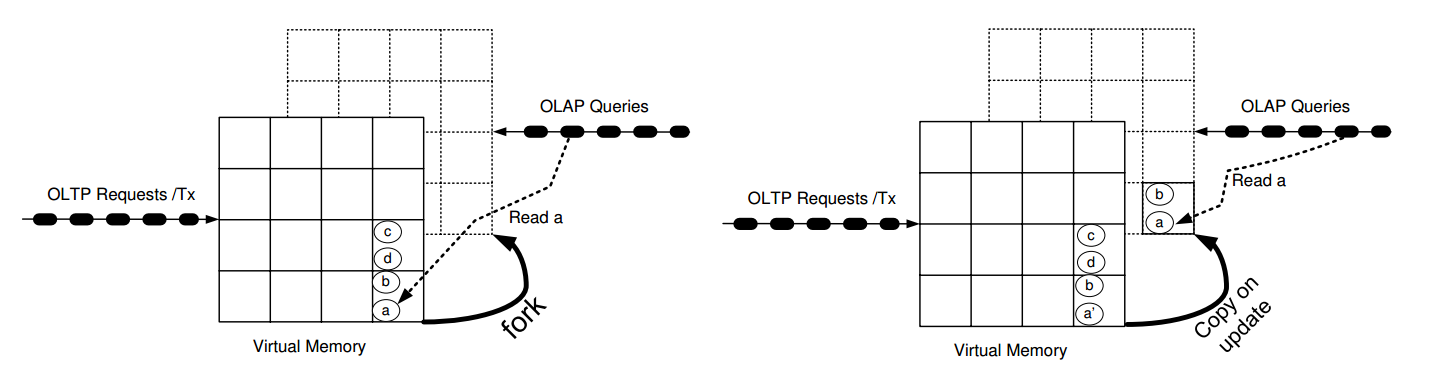
没有改变的页面的物理空间是不会被真正的拷贝的。
如果父进程被fork了多次,那么实际的内存情况如下:
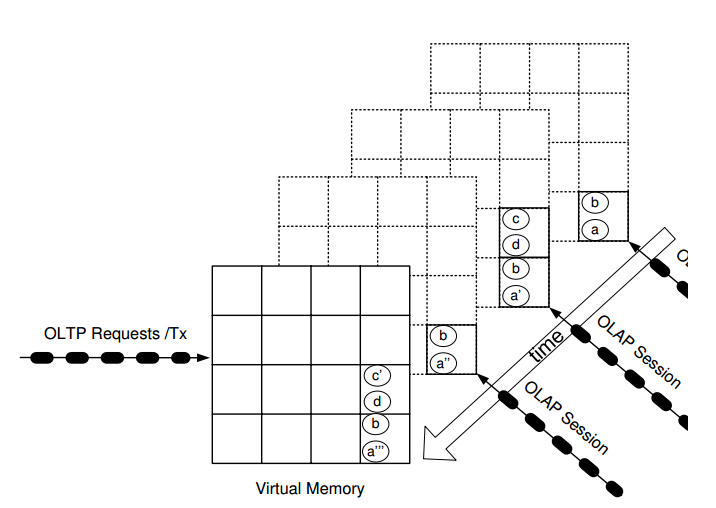
这样的话,如果需要处理OLAP的任务,需要在两个OLTP事务时间fork出一个子进程来处理OLAP的任务。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









