






提示:本文适合从零开始下载docker进行模型转换的小白,大佬可忽略,但也欢迎指正
文章目录
前言
我们在使用**maixcam(pro)**开发板时,由于官网训练限制3000张照片,以及仅限于训练yolov5模型的限制,在一些复杂情况需要增加照片数量或者更改模型(如yolov8,yolo11)时,就需要模型转换,把onnx模型转换成cvimodel。
提示:以下是本篇文章正文内容
一、下载docker
进入docker中文官网下载
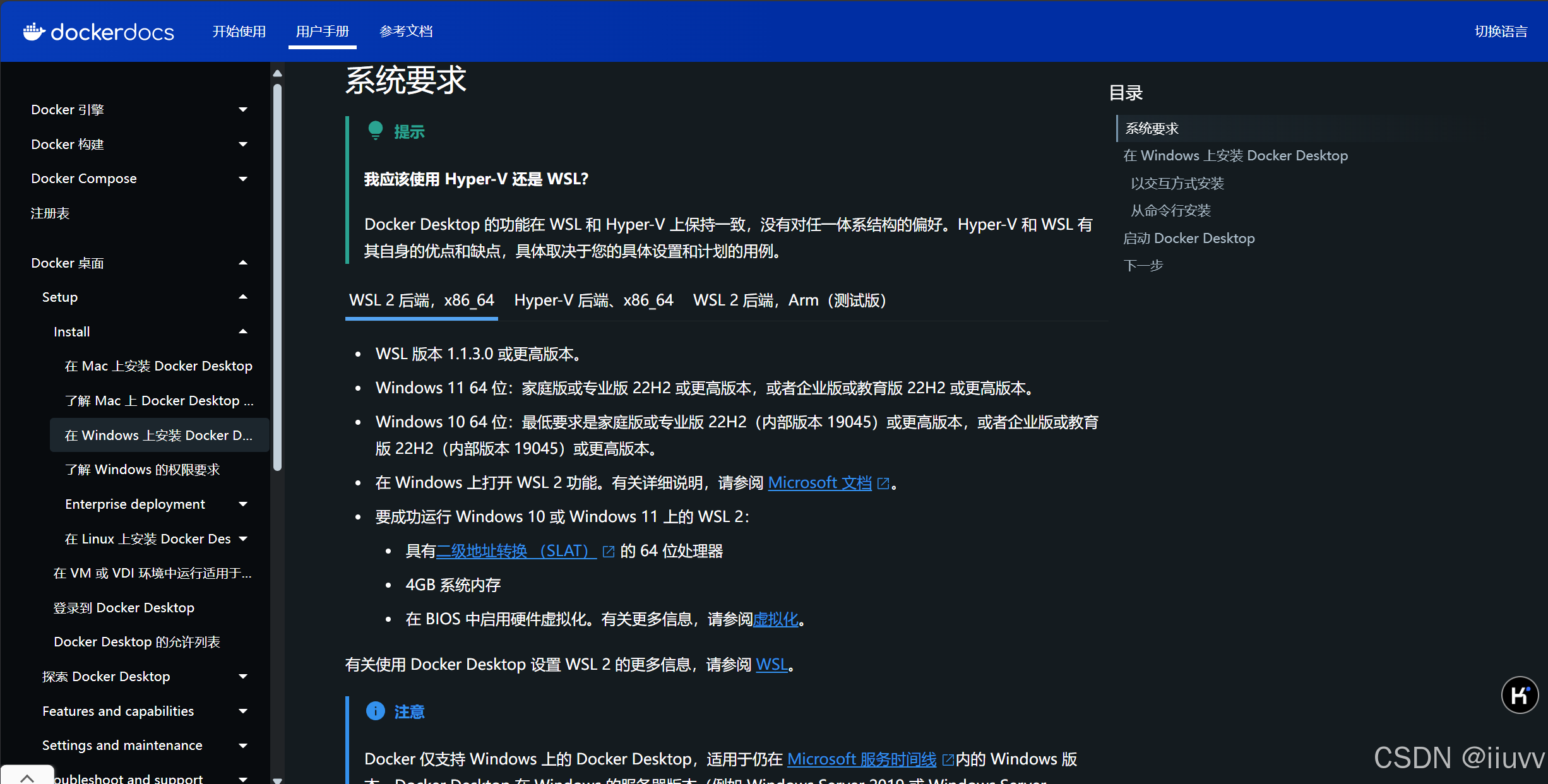
下载wsl的x86版本,这个是桌面版的,个人认为桌面版更直观,也更容易上手。
这个网站的教程也很详细,跟着上面的步骤一步一步做就好。
二、大概了解docker
1.名词概述
1.镜像:指对一个软件、数据存储设备或网络服务的完全复制,用于备份、分发或提供高可用性,这个概念比较熟悉。
2.容器:镜像的运行需要系统作为载体,在docker中,可以理解容器(Container)就是这个载体。
3.挂载:指将容器中的文件放到自己的电脑中储存,但是我的本地挂载一直没有成功,不过这个不耽误转换模型。
4.本文只做简单概述,这里有网站仔细解释dockers(入门级)。
2.docker desktop使用简介
1.命令行
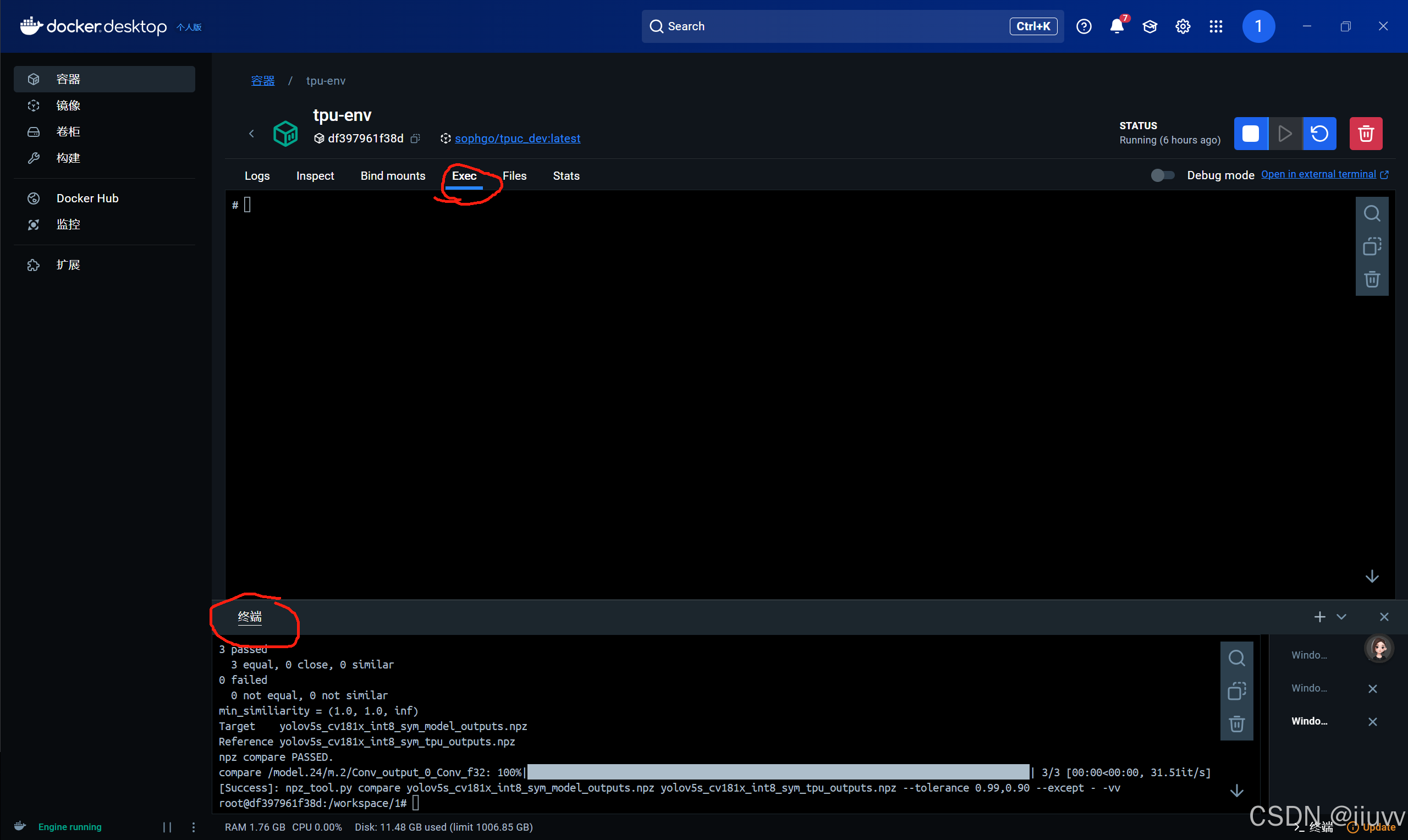
上面的是容器内的命令行,下面的是自己电脑的PowerShell。
2.文件系统与编辑
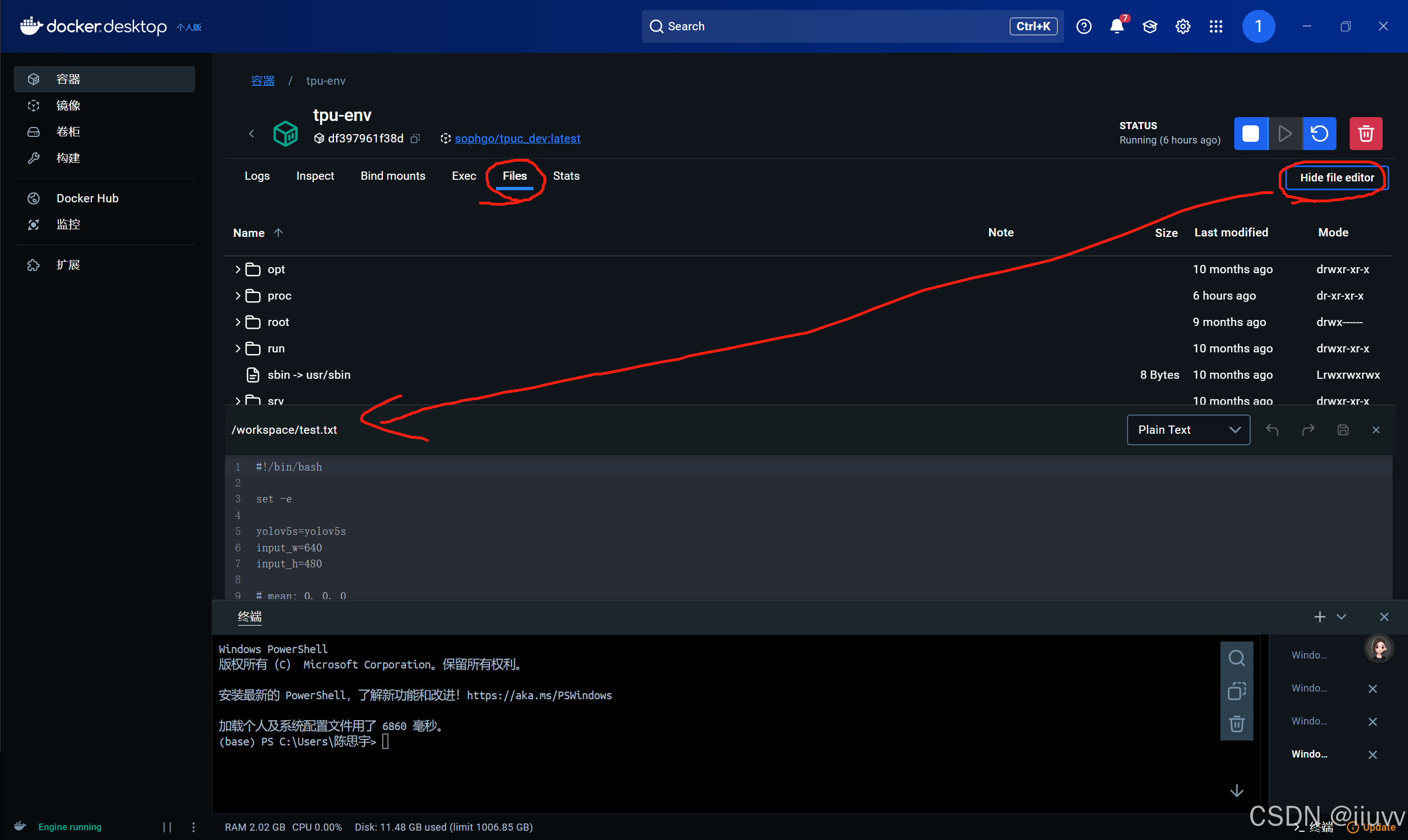
File是容器的文件系统,可以点击hide/open file editor来查看并且编辑文件内容(编辑后千万别忘了保存)。
