







SEQ2SQL:使用强化学习将自然语言转为结构化查询语句
基本信息
标题:SEQ2SQL: GENERATING STRUCTURED QUERIES FROM NATURAL LANGUAGE USING REINFORCEMENT LEARNING
会议:CoRR2017.
作者:Victor Zhong, Caiming Xiong, Richard Socher
链接:https://arxiv.org/abs/1709.00103
摘要
- 提出一个深层神经网络模型,用于生成sql:该模型生成一系列sql,在数据库中执行,以获得奖励,通过奖励来学习生成sql的策略
- 模型利用sql结构来减小生成sql的空间,是的生成问题更简单
- 发布了WikiSQL:有80654个样本,每个样本包含自然语言问题和人工标注的sql
- Seq2SQL的性能执行准确率从35.9%提高到59.4%,逻辑形式准确率从23.4%提高到48.3%
1 简介

图1:Seq2SQL接受一个问题和一个表的列作为输入。它生成相应的SQL查询,在训练期间,对数据库执行该查询。以执行结果作为奖励,训练强化学习算法。
图1所示的Seq2SQL由三个组件组成,它们利用SQL的结构来修剪生成查询的输出空间。此外,它使用基于策略的强化学习(RL)来生成查询条件,由于其无序性,不适合使用交叉熵损失进行优化。我们使用混合目标训练Seq2SQL,将交叉熵损失和在数据库上执行循环查询得到的RL回报结合起来。这些特性允许Seq2SQL在查询生成时获得最先进的结果。

图2:WikiSQL中的一个示例。输入由一个表和一个问题组成。输出包括一个基本的truth SQL查询和相应的执行结果。
2 模型
本文对比的基线模型:Dong&Lapata(2016)提出的注意力序列到序列神经语义解析器。该模型不依靠人工编写规则模板,是当前最先进模型。但它使用softmax作为输出,导致输出空间很大,这个是不需要的。而我们将生成序列的输出空间限制在 表头,问句,和sql关键词的并集。类似于AUGMENTED POINTER NETWORK(Vinyals et al.,2015)。
2.1 AUGMENTED POINTER NETWORK
输入
模型输入序列由下面串联而成:
- 表格的列名,用于生成select选择哪列,以及condition的左边变量
- 自然语言问题,用于生成condition的值,以及sql关键词,如count
设table有N列column
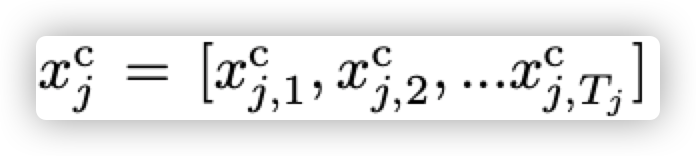
上式表示第j列共有Tj个字,
x
j
,
i
c
x^{c}_{j,i}
xj,ic代表第列的第i个字
x
q
x^{q}
xq代表自然语言问题的字序列
x
s
x^{s}
xs代表sql关键词集合
则模型输入x为三者的串联,如下:

x的编码器encoder
2层bi-lstm(a two-layer, bidirectional Long Short-Term Memory net-
work )(Hochreiter & Schmidhuber, 1997).
encoder将x编码为 h e n c h^{enc} henc和每个token对应的 h t e n c h^{enc}_{t} htenc
decoder
采用的pointer network (Vinyals et al. (2015) ):
那么Pointer Networks具体是怎样实现的呢?(参考博客)
我们首先来看传统注意力机制的公式:
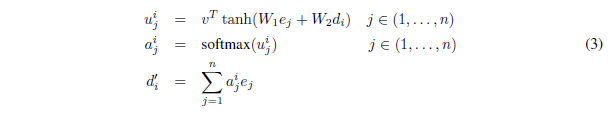
图3:传统注意力机制公式
其中是encoder的隐状态,而是decoder的隐状态,v,W1,W2都是可学习的参数,在得到之后对其执行softmax操作即得到。这里的就是分配给输入序列的权重,依据该权重求加权和,然后把得到的拼接(或者加和)到decoder的隐状态上,最后让decoder部分根据拼接后新的隐状态进行解码和预测。
根据传统的注意力机制,作者想到,所谓的正是针对输入序列的权重,完全可以把它拿出来作为指向输入序列的指针,在每次预测一个元素的时候找到输入序列中权重最大的那个元素不就好了嘛!于是作者就按照这个思路对传统注意力机制进行了修改和简化,公式变成了这个样子:
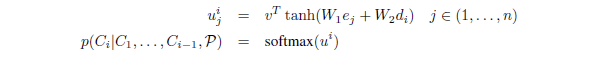
图4:Pointer Networks公式
第一个公式和之前没有区别,然后第二个公式则是说Pointer Networks直接将softmax之后得到的当成了输出,让承担指向输入序列特定元素的指针角色。
所以总结一下,传统的带有注意力机制的seq2seq模型的运行过程是这样的,先使用encoder部分对输入序列进行编码,然后对编码后的向量做attention,最后使用decoder部分对attention后的向量进行解码从而得到预测结果。但是作为Pointer Networks,得到预测结果的方式便是输出一个概率分布,也即所谓的指针。换句话说,传统带有注意力机制的seq2seq模型输出的是针对输出词汇表的一个概率分布,而Pointer Networks输出的则是针对输入文本序列的概率分布。
其实我们可以发现,因为输出元素来自输入元素的特点,Pointer Networks特别适合用来直接复制输入序列中的某些元素给输出序列。
本论文中的表示:


即通过注意力得分直接选取输入序列中最高注意力的token当做sql序列的当前输出
参考文献
博客:https://blog.csdn.net/weixin_40240670/article/details/86483896















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