注:建议从下面的PowerShell进入docker并运行容器,然后在上面编辑文件,因为来回切换Exec和File很麻烦。
3.文件上传与下载
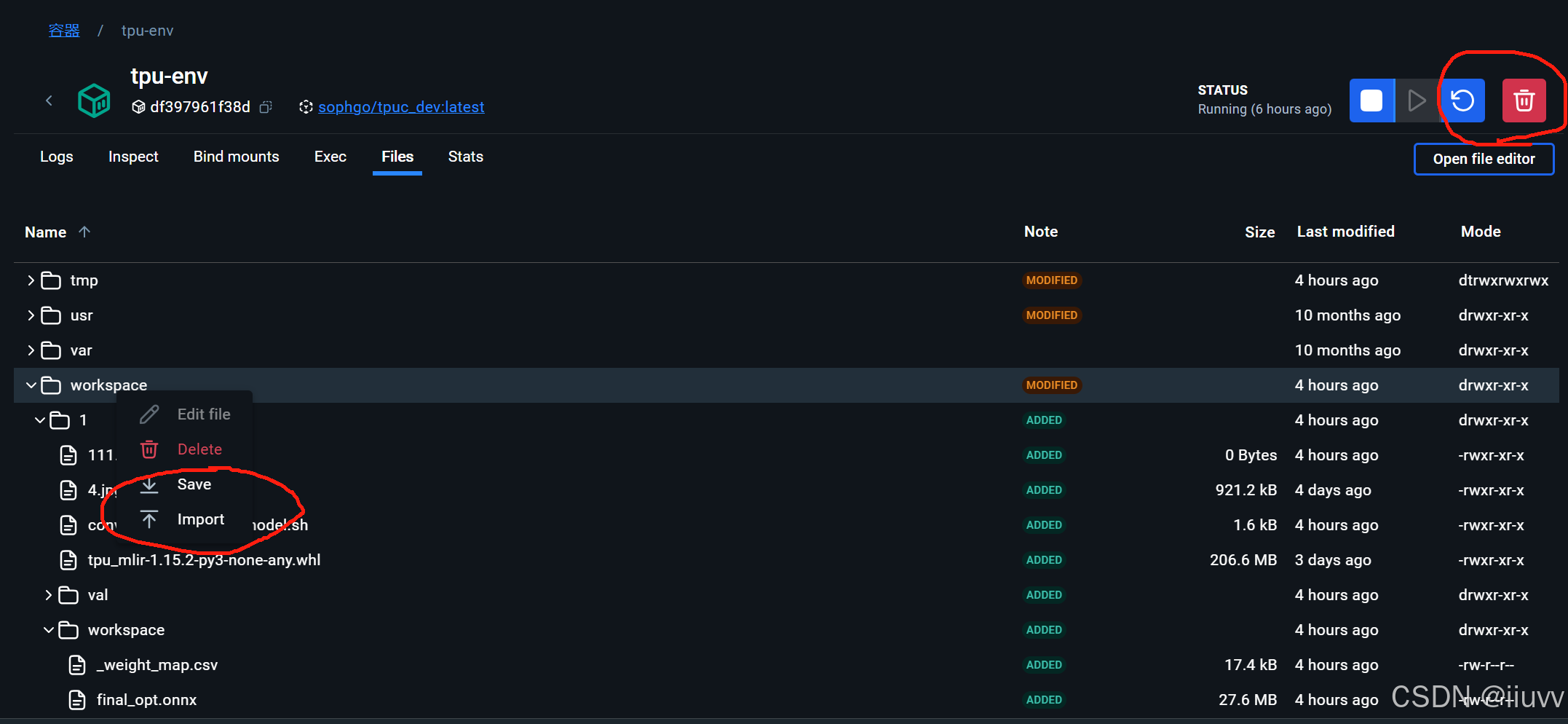
右键点击文件,可以上传/下载,上传是由电脑上传(但只能上传文件夹,建议编辑好文件夹内容后一并上传),下载是下载到电脑。
4.命令操作
Markdown将文本转换为 HTML。网站里有很多docker命令的汇总
三、模型转换
拉取 docker 镜像
docker pull sophgo/tpuc_dev:latest
如果docker拉取失败,可以通过以下方式进行下载:
wget https://sophon-file.sophon.cn/sophon-prod-s3/drive/24/06/14/12/sophgo-tpuc_dev-v3.2_191a433358ad.tar.gz
docker load -i sophgo-tpuc_dev-v3.2_191a433358ad.tar.gz
这个方法参考tpu-mlir官方docker环境配置。
此外你也可以设置国内的镜像,可自行搜索或者参考docker 设置代理,以及国内加速镜像设置。
运行容器
docker run --privileged --name tpu-env -v /home/$USER/data:/home/$USER/data -it sophgo/tpuc_dev
这就起了一个容器,名叫tpu-env,并且把本机的~/data目录挂载到了容器的~/data,这样就实现了文件共享,并且和宿主机路径一致。
下次启动容器用
docker start tpu-env && docker attach tpu-env
即可。
安装 tpu-mlir
先到github下载 whl 文件,放到~/data目录下。
在容器中执行命令安装:
pip install tpu_mlir-1.15.2-py3-none-any.whl # 这里就是下载文件的名字
在容器内直接输入model_transform.py回车执行会有打印帮助信息就算是安装成功了。
model_transform.py
编写转换脚本
转换模型主要就两个命令,model_transform.py 和 model_deploy.py,主要麻烦的是参数,所以我们写一个脚本convert_yolov5_to_cvimodel.sh存下来方便修改。
#!/bin/bash
set -e
yolov5s=yolov5s
input_w=640
input_h=480
# mean: 0, 0, 0
# std: 255, 255, 255
# mean
# 1/std
# mean: 0, 0, 0
# scale: 0.00392156862745098, 0.00392156862745098, 0.00392156862745098
mkdir -p workspace
cd workspace
# convert to mlir
model_transform.py \
--model_name ${yolov5s} \
--model_def ../${yolov5s}.onnx \
--input_shapes [[1,3,${input_h},${input_w}]] \
--mean "0,0,0" \
--scale "0.00392156862745098,0.00392156862745098,0.00392156862745098" \
--keep_aspect_ratio \
--pixel_format rgb \
--channel_format nchw \
--output_names "/model.24/m.0/Conv_output_0,/model.24/m.1/Conv_output_0,/model.24/m.2/Conv_output_0" \
--test_input ../4.jpg \
--test_result ${yolov5s}_top_outputs.npz \
--tolerance 0.99,0.99 \
--mlir ${yolov5s}.mlir
# export bf16 model
# not use --quant_input, use float32 for easy coding
model_deploy.py \
--mlir ${yolov5s}.mlir \
--quantize BF16 \
--processor cv181x \
--test_input ${yolov5s}_in_f32.npz \
--test_reference ${yolov5s}_top_outputs.npz \
--model ${yolov5s}_bf16.cvimodel
echo "calibrate for int8 model"
# export int8 model
run_calibration.py ${yolov5s}.mlir \
--dataset ../images \
--input_num 6 \
-o ${yolov5s}_cali_table
echo "convert to int8 model"
# export int8 model
# add --quant_input, use int8 for faster processing in maix.nn.NN.forward_image
model_deploy.py \
--mlir ${yolov5s}.mlir \
--quantize INT8 \
--quant_input \
--calibration_table ${yolov5s}_cali_table \
--processor cv181x \
--test_input ${yolov5s}_in_f32.npz \
--test_reference ${yolov5s}_top_outputs.npz \
--tolerance 0.9,0.6 \
--model ${yolov5s}_int8.cvimodel
可以看到,这里有几个比较重要的参数:
output_names就是我们前面说到的输出节点的输出名。mean, scale就是训练时使用的预处理方法,比如YOLOv5官方代码的预处理是把图像 RGB 3个通道分别-mean再除以std,并且默认mean
为0,std为255,即将图像的值归一,这里scale就是1/std。你的模型需要根据实际的预处理方法修改。test_input就是转换时用来测试的图像,这里是../4.jpg,所以实际模型转换时我们需要在此脚本所在同目录放一张4.jpg的图,你的模型根据你的实际情况替换图像。tolerance就是量化前后允许的误差,如果转换模型时报错提示值小于设置的这个值,说明转出来的模型可能相比 onnx 模型误差较大,如果你能够容忍,可以适当调小这个阈值让模型转换通过,不过大多数时候都是因为模型结构导致的,需要优化模型,以及仔细看后处理,把能去除的后处理去除了。quantize即量化的数据类型,在 MaixCAM 上我们一般用 INT8 模型,这里我们虽然也顺便转换了一个 BF16 模型,BF16 模型的好处时精度高,不过运行速率比较慢,能转成 INT8 就推荐先用 INT8,实在不能转换的或者精度要求高速度要求不高的再考虑 BF16。dataset表示用来量化的数据集,也是放在转换脚本同目录下,比如这里是val文件夹,里面放数据即可,对于 YOLOv5 来说就是图片,从 coco 数据集中复制一部分典型场景的图片过来即可。 用--input_num可以指定实际使用图片的数量(小于等于 images 目录下实际的图片)。
整理准换模型所需文件夹
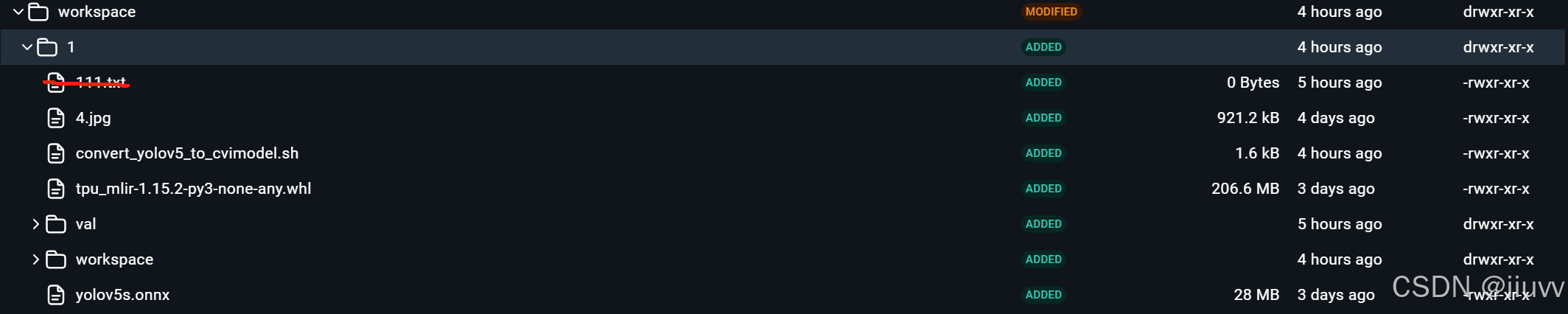
该workspace文件夹中workspace文件夹是模型转换后生成的,其余的文件和文件夹都需要自己添加。
其中:
4.jpg 文件是要识别的照片
convert_yolov5_to_cvimodel.sh 是上面需要编辑的转换脚本
tpu_mlir-1.15.2-py3-none-any.whl是上面安装过的库文件,也建议一并放到这个文件夹中
val是数据集
yolov5.onnx就是最不可或缺的模型文件
执行转换脚本
直接执行chmod +x convert_yolov5_to_cvimodel.sh && ./convert_yolov5_to_cvimodel.sh 等待转换完成。
chmod +x convert_yolov5_to_cvimodel.sh && ./convert_yolov5_to_cvimodel.sh
如果出错了,请仔细看上一步的说明,是不是参数有问题,或者输出层选择得不合理等。
然后就能在workspace文件夹下看到有**_int8.cvimodel 文件了。
但实际上我看见的是很多模型文件,可以在里面翻找出.cvimodel文件。
MUD文件是什么?
MUD(模型统一描述文件, model universal description file)是 MaixPy 支持的一种模型描述文件,用来统一不同平台的模型文件,方便 MaixPy 代码跨平台,本身是一个 ini格式的文本文件,可以使用文本编辑器编辑。
一般 MUD 文件会伴随一个或者多个实际的模型文件,比如对于 MaixCAM, 实际的模型文件是.cvimodel格式, MUD 文件则是对它做了一些描述说明。
这里以 YOLOv8 模型文件举例,一共两个文件yolov8n.mud和yolov8n.cvimodel,前者内容:
[basic]
type = cvimodel
model = yolov8n.cvimodel
[extra]
model_type = yolov8
input_type = rgb
mean = 0, 0, 0
scale = 0.00392156862745098, 0.00392156862745098, 0.00392156862745098
labels = person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, couch, potted plant, bed, dining table, toilet, tv, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush
可以看到, 指定了模型类别为cvimodel, 模型路径为相对mud文件的路径下的yolov8n.cvimodel文件;
以及一些需要用到的信息,比如预处理mean和scale,这里需要和训练的时候对模型输入的数据的预处理方法一致,labels则是检测对象的 80 种分类。
实际用这个模型的时候将两个文件放在同一个目录下即可。
编写mud文件
根据你的模型情况修改mud文件,对于 YOLOv5 就如下,修改成你训练的labels就好了。
[basic]
type = cvimodel
model = yolov5s.cvimodel
[extra]
model_type = yolov5
input_type = rgb
mean = 0, 0, 0
scale = 0.00392156862745098, 0.00392156862745098, 0.00392156862745098
anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
labels = person, bicycle, car, motorcycle, airplane, bus, train, truck, boat, traffic light, fire hydrant, stop sign, parking meter, bench, bird, cat, dog, horse, sheep, cow, elephant, bear, zebra, giraffe, backpack, umbrella, handbag, tie, suitcase, frisbee, skis, snowboard, sports ball, kite, baseball bat, baseball glove, skateboard, surfboard, tennis racket, bottle, wine glass, cup, fork, knife, spoon, bowl, banana, apple, sandwich, orange, broccoli, carrot, hot dog, pizza, donut, cake, chair, couch, potted plant, bed, dining table, toilet, tv, laptop, mouse, remote, keyboard, cell phone, microwave, oven, toaster, sink, refrigerator, book, clock, vase, scissors, teddy bear, hair drier, toothbrush
这里basic部分指定了模型文件类别和模型文件路径,是必要的参数,有了这个参数就能用MaixPy或者MaixCDK中的maix.nn.NN类来加载并运行模型了。
extra则根据不同模型的需求设计不同参数。
比如这里对YOLOv5设计了这些参数,主要是 预处理、后处理、标签等参数。
对于 MaixPy 已经支持了的模型可以直接下载其模型复制修改。
也可以看具体的代码,比如YOLOv5 的源码,可以看到源码使用了哪些参数。
比如你用YOLOv5训练了检测数字0~9的模型,那么需要将labels改成0,1,2,3,4,5,6,7,8,9,其它参数如果你没改训练代码保持即可。
如果你需要移植 MaixPy 没有支持的模型,则可以根据模型的预处理和后处理情况定义 extra, 然后编写对应的解码类。如果你不想用C++修改 MaixPy 源码,你也可以用MaixPy 的maix.nn.NN类加载模型,然后用 forward 或者 forward_image 方法或者原始输出,在 Python 层面写后处理也可以,只是运行效率比较低不太推荐。
总结
虽然maixcam是一款及其方便好用且强大的智能视觉开发板,但是在执行这个模型转换时,并不是像使用maixcam本身一样容易上手。
所以,以好的环境为基础,高度集成化的开发板固然好用,但也不要一直停滞在应用层面,了解底层,多多收纳思路,集思广益,才能让我们的技术足以媲美开发板的完美。


















 1223
1223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









